
Luka Mrkić
Head of BD
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 9, 2026
How to Automate B2B Marketing for Professional Services with Claude
TL;DR
- A Claude-powered B2B engine for professional services grounds every outbound asset in account-level facts, ships in a named partner’s voice, and routes the partner’s one-click approval before send.
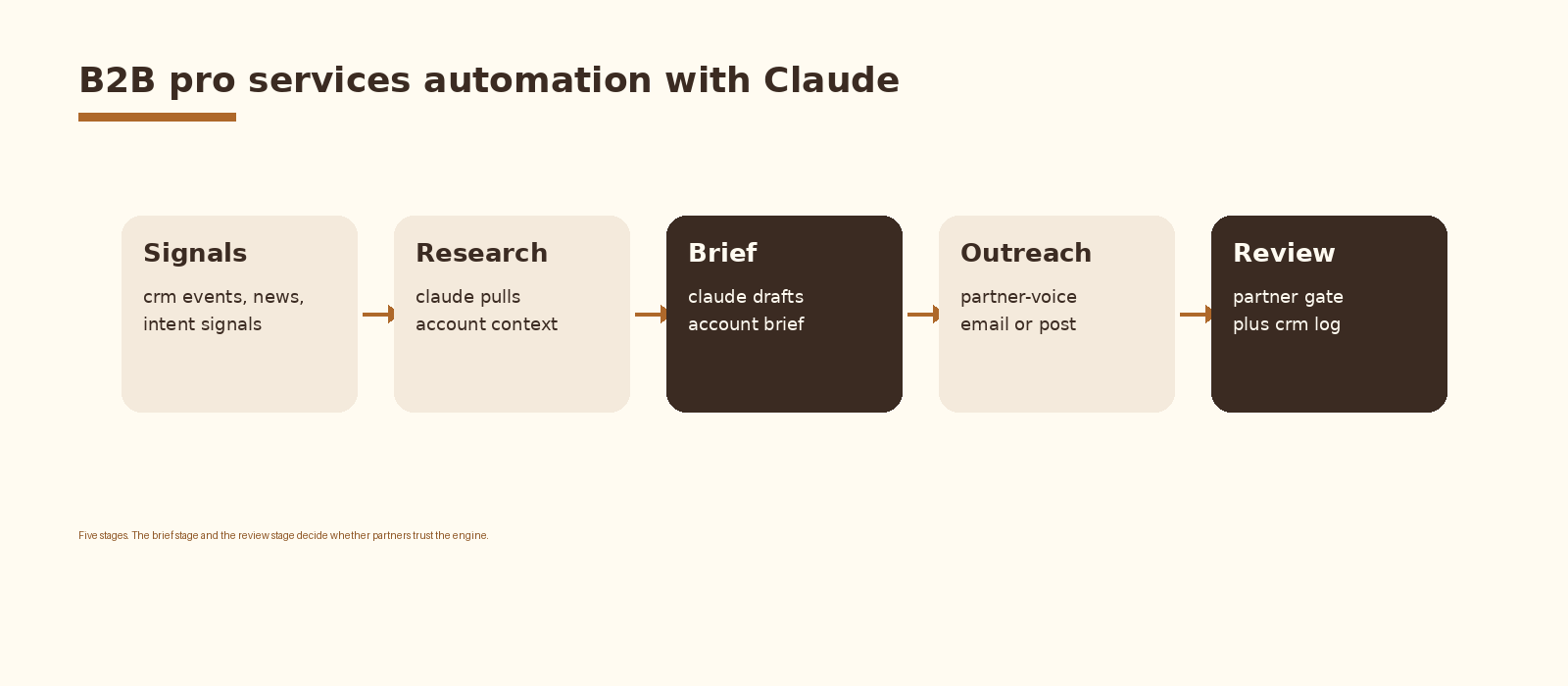
- The pipeline is five stages: signals, research, brief, outreach, review. The brief stage and the partner review are where the engine earns trust.
- Pick two workflows and ship them end to end. Account research briefs plus proposal-stage emails is the strongest opening pair.
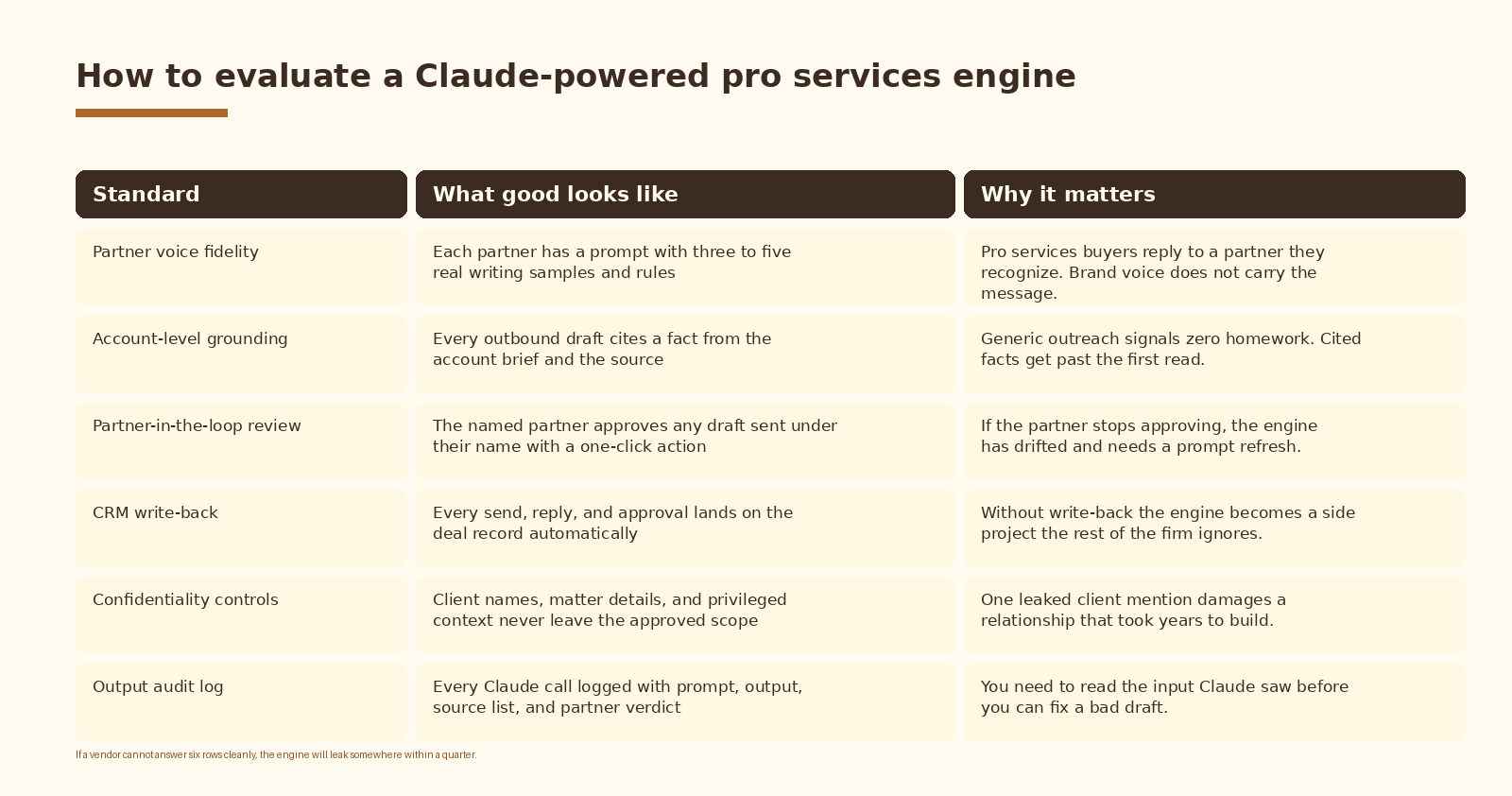
- Evaluation standards: partner voice fidelity, account-level grounding, partner-in-the-loop review, CRM write-back, confidentiality controls, and a full output audit log.
If you are evaluating who should build this for your team, this guide gives you both the technical blueprint and the standards to evaluate the work.
Why professional services need a different playbook
Most B2B marketing automation is built for SaaS funnels. A product page, a form fill, a sequence, a meeting. Professional services firms do not sell that way. The buyer hires a partner, the partner sells the firm, and the firm sells the practice. A generic engine that fires templated sequences from a shared brand inbox gets filtered out before it reaches the buyer.
A pro services engine is built around three constraints SaaS engines ignore. Every public message goes out under a named partner. Every claim should cite something the partner could defend in a meeting. Every send is logged on the deal record so the rest of the firm can see what was promised. Claude fits this shape well because it can hold the partner’s voice, the account context, and the firm’s compliance rules in one structured prompt.
If you are interested in building AI agents and automation like this for your professional services firm, book a call here.
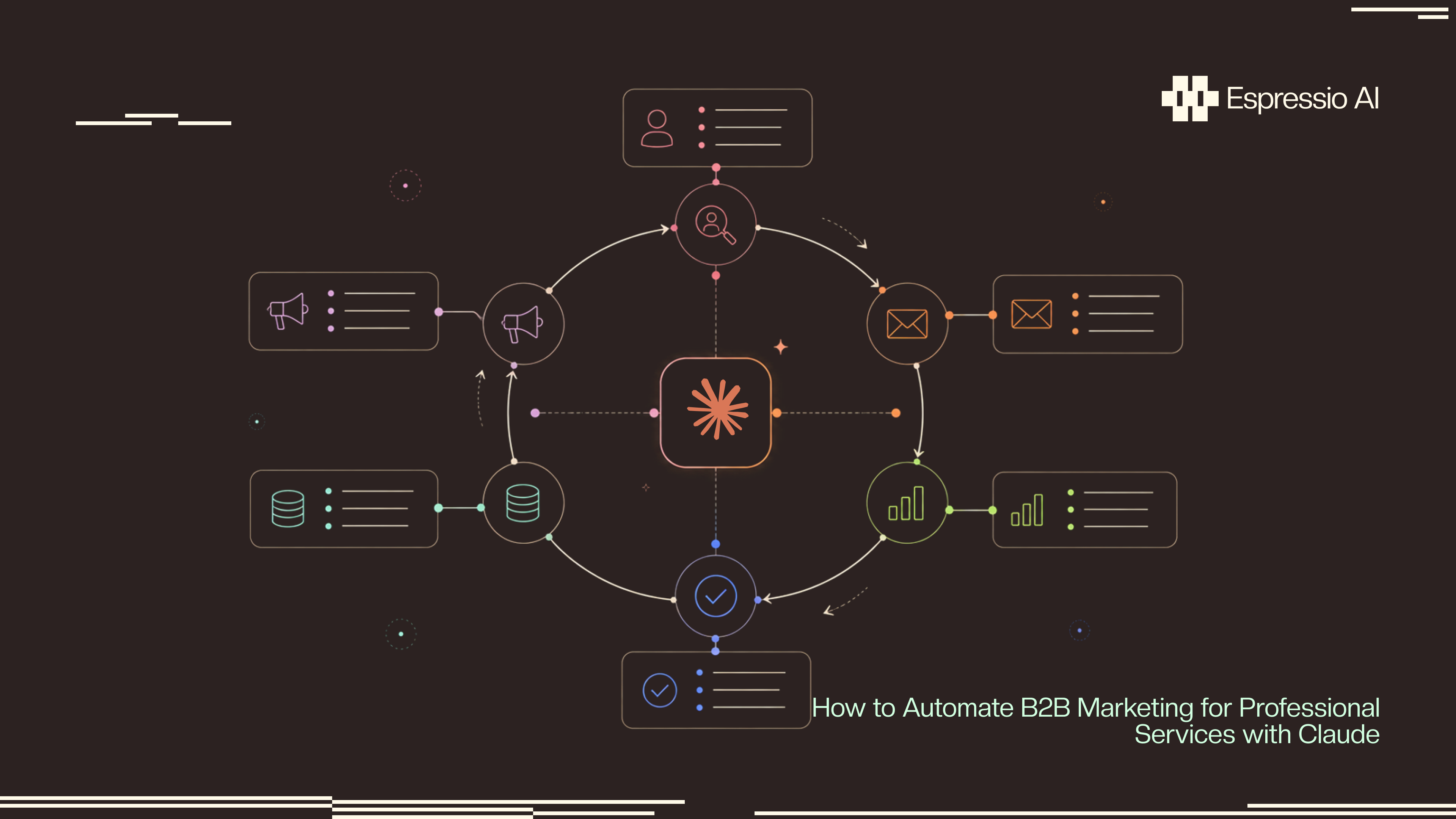
The five-stage Claude pipeline
Treat the engine as five stages and keep them separate. Each stage has a distinct failure mode and a different reviewer. Merging them is what produces the generic blast nobody opens.
1. Signals
List every source that gives you a reason to reach a named account today. CRM events from HubSpot or Salesforce. News mentions from a Google News or Perplexity feed. LinkedIn role changes from a Phantombuster or Clay job. Intent data from Bombora, G2, or your tracking pixel. Event registrations. Conference attendee lists. The signals layer is the engine’s calendar. Without it, the engine writes generic copy on a generic schedule.
2. Research
Claude pulls the account context. Public filings, recent funding, executive moves, product launches, regulatory shifts, and any prior touchpoints from the CRM. Save the research as a structured record in a warehouse such as BigQuery, Snowflake, or Postgres. Every fact carries a source URL and a retrieval date. The research record is the memory Claude reuses across every downstream draft for that account.
3. Brief
Claude drafts a one-page account brief from the research record. Who the buyer is. What changed. What angle the partner should take. Which practice area is relevant. Which past client story is closest. The brief is the contract between research and outreach. It goes to the named partner for a yes or no before any draft is written. A clean brief turns a forty-minute partner review into a five-minute one.
4. Outreach
Claude writes the outbound asset from the approved brief, the account record, and the partner’s voice prompt. The voice prompt ships with three to five real writing samples from the partner plus explicit rules about cadence, openers, and closes. Drafts include inline source markers so the partner can trace every claim. Log every prompt and output. The model writes the draft. The partner owns the send.
5. Review
Two reviewer roles. The named partner approves the draft with a one-click action in Slack or Gmail. An ops reviewer checks the CRM write-back, the unsubscribe state, and the confidentiality scope. Block any send until both pass. Sign-off writes back to the deal record so the next partner on the account sees what was sent and what came back.

Six marketing workflows worth automating with Claude
Most professional services firms try to wire six workflows in week one and ship none of them cleanly. Pick two from this list, ship them end to end, then expand.
- Account research briefs. Claude pulls filings, LinkedIn moves, and news into a one-page brief the partner reads before any meeting. High leverage, low risk, easy to ship in week one.
- Proposal-stage emails. Drafts a partner-voice follow-up to a specific stakeholder by role with a cited fact from the brief. The highest reply-rate workflow in the set.
- Practice-area content. Briefs and first drafts for thought-leadership posts in the partner’s voice. Claude handles structure and citation, the partner handles judgment.
- Event follow-ups. Personalized note per attendee that cites the session and proposes a relevant next step. Pairs well with conference and webinar tracking.
- Referral nurture. Quarterly note to past clients that opens with a relevant insight tied to their industry. No pitch in the first message.
- Win and loss summaries. Claude summarizes call recordings into a structured deal record the partner reads in two minutes. Drives better forecasting and better proposals.
The stack that earns its keep in 2026
Claude does the writing. Everything else in the stack exists to give Claude the right context and to route the output to the right human. Keep the layers portable. Anything that locks the data into a UI becomes a tax later.
- CRM: HubSpot or Salesforce. Owns deal records, contact roles, and the deal stage that triggers each workflow.
- Data warehouse: BigQuery, Snowflake, or Postgres. Owns research records, briefs, drafts, and approval logs with source URLs and retrieval dates.
- Signal layer: Clay or Phantombuster for LinkedIn and people data, Perplexity or a Google News feed for company news, Bombora or G2 for intent.
- AI layer: Claude for research, briefs, drafts, and summaries. Claude Sonnet handles most workflows. Use Claude Opus for proposal-stage emails and long-form practice content.
- Voice store: a partner-by-partner prompt template with three to five real writing samples and explicit cadence rules. Refresh quarterly.
- Orchestration: n8n, Make, or Zapier. Pick one and standardize. Splitting orchestration across three tools is how teams lose the audit trail.
- Review and audit: a Slack channel where every draft lands for partner and ops sign-off. Sign-off writes back to the CRM and the warehouse.
If you want this set up cleanly inside your professional services stack with logging, retries, and a feedback loop into your CRM, that is the kind of work we ship at Espressio.

Generic B2B automation versus pro-services-grade
The fastest way to see whether an engine fits a professional services firm is to compare a generic B2B build against a pro-services-grade one. The generic build runs from form fills, uses one brand template, runs marketer-only review, and skips partner context. The pro-services-grade build runs from CRM events, news, intent, and event signals, ships per-partner voice prompts with real examples, runs partner plus ops plus editor review, and grounds every draft in a cited account brief.
The generic build produces unread inbox sends. The pro-services-grade build produces replies from named buyers who recognize the partner.
How to evaluate the build
Whether you are scoping a vendor or auditing your own internal stack, run the engine against six standards. A build that cannot answer all six cleanly will leak somewhere within a quarter.
Common mistakes
- Sending under a shared brand inbox. Pro services buyers reply to people they recognize. Every public send goes under a named partner with a real reply address.
- Treating partner voice as a one-time PDF. Voice prompts belong in the prompt with three to five real writing samples and explicit cadence rules, refreshed every quarter.
- Marketer-only review. Marketing catches typos. The partner catches wrong claims about the account. Ops catches CRM and confidentiality issues. All three are required.
- Skipping CRM write-back. If the rest of the firm cannot see what was sent and what came back, the engine becomes a marketing side project the partners ignore.
- Letting Claude write without sources. Every claim about the account ships with a cited URL in the draft so the partner can defend it in the next meeting.
- Forgetting confidentiality scope. Client matter details, privileged context, and any data covered by an NDA stay outside the model prompt unless the legal team has signed off.
How to know it is working
Pick a small set of metrics, instrument them on day one, and read them weekly. Avoid promising specific targets up front. Watch how they move as you tighten the signals and the partner voice prompts.
- Partner-approval rate: share of drafts the named partner approves with light edits. Watch how this moves as you iterate the brief stage and the voice prompt.
- Reply rate from named buyers: share of partner-voice sends that get a human reply within seven days. The metric to watch as the engine matures.
- Time from signal to send: median hours from a CRM or news event to an approved partner-voice send. Faster is better, capped by the partner review.
- CRM write-back coverage: share of sends, replies, and approvals that land on the right deal record. The target is one hundred percent.
- Confidentiality flag rate: share of drafts blocked by the scope check. Anything above zero is useful signal about prompt drift.
- Pipeline efficiency: partner-approved drafts per dollar of Claude spend per week. Useful for sizing the next workflow phase.
FAQ
Can we use Claude without ripping out our existing CRM?
Yes. Claude sits on top of HubSpot or Salesforce through their APIs and writes back to the deal record using existing webhooks. The CRM stays the source of truth for contacts, deals, and consent. The data warehouse stores the briefs and the audit log. The CRM is one of the easier integrations because both HubSpot and Salesforce expose the fields you need.
Claude or GPT-4o for professional services?
Claude tends to hold a partner’s voice better across long drafts and follows structured-prompt rules consistently. GPT-4o is faster and cheaper for short summaries. Most firms end up running both, picking the model per workflow. The differences between them matter less than the quality of your brief stage and your voice prompts.
How do we handle confidentiality and privilege?
Define a scope document with the legal or risk team that lists what can and cannot enter the model prompt. Encode the rules as a pre-draft classifier or a prompt-level guard that blocks privileged terms, client matter codes, and any data under NDA. Log every blocked attempt. The rule list is written once. The engine enforces it every time.
How do we keep voice consistent across many partners?
Each partner gets their own voice prompt. The prompt carries three to five real writing samples drawn from approved past work, an explicit list of openers and closes they actually use, and the topics they are willing to write about. Refresh the prompt quarterly. The partner reviews the prompt itself once a quarter so the model stays in step with how they are writing today.
Should Claude ever send without a partner approving?
For internal research briefs and CRM summaries, yes. For anything that lands under a partner’s name in a buyer’s inbox, no. The cost of one wrong claim is higher than the time savings of removing the reviewer. Once partner-approval rate sits above ninety percent for a quarter on light edits, you can consider lifting the gate on lower-stakes channels such as event follow-ups.
What to do next
- Pick the two highest-leverage workflows from the six-card list. The default pair is account research briefs plus proposal-stage emails.
- Stand up the warehouse and wire your top three signals: CRM events, company news, and intent. Aim for one week to first brief.
- Write the partner voice prompts. Three to five real writing samples plus explicit cadence rules per partner. Refresh quarterly.
- Add the pre-send confidentiality gate. Encode the legal team’s scope rules. Log every blocked draft.
- Put partner and ops review on every public send. Track approval rate weekly.
- Audit the engine against the six evaluation standards every month. Replace the weakest piece each cycle.
If you want automation like this set up cleanly inside your professional services growth stack, let’s talk.
Related Espressio guides
- How to Use AI Marketing Automation for Web3 Projects Step by Step
- How to Build an AI Content Engine for Fintech Companies
- How to Integrate Claude with HubSpot CRM for AI-Powered Sales Follow-ups
- How to Integrate Claude with Salesforce for Automated Proposal Generation
- How to Use AI to Market Developer Tools and APIs in 2026 -> https://espressio.ai/blog/ai-market-developer-tools-apis

