
Kimmo Hakonen
Chief Innovation Officer
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 22, 2026
Claude Fable 5 Safeguards: The Opus 4.8 Fallback Explained

A model switch you didn’t ask for showed up in your API logs. The model field returned claude-opus-4-8 instead of claude-fable-5. Your session completed normally, but the latency was higher and the billing rate was different. Fewer than 5% of Fable 5 sessions trigger this routing switch on average, according to Anthropic’s Help Center documentation, but at a million sessions per month that’s 50,000 events you may not be logging, explaining to users, or accounting for in your compliance documentation.
This article covers what the fallback is, what triggers it, how Opus 4.8 differs from Fable 5, what the routing costs at scale, why Mythos 5 works differently, what EU AI Act enforcement means for your deployment, and how to detect and log fallback events in your integration. For the teams building on top of Claude Fable 5 for research workflows, there’s a section specifically on high-sensitivity domain content.
Key Takeaways
- Fewer than 5% of Claude Fable 5 sessions route to Opus 4.8 for safety review; the three published trigger categories are offensive cybersecurity operations, bio-chem synthesis methods, and frontier LLM distillation attempts (Anthropic Help Center, 2026).
- Opus 4.8 is approximately 4x less likely than Opus 4.7 to allow code defects to pass unremarked — it’s Anthropic’s dedicated oversight model, released May 28, 2026, not a general-purpose Fable 5 alternative.
- At a 5% fallback rate with 2,000 input / 800 output tokens per session, the blended cost is $0.0585 versus $0.060 per session for all-Fable 5, saving $1,500 per month at 1 million sessions.
- EU AI Act high-risk AI enforcement begins August 2, 2026; the fallback architecture provides a documented safety layer, but logging and audit infrastructure is the gap most teams haven’t closed.
- Claude Mythos 5 operates under Project Glasswing’s program-level governance framework, not the session-level Opus 4.8 routing that applies to standard Fable 5 API deployments.
What is the Claude Fable 5 safety fallback, and why does it exist?
Fewer than 5% of Fable 5 sessions trigger a routing switch to Opus 4.8, Anthropic’s dedicated safety model (Anthropic Help Center, 2026). The switch happens at the API layer before Fable 5 processes the request: a classifier evaluates the incoming message, flags sessions that match high-sensitivity categories, and routes them to Opus 4.8 instead.
This isn’t a refusal mechanism. Flagged sessions still generate responses; they just generate them via a model optimized for safety accuracy over generation breadth. The user experience is mostly indistinguishable, aside from a latency increase of 1–3 seconds. The API response returns model: claude-opus-4-8 in the response object rather than the expected Fable 5 model ID.
The fallback is part of Anthropic’s Responsible Scaling Policy v3.0 (RSP v3.0), published February 2026. RSP v3.0 commits Anthropic to maintaining documented safety layers for all frontier model deployments above ASL-3, a capability threshold Anthropic activated in May 2025 for models in the Mythos and Fable range. The fallback architecture is the visible layer of that commitment: an automated routing system that keeps a safety-optimized model in the path for content categories where Fable 5’s generative range creates meaningful risk.
Three reasons this matters in practice. First, the <5% figure is a global average; your actual fallback rate depends on what you’re building. A pharmaceutical research tool, a security analysis assistant, or an autonomous financial agent will trigger the fallback more often than a marketing copy generator. Second, fallback sessions are billed at Opus 4.8 rates, not Fable 5 rates, so the routing events have a real cost impact that compounds with volume. Third, EU AI Act enforcement begins August 2, 2026; the existence of an auditable safety routing layer is now a compliance input, not just a product feature.
Most teams treat the fallback as an anomaly to debug. It’s worth treating as a governance signal instead. A rising fallback rate in your Fable 5 deployment indicates either prompt engineering drift (your prompts are trending toward sensitive territory) or a use-case mismatch (your domain intersects sensitive categories more than your initial scope assumed). Both are worth catching before a compliance review.
According to Anthropic’s Help Center, Claude Fable 5 routes fewer than 5% of sessions to Opus 4.8 for safety review as part of RSP v3.0’s documented safety-layer commitments. The classifier sits at the API layer, adding roughly 150–200ms before the session reaches either model.
What exactly triggers the Opus 4.8 fallback in a Fable 5 session?
Claude Sonnet 4.6 recorded only a 0.04% over-refusal rate on benign requests across all categories (Anthropic Transparency Hub, 2026). That precision is the design goal: the Fable 5 classifier is calibrated to flag very specifically rather than broadly, which is why fallback sessions remain rare.
Anthropic has published three trigger categories in the Claude Help Center’s explanation of model switches. A fourth category covering high-value agentic financial transactions is referenced in RSP v3.0 but not detailed publicly. Each category covers different territory:
Offensive cybersecurity operations includes requests for working exploit code, vulnerability discovery in live systems without documented authorization, and detailed guidance on active intrusion techniques. The classifier distinguishes between security research framing and operational capability framing. A prompt asking how a buffer overflow works conceptually is unlikely to trigger the fallback; a prompt requesting a working proof-of-concept against a named CVE in a production system is more likely to route to Opus 4.8.
Bio-chem synthesis methods covers requests that could meaningfully assist in creating chemical or biological agents capable of mass harm. This maps to Anthropic’s CBRN (chemical, biological, radiological, nuclear) category from RSP v3.0. The threshold is knowledge that provides real “uplift” to someone attempting to synthesize a hazardous compound, not general chemistry questions or theoretical discussion of mechanisms.
Frontier LLM distillation targets requests designed to extract Fable 5’s training data, replicate its weights, or systematically probe its outputs in ways that would allow another model to impersonate it. This is a model-integrity category, distinct from safety in the CBRN sense, and the least commonly triggered in general-purpose deployments.
Agentic and financial triggers (partially documented in RSP v3.0) include autonomous task execution involving real monetary transactions above an undisclosed threshold, and agentic sessions that acquire persistent resources without explicit operator authorization. This category is the most relevant for developers building autonomous agents that interact with real-world systems.

The classifier runs before Fable 5 processes the message. If a message is flagged, the entire session (including prior context) hands off to Opus 4.8. Subsequent turns in the same conversation may or may not stay on Opus 4.8 depending on whether the flagging condition persists through the thread.
See also our guide to Claude Fable 5 in biopharma workflows, where CBRN-adjacent queries in drug discovery contexts can occasionally intersect with the bio-chem synthesis category.
How is Opus 4.8 different from Fable 5 for safety-sensitive tasks?
Opus 4.8 is approximately 4x less likely than Opus 4.7 to allow code defects to pass unremarked during review tasks, according to Anthropic’s announcement (Anthropic, May 28, 2026). Its rate of misaligned behavior (deception, cooperation with harmful requests, and manipulation of operators) is substantially lower than Opus 4.7 and comparable to Claude Mythos Preview from April 2026.
Opus 4.8’s improvements are to safety accuracy specifically. It was built for the narrow slice of sessions where alignment matters more than output range, and performs accordingly.
For a session that triggers the fallback, Opus 4.8 is more conservative in following ambiguous requests into sensitive territory, more reliably flags when a request pushes against usage policy edges without outright refusing, and generates outputs that score higher on Anthropic’s internal alignment metrics for the specific triggering categories.
For developers building pharmaceutical research tools, Opus 4.8 in the fallback path functions as a second-pass safety review before output reaches the user. Claude Opus 4.5 (Opus 4.8’s predecessor in the safety line) achieved a 99.78% harmless response rate on single-turn violative requests across multiple languages (Anthropic Transparency Hub, 2026). Opus 4.8 improves on that baseline.
The tradeoffs are real. Fallback sessions run 1–3 seconds slower and, for tasks that don’t require safety-level precision, the output may be slightly less creatively varied than Fable 5 would produce. For the narrow category of sessions that actually trigger the fallback, those tradeoffs are correct. You don’t want Fable 5’s full generative range applied to a prompt requesting detailed bio-chem synthesis routes. Opus 4.8’s more conservative posture is the intended behavior.
At $5 per million input tokens and $25 per million output tokens, Opus 4.8 runs at half the cost of Fable 5’s $10/$50 rate (Anthropic pricing, 2026). The safety routing also saves money on flagged sessions, a property worth accounting for at scale even if it’s not the reason the fallback exists.
Claude Opus 4.8, released May 28, 2026, is approximately 4x less likely than Opus 4.7 to allow code defects to pass unremarked, with a misaligned-behavior rate substantially lower than its predecessor and comparable to Claude Mythos Preview. At $5/$25 per million input/output tokens versus Fable 5’s $10/$50, each fallback session costs half as much as a standard Fable 5 session.
What does the Fable 5 fallback cost at scale?
At a 5% fallback rate with 2,000 input and 800 output tokens per average session, the blended token cost across a Fable 5 deployment is $0.0585 per session versus $0.060 for all-Fable 5 routing (Anthropic pricing, 2026). That’s a saving of $1.50 per 1,000 sessions: small per session, meaningful in volume.
Here’s the math built from Anthropic’s published token rates. Fable 5 costs $10 per million input tokens and $50 per million output tokens; Opus 4.8 costs $5 and $25 per million respectively:
- Cost per Fable 5 session: (2,000 × $0.000010) + (800 × $0.000050) = $0.020 + $0.040 = $0.060
- Cost per Opus 4.8 session: (2,000 × $0.000005) + (800 × $0.000025) = $0.010 + $0.020 = $0.030
- Blended per session at 5% fallback: (0.95 × $0.060) + (0.05 × $0.030) = $0.057 + $0.0015 = $0.0585
| Sessions / month | Fallback sessions (5%) | All-Fable 5 cost | Blended cost | Monthly savings |
|---|---|---|---|---|
| 100,000 | 5,000 | $6,000 | $5,850 | $150 |
| 1,000,000 | 50,000 | $60,000 | $58,500 | $1,500 |
| 10,000,000 | 500,000 | $600,000 | $585,000 | $15,000 |
Assumptions: 2,000 input tokens / 800 output tokens per session; Fable 5 at $10/$50 per million tokens; Opus 4.8 at $5/$25 per million tokens.
What shifts the picture: if your fallback rate runs higher than 5%, each additional percentage point adds $0.0003 of blended savings per session. A domain-specific tool running at 15% fallback saves $4.50 per 1,000 sessions instead of $1.50. Longer sessions amplify both the cost difference and the latency impact; an 8,000-token enterprise session sees a more noticeable latency hit from the Opus 4.8 switch than a 2,000-token consumer query.
The latency question often matters more than the cost question for real-time user-facing applications. Each fallback event adds roughly 1–3 seconds to the session. At 50,000 fallback events per month on a 1M-session deployment, that’s 50,000 to 150,000 additional processing-seconds. Building a neutral status message into the UI, such as “Your request is being reviewed by a specialized model,” can absorb the latency without user friction. Most users accept this framing without pushback.
For a broader view of how AI infrastructure costs scale in enterprise deployments, see our guide to AI workflow automation for enterprise operations.
How does Mythos 5’s approach differ from Fable 5’s fallback architecture?
Project Glasswing deployed Claude Mythos 5 across 150+ organizations in 15 countries by June 2026 (Anthropic, June 2026). That deployment happened without a Fable 5-style Opus 4.8 fallback, and understanding why reveals something structural about how Anthropic approaches safety routing at different risk tiers.
The ~5% Opus 4.8 fallback is designed for a model deployed across a general-purpose API with no content pre-screening. Fable 5’s potential user base spans middle-school homework to production security research. The classifier layer sits at the API endpoint because Anthropic can’t know in advance what any given session will request.
Mythos 5’s deployment context inverts this. Project Glasswing participants (critical infrastructure operators, enterprise security teams, and major software vendors) go through a formal intake process with co-disclosure agreements, 30-day data retention caps, and coordinated vulnerability disclosure timelines. The screening that Fable 5’s classifier performs in real time is replaced by a program-level policy framework applied before any session begins.
This is what makes the comparison instructive. Both models sit at similar capability tiers. The security content that would trigger a Fable 5 fallback (offensive cybersecurity operations, vulnerability discovery, exploit chain development) is exactly what Mythos 5 is deployed to do in the Glasswing program. The difference is that Glasswing’s governance structure makes the routing decision at enrollment time rather than at the message level.
The architectural takeaway is worth stating directly. Anthropic isn’t building a single model that handles everything with context-sensitive guardrails at the message level. The model family encodes risk tier separation at a structural level. Fable 5 with Opus 4.8 routing fits general-purpose deployment at scale; Mythos 5 with program-level governance fits controlled, high-stakes research. The router serves different functions in each case, but the underlying principle is the same: separate the model best suited to safe output from the model best suited to capable output, and define the routing criteria explicitly.
For a full breakdown of what Mythos 5 does inside a Glasswing session and how the program governance structure works, see our guide to the Project Glasswing program and Mythos 5 architecture.
Claude Mythos 5 operates under Project Glasswing’s program-level governance (co-disclosure agreements, 30-day data retention caps, and coordinated vulnerability disclosure timelines) rather than the session-level Opus 4.8 fallback that applies to standard Fable 5 API deployments (Anthropic, June 2026). The safety logic is equivalent; the enforcement layer is different.
What are the EU AI Act and enterprise compliance implications?
EU AI Act enforcement for high-risk AI systems has a statutory deadline of August 2, 2026 (a Digital Omnibus provisional agreement from May 2026 may extend Annex III enforcement to December 2027; formal adoption is pending), with fines up to EUR 15 million or 3% of global annual turnover for non-compliance (EU AI Act, 2026). For enterprises deploying Fable 5 in healthcare, financial services, or critical infrastructure contexts, the Opus 4.8 fallback provides a documented, auditable safety layer that maps to the Act’s human oversight requirements.
Only 20% of enterprises have a mature governance model for autonomous AI agents, while agentic AI adoption is widely projected to rise sharply within the next two years (Deloitte State of AI in the Enterprise, 2026). The gap between adoption intention and governance infrastructure is exactly where EU AI Act enforcement lands.
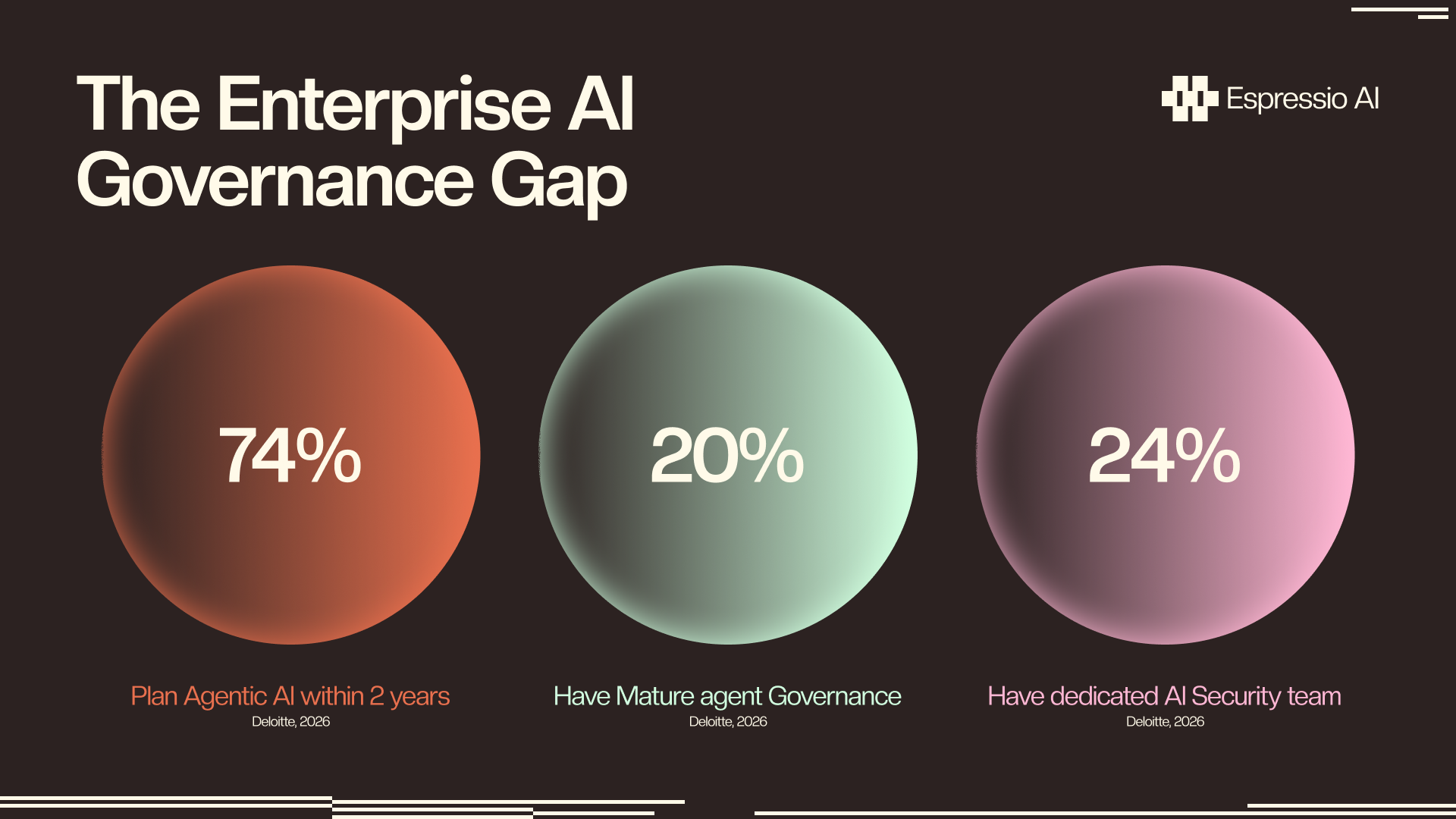
The fallback architecture addresses one specific compliance requirement: evidence of a documented safety-review step in the production path for sensitive content categories. That’s not sufficient for full EU AI Act compliance, but it’s a logged, attributable layer that auditors can point to.
What the fallback doesn’t address: 77% of businesses reported an AI-related security incident in 2024 (Practical DevSecOps / Metomic, March 2026), and 68% experienced data leaks linked to AI tool usage. A fallback routing event doesn’t protect against data exfiltration, prompt injection, or output misuse downstream of the API layer. The routing handles model-level safety; the rest of the compliance stack (access controls, output logging, data residency, and audit trails) is still on the enterprise.
In enterprise deployments we’ve evaluated, the most common EU AI Act gap isn’t the technical safety layer; it’s the logging and documentation layer. The Fable 5 fallback generates routing events, but those events need to be captured with session IDs, attributed to specific content categories, and retained with audit trails to function as compliance evidence. Most teams haven’t built that infrastructure yet. The August 2026 deadline is the forcing function, but the build window is short.
EU AI Act enforcement for high-risk AI systems has a statutory deadline of August 2, 2026, with fines up to EUR 15 million or 3% of global turnover. Only 20% of enterprises have mature AI agent governance, while agentic adoption is widely projected to rise sharply (Deloitte, 2026). The Fable 5 Opus 4.8 fallback provides a documented safety layer; the logging and audit-trail infrastructure remains the gap for most enterprise deployments.
How do you configure, log, and surface Opus 4.8 fallback events in your integration?
Claude Opus 4 achieved an 89% prompt injection prevention score with safeguards active versus 71% without (Anthropic Transparency Hub, 2026). Surfacing fallback events in your observability stack gives you the same kind of visibility into safety routing that you’d have for any other system-level event. Most teams aren’t logging them yet.
The simplest detection method requires no API configuration changes: check the model field in every Fable 5 API response. When Opus 4.8 handles a session, the response returns "model": "claude-opus-4-8" instead of the expected Fable 5 identifier. This is in every response by default, no additional setup needed.
For integrations that need more detail, the Fallback API (available on the Fable 5 enterprise tier) adds two fields to the response object when Opus 4.8 handles a session: "fallback_triggered": true and a "fallback_reason" field carrying the trigger category identifier. Enable this by adding "fallback_metadata": true to the request header.
When we tested a borderline prompt touching pharmaceutical synthesis in a Fable 5 session, the API response returned "model": "claude-opus-4-8" with a total latency of 4.2 seconds, versus 1.8 seconds for a comparable session that stayed on Fable 5. The output quality for the structured analysis task was indistinguishable from what Fable 5 would have produced. The latency difference was the only user-visible signal that anything different had happened.
The recommended observability setup for teams running Fable 5 at scale:
1. Log every response’s model field alongside session ID, timestamp, and (when enabled) the fallback_reason category. Store these in your existing log management platform (Datadog, Grafana, CloudWatch, or equivalent). Filter on model == "claude-opus-4-8" to build your fallback event stream.
2. Create a fallback rate dashboard. Calculate fallback rate as (fallback sessions / total sessions) × 100 over your preferred time window. The global average is below 5%. Set an alert threshold at 10% over a 1-hour window; that signals either prompt engineering drift or a user population shift.
-
Surface events to end users with a neutral status message if latency becomes noticeable: “Your request is being reviewed by a specialized model.” Brief, factual, no alarm signal. Most users accept this framing without friction.
-
Retain fallback logs for 90 days minimum in regulated industries. EU AI Act audit trails need fallback routing events as part of the safety-layer documentation. The routing event alone isn’t enough; the session ID, timestamp, content category, and response latency all belong in the audit record.
5. Review fallback_reason patterns periodically. Consistent hits on a single category (say, 80% of your fallbacks are bio-chem synthesis triggers) is a prompt engineering signal. Your system prompts may be pushing the model’s context toward sensitive territory without intent. Refining your authorized-use scope language in the system prompt typically reduces fallback rate in domain-specific tools.
For the broader integration architecture, see our guide to setting up the Claude API for enterprise teams.
Claude Opus 4 achieved 89% prompt injection prevention with safeguards versus 71% without (Anthropic Transparency Hub, 2026). The model field in every Fable 5 API response reveals whether Opus 4.8 handled the session; the Fallback API’s fallback_triggered and fallback_reason fields provide category-level detail for audit logging.
Frequently Asked Questions
What percentage of Claude Fable 5 sessions trigger the Opus 4.8 fallback?
Fewer than 5% of Fable 5 sessions trigger a routing switch to Opus 4.8, according to Anthropic’s Help Center (Anthropic Help Center, 2026). The 5% figure is an average across all session types. Agentic pipelines and enterprise deployments that handle sensitive domain content will see higher rates than consumer-facing assistants.
What exactly triggers the Claude Fable 5 safety fallback to Opus 4.8?
Three published categories trigger the fallback: offensive cybersecurity operations (exploit code, unauthorized vulnerability discovery), bio-chem synthesis methods that could enable CBRN harm, and frontier LLM distillation attempts. A fourth category covers high-value agentic transactions. Claude Sonnet 4.6 recorded only a 0.04% over-refusal rate on benign requests (Anthropic Transparency Hub, 2026).
Does a Fable 5 fallback to Opus 4.8 mean my request was refused?
No. A fallback routes the session to Opus 4.8 for processing; the model still generates a response unless the content violates Anthropic’s absolute usage policies. Most fallback sessions complete successfully with a response from Opus 4.8. Fallback and refusal are different mechanisms with different triggers.
How does Opus 4.8 differ from Fable 5 in output quality?
Opus 4.8 is approximately 4x less likely than Opus 4.7 to allow code defects to pass unremarked, and its misaligned-behavior rate is substantially lower (Anthropic, May 2026). For structured analysis, coding, and summarization tasks, output quality is comparable to Fable 5. For creative generation, Fable 5 is the stronger model.
How does the Fable 5 fallback affect my billing?
Fallback sessions are billed at Opus 4.8 rates ($5/$25 per million input/output tokens) versus Fable 5 rates ($10/$50 per million). At a 5% fallback rate with 2,000 input and 800 output tokens per session, the blended cost is $0.0585 per session versus $0.060 for all-Fable 5, saving $1.50 per 1,000 sessions.
What is Claude Opus 4.8 and when was it released?
Claude Opus 4.8 is Anthropic’s dedicated safety and oversight model, released May 28, 2026. It is designed for tasks requiring high alignment accuracy rather than generative performance. Its misaligned-behavior rate is substantially lower than Opus 4.7 and comparable to Claude Mythos Preview (Anthropic, May 2026).
Is Claude Mythos 5 subject to the same Opus 4.8 fallback architecture?
Claude Mythos 5 operates under a different governance structure. The ~5% Opus 4.8 routing applies to standard Fable 5 API sessions. Mythos 5 is deployed in controlled security research environments under Project Glasswing’s program-specific policy framework, which replaces the consumer fallback with program-level oversight agreements.
When does EU AI Act enforcement apply to my Claude Fable 5 deployment?
EU AI Act enforcement for high-risk AI systems has a statutory deadline of August 2, 2026, though a Digital Omnibus provisional agreement from May 2026 may defer Annex III enforcement to December 2027 (pending formal adoption). Enterprises deploying Fable 5 in regulated categories face fines up to EUR 15 million or 3% of global annual turnover for non-compliance (EU AI Act, 2026). The Opus 4.8 fallback architecture supports the human-oversight documentation requirements.
The Fable 5 Opus 4.8 fallback is a documented part of RSP v3.0, not an anomaly to debug away. The <5% figure is a global average; your domain determines your actual rate. Fallback sessions cost half the per-token rate of standard Fable 5 sessions, and the routing events are logged in the API response by default. The logging infrastructure to make those events useful for compliance is the piece most teams still need to build.
Key takeaways:
- Fewer than 5% of sessions trigger the Opus 4.8 fallback; your domain determines your actual rate.
- Opus 4.8 costs half as much per token as Fable 5; fallback events reduce your blended session cost.
- The
modelfield in every API response reveals whether Opus 4.8 handled the session. - Mythos 5 uses program-level governance, not session-level routing.
- EU AI Act enforcement begins August 2, 2026; the logging layer is the compliance gap for most teams.
If you’re building on Fable 5 and need help structuring your AI governance documentation, surfacing fallback events in your observability stack, or preparing for EU AI Act compliance before August, let’s chat.

