
Luka Mrkić
Head of BD
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 9, 2026
How to Use AI to Market Developer Tools and APIs in 2026
TL;DR
- Marketing developer tools and APIs with AI works when the engine writes from real engineer questions, ships tested code, and routes every public page through a DX engineer.
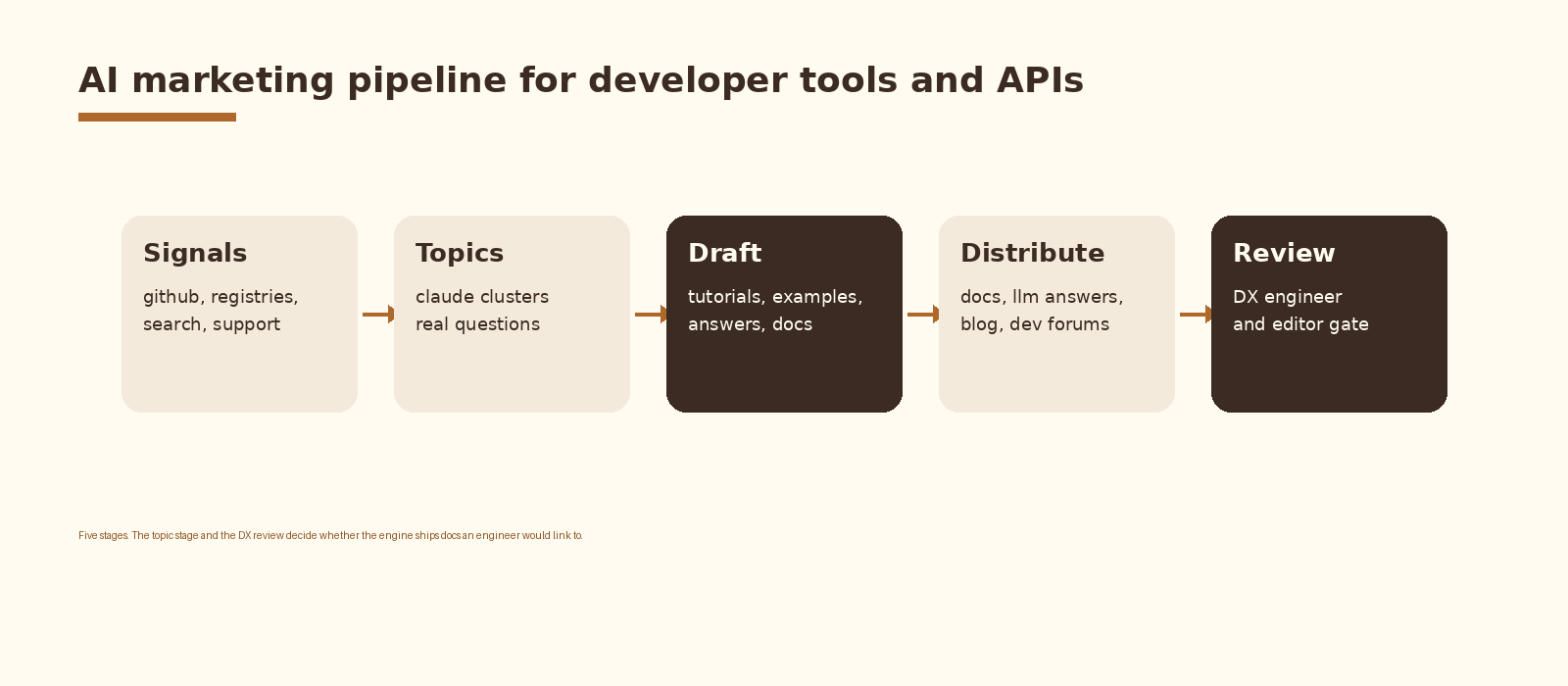
- The pipeline is five stages: signals, topics, draft, distribute, review. The topic stage and the DX review are where the engine earns trust.
- Pick two surfaces and ship them end to end. Quickstarts plus recipe pages is the strongest opening pair.
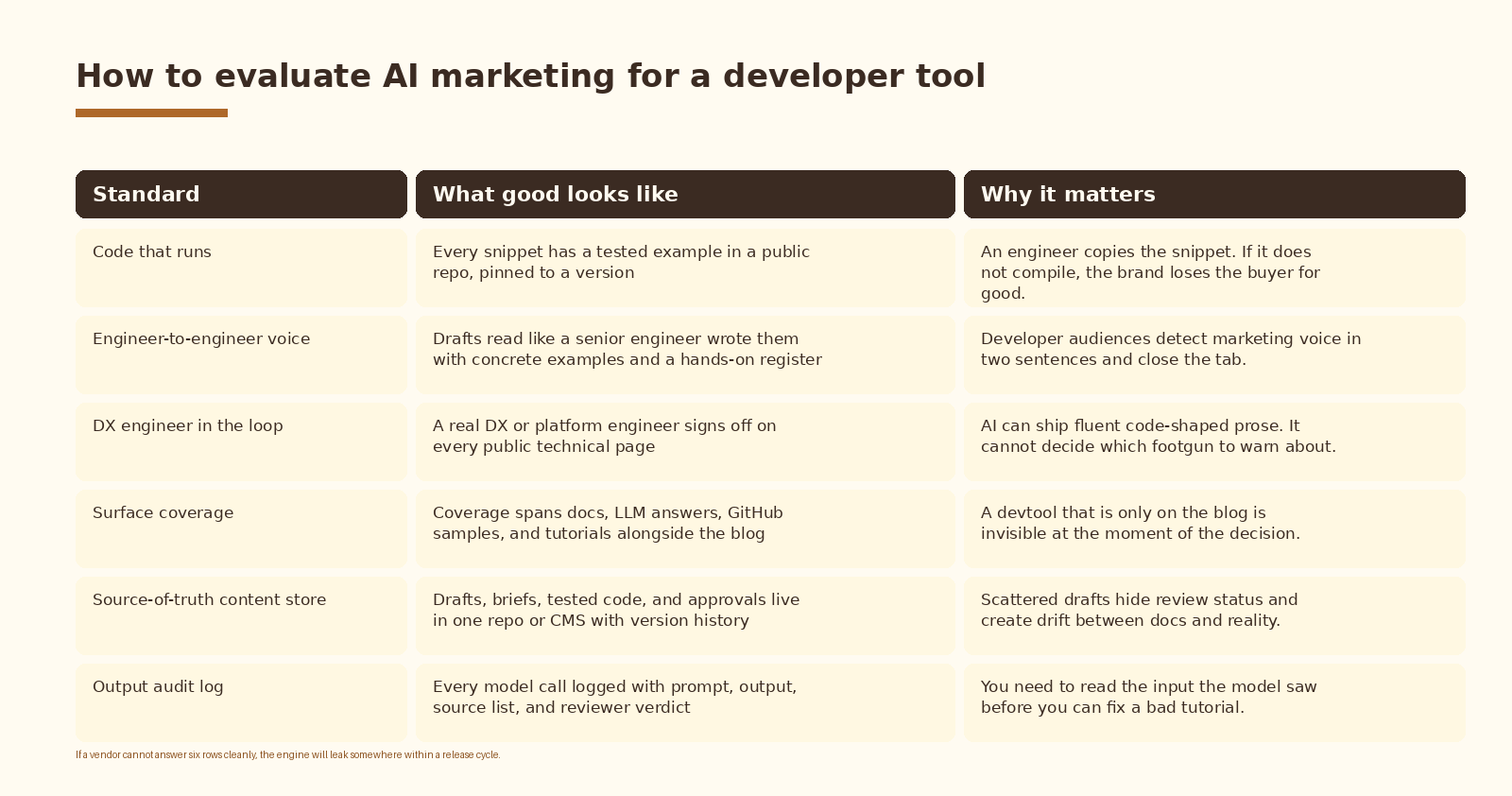
- Evaluation standards: code that runs, engineer-to-engineer voice, DX engineer in the loop, surface coverage, single content store, and a full output audit log.
If you are evaluating who should build this for your team, this guide gives you both the technical blueprint and the standards to evaluate the work.
Why developer marketing needs its own playbook
Most AI marketing engines are tuned for buyer personas, funnels, and SEO volume. Developer buyers behave differently. The buyer is also the user, the user reads the docs before talking to sales, and the deciding moment is whether a working code sample runs on their machine. A generic engine that ships keyword-targeted blog posts with untested snippets reads as a marketing artifact and gets closed before the second scroll.
A developer-grade engine is built around three constraints generic engines ignore. Every public claim is grounded in a working repo. Every page reads like an engineer wrote it for another engineer. Every surface that matters is covered, from API reference pages to LLM answers to GitHub samples. AI fits this shape well when the pipeline keeps a real DX engineer in the loop and runs every code block through CI.
If you are interested in building AI agents and automation like this for your developer tool or API, book a call here.
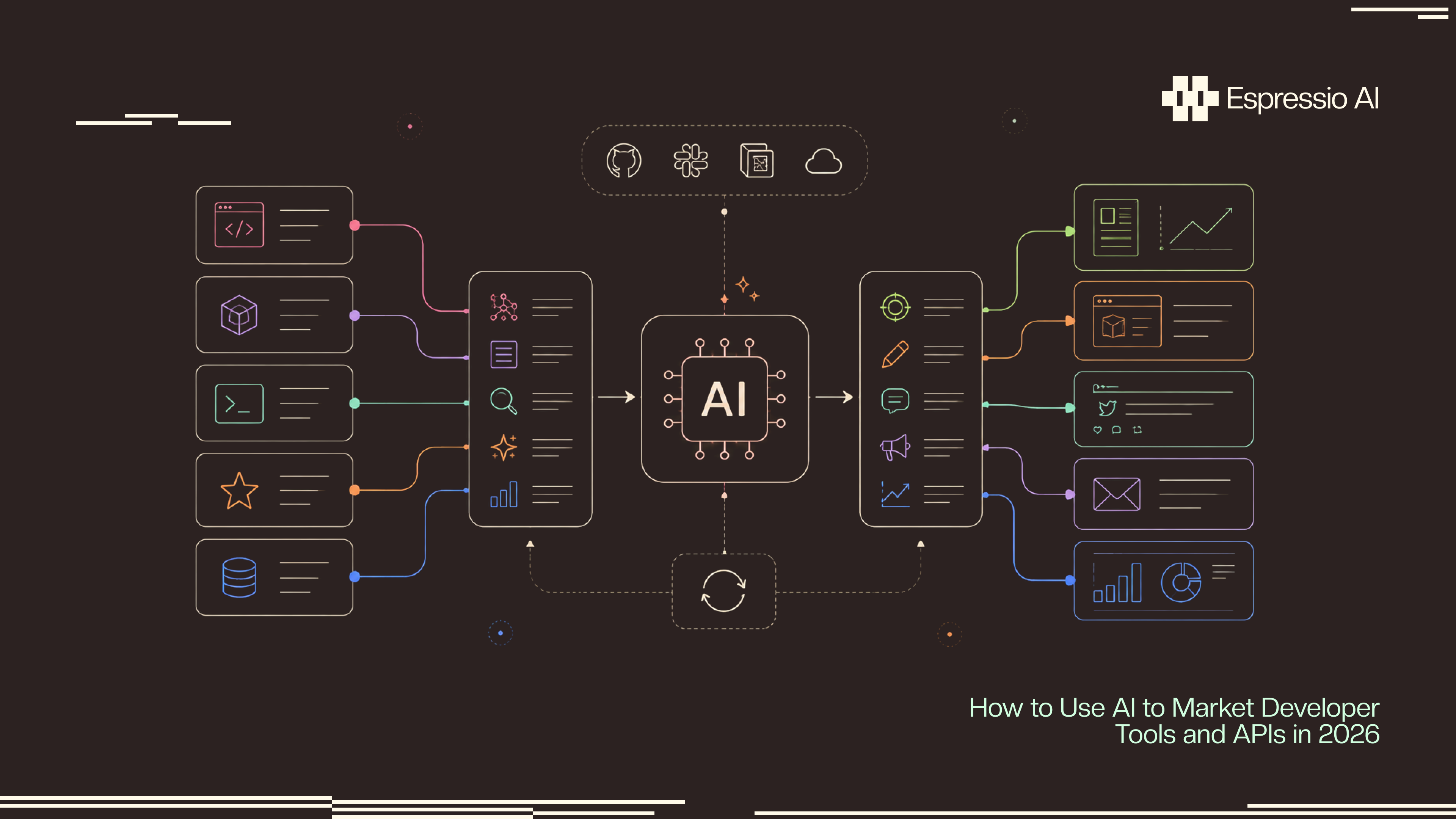
The five-stage developer marketing pipeline
Treat the engine as five stages and keep them separate. Each stage has a different failure mode and a different reviewer. Merging the topic stage with the draft stage is how engines end up writing fluent code-shaped prose about questions no engineer actually asks.
1. Signals
List every source that tells you what engineers using your product or your competitor’s product are actually doing. GitHub stars, PRs, and issues on your repo and the closest two competitors. Package registry downloads from npm, PyPI, crates.io, or Maven Central. Support tickets and Discord questions. Search queries from your docs. LLM answer logs from your support assistant. Conference talk topics. The signal layer is the engine’s memory of real engineer questions; without it, the engine writes about whatever the keyword tool says is trending.
2. Topics
An LLM clusters the signals into a topic map. Each topic carries the actual question, the intent, the surface the answer belongs on, the related symbols and error codes, and the closest existing competitor page. Claude and GPT-4o both handle this well when given a structured prompt and an example topic record. The topic map is the contract between the signal layer and the writing layer. It goes to a DX engineer for a yes or no before any draft is written.
3. Draft
The model writes the asset from the approved topic record. Quickstarts, recipe pages, reference snippets, migration guides, comparison pages, and blog posts all share one rule. Every code block is real code with a path to a real file in a public repo, pinned to a version, and exercised by CI. The voice prompt ships with three to five real writing samples from your DX team plus explicit rules about cadence, openers, and what marketing language to avoid. Log every prompt and output.
4. Distribute
Ship the asset to the surface that matches the intent. API reference goes to the docs site. Quickstarts and recipes go to docs and to a GitHub samples repo. Comparison and migration pages go to the marketing site and the docs. Tutorial-style pages go to the blog and a dev community such as Dev.to or Hashnode if that fits your audience. Submit pages to LLM-readable surfaces by keeping the markup clean, the sitemap fresh, and the canonical tag honest. Search engines and LLM answer engines reward content that is structured, sourced, and dated.
5. Review
Two reviewer roles. A DX or platform engineer checks the code, the claims, and the footguns. An editor checks readability, headings, and example flow. Block public publish until both pass. Sign-off writes back to the content store, the docs repo, and the audit log. The DX review is the gate that decides whether the engine ships docs an engineer would link to.

Six surfaces where developer buyers actually decide
Most devtool teams ship a blog and call it marketing. Developer buyers spend the deciding minutes on other surfaces. Pick two from the list below, cover them end to end, then expand.
- Reference docs. API reference, schemas, error codes, and rate-limit pages. The page buyers grep before they trust the product. The single highest-trust surface in the set.
- Quickstarts. A working hello-world in under five minutes per language and runtime. AI is strong here because the page is template-shaped and easy to verify in CI.
- Recipe pages. Task-shaped tutorials for the top fifty jobs your API actually does. Built from real support tickets and real search queries inside your docs.
- LLM answers. Show up cleanly when an engineer asks ChatGPT, Claude, or a code assistant how to do the job. Clean structure and primary-source citations help your pages get pulled into AI answers.
- Code samples on GitHub. Real repos with tests and CI that engineers can fork and ship from. Every snippet in your docs links to a sample file in the repo.
- Comparison and migration pages. Honest side-by-side pages and migration guides from the two closest tools. High commercial intent, requires careful claim verification.
The stack that earns its keep in 2026
The model does the writing. Everything else exists to make sure the model writes about real questions, ships tested code, and lands on the surfaces that actually move the deal. Keep the layers portable. Anything that locks the data into a UI becomes a tax later.
- Docs platform: Mintlify, ReadMe, Docusaurus, or a static-site build on top of Markdown. Owns reference, quickstarts, and recipes with version history.
- Samples repo: a public GitHub organization with one repo per language and runtime. Every snippet in the docs links to a sample file pinned to a version.
- Data warehouse: BigQuery, Snowflake, or Postgres. Owns the signal store: stars, downloads, search queries, support tickets, and LLM answer logs.
- AI layer: Claude or GPT-4o for clustering signals into topics, drafting briefs, and writing first-pass copy. Use the smaller model for clustering, the larger one for long-form recipes and migration guides.
- Voice store: a DX-team prompt template with three to five real writing samples and explicit rules. Refresh each quarter as the product surface changes.
- Orchestration: n8n, Make, or GitHub Actions. Pick one and standardize. Splitting orchestration across three tools is how teams lose the audit trail.
- Review and audit: a Slack or Linear channel where every draft lands for DX and editor sign-off. Sign-off writes back to the docs repo and the warehouse.
If you want this set up cleanly inside your developer marketing stack with logging, retries, and a feedback loop into your docs and your repo, that is the kind of work we ship at Espressio.

Generic AI content versus developer-grade content
The fastest way to see whether an engine fits a developer tool is to compare a generic AI content build against a developer-grade one. The generic build picks topics by keyword volume, writes in brand marketing voice, ships untested snippets, runs marketer-only review, and ships to a blog. The developer-grade build picks topics from real engineer questions, writes engineer-to-engineer, ships tested and versioned code, runs DX and editor review, and covers docs, LLM answers, GitHub samples, and the blog.
The generic build produces pages that bounce on the first scroll. The developer-grade build produces pages that get linked from real repos.
How to evaluate the build
Whether you are scoping a vendor or auditing your own internal stack, run the engine against six standards. A build that cannot answer all six cleanly will leak somewhere within a release cycle.
Common mistakes
- Shipping untested code in tutorials. Every snippet ships from a public repo, pinned to a version, and exercised by CI. One broken snippet costs more trust than ten good posts earn.
- Picking topics from keyword volume. The right topics come from your support tickets, your GitHub issues, your docs-search queries, and your LLM answer logs.
- Writing in brand marketing voice. Developer audiences detect marketing voice in two sentences. Voice prompts ship with three to five real writing samples from your DX team.
- Marketer-only review. The editor catches typos. The DX engineer catches the footgun that ships your buyer’s pager. Both reviewers are required for public technical pages.
- Covering only the blog. Reference docs, quickstarts, recipes, LLM answers, and GitHub samples are the surfaces buyers actually grep. The blog is the easiest one and the least decisive.
- Skipping the audit log. You need to read the input the model saw before you can fix a bad tutorial. Anything less than full prompt-output-source logging is a sunk cost.
How to know it is working
Pick a small set of metrics, instrument them on day one, and read them weekly. Avoid promising specific targets up front. Watch how they move as you tighten the signals, the voice prompt, and the surface coverage.
- Sample-runs-on-clone rate: share of public code samples that compile and pass tests on a clean clone. The target is one hundred percent.
- DX-approval rate on light edits: share of drafts the DX reviewer approves without rewriting. Watch how this moves as you iterate the topic stage and the voice prompt.
- Docs share of total visits: share of devtool site sessions that hit a docs page. Devtool buyers spend the deciding minutes here.
- LLM citation rate: share of target topics where your docs are cited or paraphrased by ChatGPT, Claude, or a code assistant when asked the underlying question.
- Tutorial-to-signup conversion: share of recipe and quickstart sessions that create an API key or a sandbox account.
- Pipeline efficiency: published surfaces per dollar of model spend per week. Useful for sizing the next surface phase.
FAQ
Can AI write our reference docs end to end?
No. AI is excellent at drafting reference pages from a typed schema, an OpenAPI spec, or a Protocol Buffers definition, then explaining each field in plain language. AI is not safe writing the schema itself or deciding which fields to expose. Treat the spec as the source of truth. Generate the prose around it, run it through DX review, and publish.
Claude or GPT-4o for developer content?
Claude tends to hold a structured voice across long technical pages and is strong at following format rules. GPT-4o is faster and cheaper for clustering signals and short summaries. Most devtool teams run both, picking the model per workflow. The differences between them matter less than the quality of your topic stage and your sample repo.
How do we show up in ChatGPT, Claude, and other AI answer engines?
Three things compound. Ship structured, well-headed pages with a clear answer near the top of each H2. Cite primary sources, version your pages, and keep the sitemap fresh so crawlers and answer engines see the latest copy. Publish working code on a public GitHub repo with the same examples your docs reference. Answer engines tend to surface content that is structured, sourced, and matched by real working code.
Should we still write blog posts if docs are the deciding surface?
Yes, with a different job. The blog is where you cover migration stories, comparison pages, and engineering deep-dives that earn links from other engineers. The blog drives discovery and brand. The docs and the samples repo drive the decision. Both surfaces share the same topic map and the same DX review.
Where does the DX engineer find time to review?
Two patterns work. Dedicate one weekly review slot per DX engineer and queue drafts to fit it. Or rotate the DX reviewer role across the platform team so no single person becomes the bottleneck. The topic stage is what protects the DX engineer’s time. A clean topic record turns a thirty-minute review into a five-minute one.
What to do next
- Pick the two highest-leverage surfaces. The default pair is quickstarts plus recipe pages.
- Stand up the signal layer and wire your top three sources: GitHub events, package downloads, and docs-search queries. Aim for one week to first topic map.
- Write the DX voice prompt. Three to five real writing samples plus explicit rules about marketing language to avoid. Refresh quarterly.
- Stand up the public samples repo. One repo per language and runtime. Every snippet in your docs links to a sample file pinned to a version.
- Put DX and editor review on every public technical page. Track DX approval rate weekly.
- Audit the engine against the six evaluation standards every month. Replace the weakest piece each cycle.
If you want automation like this set up cleanly inside your developer marketing operations, let’s talk.
Related Espressio guides
- How to Build an AI Content Engine for Fintech Companies
- How to Use AI Marketing Automation for Web3 Projects Step by Step
- How to Automate SEO Content Briefs with Perplexity and Claude
- How to Automate B2B Marketing for Professional Services with Claude -> https://espressio.ai/blog/ai-b2b-pro-services-claude
- Claude API for Marketing Teams: Complete Setup Guide 2026

