
Luka Mrkić
Head of BD
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 1, 2026
Claude for Competitor Analysis to Positioning Copy
TL;DR
- Positioning copy starts losing the moment it is written without competitor evidence in front of it. The fix is a workflow that puts every competitor’s claims, prices, reviews, and gaps on the table before Claude drafts a line.
- The workflow is five steps: collect competitor and internal inputs, structure them with Claude into tagged claims, contrast to find the gaps and overlaps, draft three positioning angles tied to real gaps, then score and test those angles against your own transcripts and pages.
- Claude is the structuring and drafting layer. The collection step and the test step stay with the human team because they involve sales transcripts, real prospects, and a real homepage.
- The cheapest useful version runs on five competitor homepages, five pricing pages, 25 to 50 review snippets, and 8 to 12 sales transcripts. A first round of three positioning angles ships in a few hours of model time plus a half day of human review.
- The article ships with the workflow diagram, the inputs to collect, the Claude prompt that actually produces defensible angles, and the six checks that tell you the copy is ready for a page test.
If you are evaluating who should build this for your team, this guide gives you both the technical blueprint and the standards to evaluate the work.
What this workflow actually does
Most positioning workshops produce copy by argument. The team gets in a room, debates three candidate headlines, picks one by consensus or by the loudest voice, and ships it. The copy then sits on a homepage and gets graded by traffic that arrives weeks later. By then the team has moved on and nobody traces the result back to the headline.
The Claude workflow inverts that. It pulls in the public evidence (homepages, pricing pages, public reviews) and the private evidence (sales transcripts, win and loss notes, your own current copy) and runs them through a structured prompt that tags claims, clusters them, surfaces overlaps and gaps, and only then drafts copy. Every angle that comes out of the workflow is tied to a specific gap with a specific source line behind it. The team is no longer arguing about taste; they are choosing between angles that each have a paper trail.
The output is not a final homepage. It is three or four positioning angles, each with a draft headline, a draft subhead, a proof line, and the source quotes that support it. The team picks the one to test, the page test happens, and the next round of the workflow uses the test data as another input.
The workflow
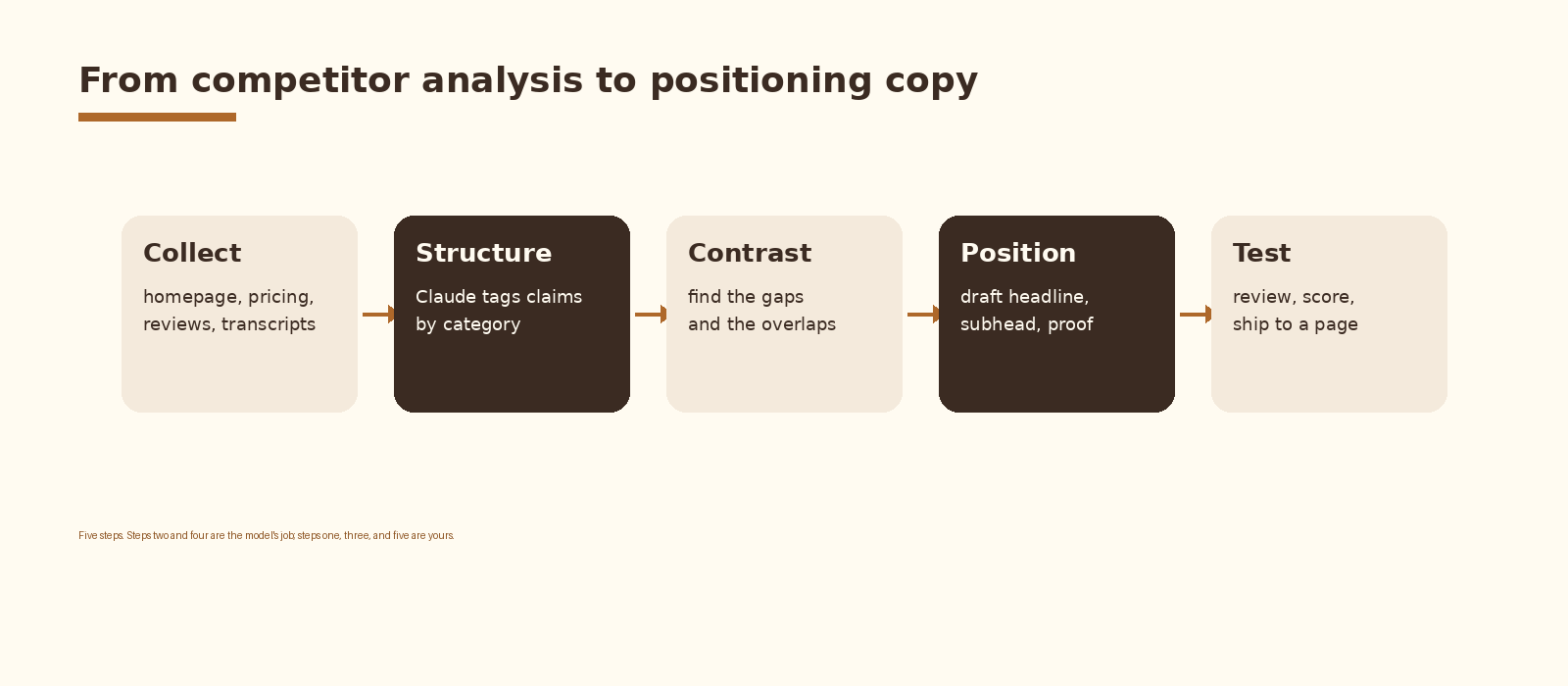
Five steps. Collect the inputs. Structure them with Claude. Contrast to find the gaps. Draft positioning angles. Score and test. The model does the heavy lifting in steps two and four; the human team owns steps one, three, and five. The split matters because positioning copy that the team did not co-author rarely survives the first sales call.
Step 1. Collect the inputs

Six categories. Aim for five competitors in the first pass. More than that and the model loses signal in the tagging step; fewer and the contrast step has nothing to push against.
- Homepages. Save the hero, the subhead, the primary CTA, and the first three scrollable sections of each competitor. Markdown is fine; screenshots are not needed at this stage.
- Pricing pages. Save the tier names, the anchor prices, the named features per tier, the free trial or free plan terms, and any annual discount language.
- Review snippets. Pull five to ten of the highest signal G2 or Capterra quotes per competitor. Prefer reviews that describe the buying decision, the use case, or a complaint.
- Sales transcripts. Eight to twelve discovery calls from the last quarter. Strip personally identifying customer information before they reach the model. The lines you want are the buyer’s own words.
- Win and loss notes. Whatever the reps wrote in HubSpot or Salesforce when a deal closed or died. Short notes are fine; the model reads them as signal anyway.
- Your own copy. Current homepage and pricing page. The workflow only works if your own claims sit on the table next to the competitor claims.
inputs/
competitors/
acme/homepage.md
acme/pricing.md
acme/reviews.md
beta/...
internal/
transcripts/
2026-05-call-01.md
...
win-loss/
2026-q2.csv
own/
homepage.md
pricing.mdStep 2. Structure the claims with Claude
The first model pass turns the raw inputs into a tagged claim table. For every source file, Claude reads the text and emits a list of claims, each with a category, a strength score, and the source citation. Categories are tight: outcome promise, audience, mechanism, proof, price anchor, integration, deprecation jab, and other. Strength is the model’s read on how loud the claim is on the page, scored one to five.
# claim_tagger.py
import json, os, anthropic
client = anthropic.Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"])
SYSTEM = '''You extract positioning claims from a marketing page or transcript.
Categories: outcome, audience, mechanism, proof, price_anchor, integration, jab, other.
For each distinct claim return JSON:
- text: the exact claim line, max 25 words
- category: one of the categories above
- strength: integer 1 to 5 (1=buried, 5=hero line)
- source_quote: the line from the source that the claim came from
Return a JSON array of claim objects. Skip filler, legal, and nav copy.'''
def tag(source_id: str, body: str) -> list[dict]:
msg = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=2000,
system=SYSTEM,
messages=[{"role": "user",
"content": f"SOURCE: {source_id}\n\n{body}"}],
)
text = msg.content[0].text
arr = json.loads(text[text.find('['):text.rfind(']')+1])
for c in arr:
c["source"] = source_id
return arrRun the tagger over every source file in the inputs folder. The result is a single flat list of tagged claims, typically 300 to 800 rows for a five-competitor pass. Save it as a CSV; it is the dataset every later step reads from.
Step 3. Contrast to find gaps and overlaps
This is where the human team earns its keep. With the claim table open, you are looking for three things. Overlaps: claims that three or more competitors make at hero strength. These are the table stakes; copying them gives you nothing. Saturations: outcome promises that are present on every page in the set, which means the buyer hears them as background noise. Gaps: categories where the strong claims are sparse, or where your reviews and transcripts say something the competitors do not.
You can ask Claude for a first pass on overlaps and gaps in one call. Send it the claim table grouped by competitor and ask for an overlap report. Then read the report by hand. The model finds the obvious overlaps fast; the team finds the gaps that actually matter because they remember the calls.
# overlap_report prompt fragment
system: |
You read a claim table grouped by vendor.
Return JSON with two arrays:
overlaps: claims made at strength >= 4 by 3+ vendors
gaps: claim categories where no vendor has any
claim at strength >= 3, or where our reviews
and transcripts contain a strong claim that
no competitor matches.
For every gap, include the source_quote that proves
the gap is real.Step 4. Draft positioning angles

Three angles per round is the right number. Two leaves the team picking between A and B and they always pick the safer one. Four spreads the team’s attention. Three forces a real choice.
The drafting prompt is where weak vs strong matters most. A weak prompt asks Claude to write a headline. A strong prompt walks the model through the workflow it just read: tag the inputs, list the overlaps, list the gaps, pick the three gaps with the best proof, draft one angle per gap, and tie each angle to the source lines that justify it. The output is structured JSON the team can score directly.
# positioning_draft.py
SYSTEM = '''You draft three positioning angles for a B2B SaaS company.
Inputs you receive:
- a claim table grouped by competitor
- our review snippets and transcripts
- our current homepage copy
Workflow:
1. Identify 3 gaps where competitors are weak and our evidence is strong.
2. For each gap, draft one positioning angle as JSON with:
- angle_name: 2 to 4 words
- headline: max 12 words, names a specific outcome or mechanism
- subhead: max 25 words, names the audience and the proof
- proof_line: 1 sentence, names a customer, a number, or a workflow
- source_quotes: 3 to 5 lines from the inputs supporting the angle
- risk: 1 sentence on what could make this angle wrong
Return strict JSON: an array of 3 angle objects.'''If you want this set up cleanly inside your stack with logging, retries, and a feedback loop into a CRM, that is the kind of work we ship at Espressio.
Step 5. Score and test

The angles come out of step four with proof attached. Before any of them go near a homepage, score them against the six checks in the table above. Specificity, buyer job fit, named proof, differentiation, sales read, and testability. Any angle that fails two or more checks goes back into a redraft round with the model. Any angle that passes all six is a candidate for a page test.
The page test itself is the only true ranking step. A workshop vote is a guess; a homepage A B with real traffic is a result. Plan the test before the meeting that picks the angle, otherwise the team will ship the favored angle without a counterfactual and you will be back here in six months.
Common mistakes
- Skipping the input collection. A model that has not read the competitor pricing pages and your own transcripts can only generate slogans.
- Letting the model draft headlines in one shot. Without the tag, cluster, contrast steps in front, the output reads like every other generic AI marketing draft.
- Picking the angle in the room. The pick happens after the page test. The room picks which angle to test first.
- No proof line. An angle without a named customer, number, or workflow is unverifiable and the sales team cannot defend it on a call.
- Reading only competitor pages and skipping reviews. The reviews are where the buyer’s language lives; your headline should sound like your reviewers.
- Treating one round as the answer. Positioning is a loop. Run the workflow quarterly; the inputs shift faster than annual cycles assume.
How to know it is working
Three signals tell you the workflow is paying back. First, the homepage test you ran against the current copy lifts a top of funnel metric (signups, demo requests, trial starts) by an amount you can defend statistically. Second, the sales team uses the new headline language in cold calls and on first calls without being asked to. Third, the next round of the workflow takes less time because the inputs folder is already up to date and the tagger prompt is already tuned. If any of the three drift, the angle is wrong or the test was underpowered; redraft before you replatform.
FAQ
Which Claude model should I use for this?
Sonnet handles both the tagging step and the drafting step well at a reasonable price. Opus produces marginally tighter drafts on the final step and can be worth it on the angle generation pass if the team is going to ship to a page. Haiku is too inconsistent on the JSON contract for the tagger and should be avoided for this workflow.
How is this different from running a positioning workshop?
A workshop produces angles from the team’s intuition. This workflow produces angles from the evidence in front of the team. The two combine well. Run the workflow first, then hold a workshop to pick which angle to test. The workshop now argues from the proof lines.
Do I need a separate vector database or RAG layer for the inputs?
No. The inputs are small enough that they fit inside a single Claude context window. For five competitors and a dozen transcripts you are looking at well under a million tokens. Keep the inputs as flat files until the dataset gets large enough that retrieval matters; for almost every team it never does.
How often should I rerun the workflow?
Quarterly is the default. Run a fresh pass when your top three competitors ship a major homepage refresh, when your own pricing changes, when you raise a round, or when the win and loss notes show a new objection three deals in a row.
Can the workflow replace a positioning consultant?
It replaces the input gathering and the first draft, which is where most of the consultant’s billable hours go. It leaves the judgment call on which angle to test and the conversations with the sales team to the humans who own the outcome. The right framing is that the workflow is the consultant’s research assistant.
What to do next
- Pick five competitors and stand up the inputs folder structure. Save homepages, pricing pages, and review snippets first.
- Pull eight to twelve sanitized sales transcripts and any win and loss notes from the last quarter.
- Run the claim tagger over every file. Save the resulting claim table as a CSV.
- Run the overlap and gap pass with Claude, then read the report by hand.
- Draft three positioning angles with the strong prompt. Score each against the six checks.
- Pick one angle and plan the homepage test before the meeting that approves it.
If you want positioning work like this set up cleanly inside your marketing operations, let’s talk.

