Kimmo Hakonen
Chief Innovation Officer
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 18, 2026
How to Use Claude Fable 5 in Drug Discovery Workflows

Drug discovery costs a median $708 million per approved drug (RAND, 2025), takes 10 to 15 years, and sees roughly 90% of clinical candidates fail before reaching patients. R&D teams carry those odds every time they open a new target file. Anthropic’s internal protein design team recently reported roughly 10x acceleration in drug design using Mythos 5, Fable 5’s unrestricted-access counterpart, which produced promising drug candidates for 9 of 14 protein targets tested (Anthropic, June 2026). Most published coverage attributes those results directly to Claude Fable 5. That conflation matters: Mythos 5 is the vetted-partner version; standard API teams get Fable 5, which still leads all published models on BioMysteryBench and GPQA Diamond biology/chemistry and covers hypothesis generation, literature synthesis, and target analysis workflows without restriction.
Key Takeaways
- Anthropic’s internal protein design experts reported ~10x acceleration using Mythos 5, which produced promising drug candidates for 9 of 14 protein targets tested (Anthropic, June 2026).
- In blinded comparisons, Anthropic scientists preferred Mythos 5 molecular biology hypotheses ~80% of the time over Opus-class models (Anthropic, June 2026).
- On BioMysteryBench (hard set), Fable 5/Mythos 5 scored 46.1% versus 40.0% for Opus 4.8 (Vellum.ai, May–June 2026); on GPQA Diamond, Fable 5 scored 94.1% (Anthropic, June 2026).
- R&D teams on the standard API get Claude Fable 5; Mythos 5 requires a separate Anthropic partnership agreement. Fewer than 5% of biology queries trigger the routing fallback (OnHealthcare.tech, June 2026).
- 173 AI-originated clinical programs are now in development; zero have received FDA approval (Axis Intelligence, 2026).
Why does drug discovery still take 10–15 years, and where does AI actually help?
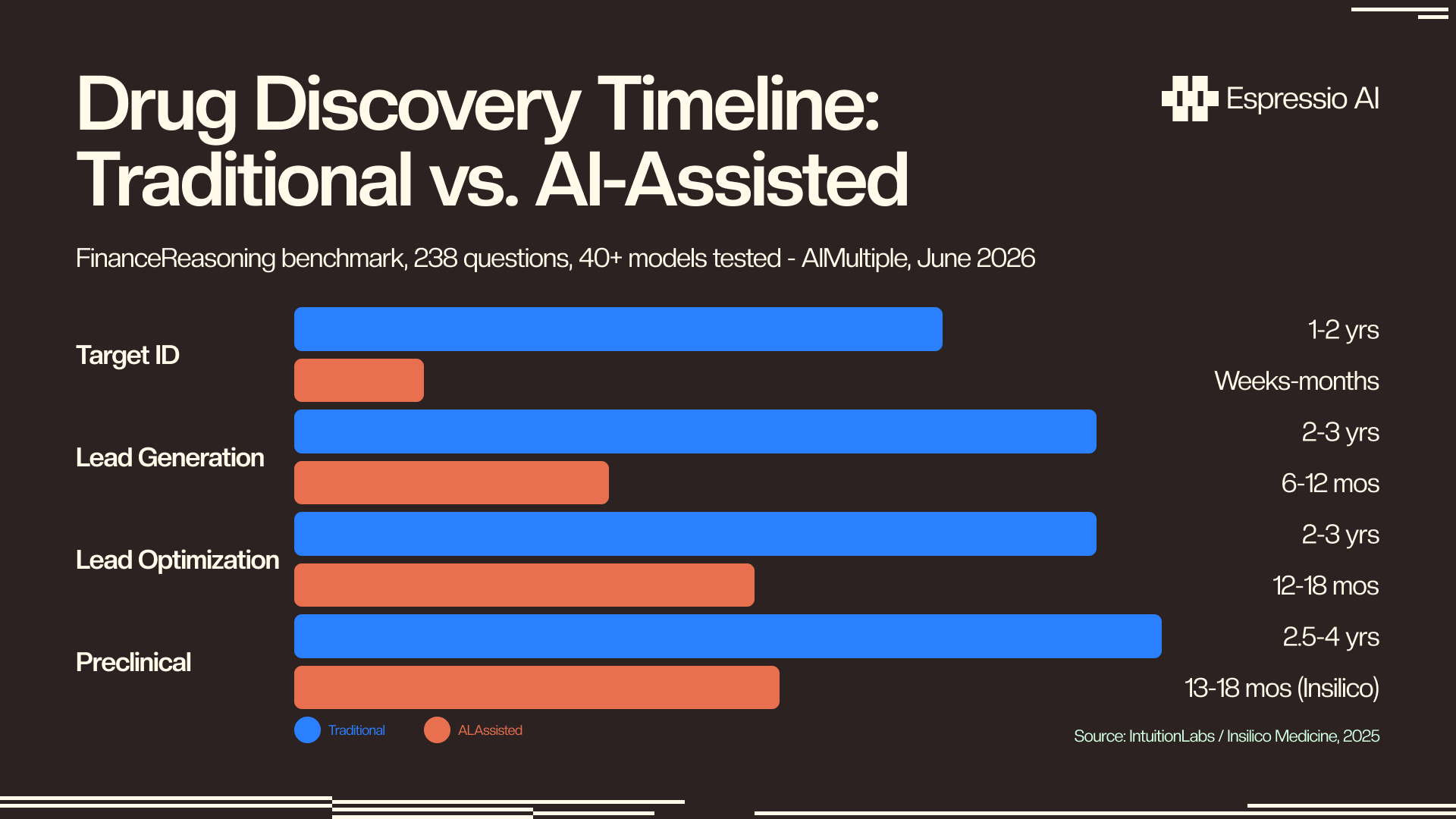
Drug discovery costs a median $708 million per approved drug (RAND, 2025) and takes 10 to 15 years, with roughly 90% of clinical candidates failing before approval. AI’s highest-value contribution is compressing the hypothesis-to-candidate cycle in early discovery (target identification and lead optimization) rather than replacing wet-lab validation.
The traditional pipeline moves through four stages: target identification, lead generation, lead optimization, and preclinical development. Time loss accumulates differently across each stage. Target identification and lead generation together consume 3 to 5 years of iterative hypothesis testing, with lead optimization adding another 2 to 3 years of structure-activity relationship work. Preclinical development runs 2.5 to 4 years before an IND filing. The pipeline is front-loaded with decisions that are hard to reverse.
Hypothesis generation is the first bottleneck AI addresses well. Most early-stage decisions depend on how thoroughly a team has synthesized the available literature for a given target. Manual literature synthesis for a novel target can take weeks. Fable 5 compresses that to hours when the workflow is structured correctly.
Insilico Medicine’s ISM001-055 project is the most-cited AI acceleration benchmark: a preclinical candidate in just under 18 months, versus a traditional three to six years, at a reported cost of $2.6 million versus the industry average (IntuitionLabs, 2025). That result used Insilico’s own specialized AI platform, not Fable 5. It establishes the ceiling of what AI-accelerated early discovery can deliver when the toolchain is purpose-built.
The honest baseline sits alongside that figure. 173 AI-originated clinical programs are now in development, and zero have received FDA approval (Axis Intelligence, 2026). The acceleration is real at the hypothesis-to-candidate stage. Clinical-stage attrition remains the same.
What is Claude Fable 5, and what is Mythos 5, and why does the distinction matter for R&D teams?
Claude Fable 5 is Anthropic’s flagship model, released June 9, 2026, available on the standard API. Claude Mythos 5 is the same underlying model with unrestricted biology and chemistry capabilities, available only to vetted partners. Fewer than 5% of biology sessions on the standard API trigger the routing fallback to Opus 4.8 (OnHealthcare.tech, June 2026).
The access split is structural. Standard API users get Claude Fable 5, which covers the full range of scientific reasoning, literature synthesis, and hypothesis generation. Mythos 5 access requires a separate Anthropic partnership agreement. That agreement involves vetting for research use case, institutional affiliation, and biosafety practices. The process takes time, and most commercial R&D teams won’t need it.
The Opus 4.8 fallback covers a narrow category of dual-use biosecurity edge cases: synthesis routes for hazardous compounds, gain-of-function research framing, and weapons-adjacent biology contexts. That is the scope. Target identification, protein target analysis, literature synthesis, hypothesis generation, biomarker work, and clinical data interpretation fall outside it; all run on Fable 5 without restriction.
Most published commentary on Fable 5’s drug discovery performance attributes the Mythos 5 results (10x acceleration, 9 of 14 protein targets, 80% blinded preference) directly to Fable 5. Those are ceiling figures from vetted partner access to Mythos 5. Standard API teams get Fable 5, which still leads all published models on BioMysteryBench and GPQA Diamond biology/chemistry, but the protein design acceleration numbers belong to Mythos 5 specifically. R&D teams evaluating the model on those figures should understand they’re looking at Mythos 5 results, not standard API performance.
Standard Claude Fable 5, available on the Anthropic API without a partnership agreement, covers hypothesis generation, literature synthesis, target analysis, and biomarker work for biopharma R&D teams. Fewer than 5% of biology sessions route to the Opus 4.8 fallback, and approximately 0.03% hit AI-development-specific restrictions (OnHealthcare.tech, June 2026). Most standard pharmaceutical research workflows run entirely on Fable 5.
For Claude API setup and Files API configuration, including persistent file ID handling and session management, see the Claude API setup guide for teams.
What do the benchmarks actually tell R&D teams about Fable 5’s biological reasoning?
On BioMysteryBench (hard set), Fable 5/Mythos 5 scored 46.1% (versus 40.0% for Opus 4.8 and 29.6% for Mythos Preview) (Vellum.ai, May–June 2026). On GPQA Diamond, Fable 5 scored 94.1% (Anthropic, June 2026). These two benchmarks are the most relevant to R&D teams evaluating the model for scientific reasoning tasks.
BioMysteryBench evaluates expert-level biology problem-solving. Tasks require multi-step inference across molecular biology, genetics, and biochemistry. The benchmark is specifically designed to penalize pattern-matching and surface-level recall; a model has to synthesize information across domains to reach a correct answer. The “hard set” designation means these are the most difficult items in the benchmark, filtered to remove questions where memorization alone can produce a correct response.
Scoring 46.1% on that hard set is meaningful in context. Opus 4.8, a strong general-purpose model, scored 40.0%; Mythos Preview scored 29.6%. The 6.1-point gap between Fable 5 and Opus 4.8 on expert-difficulty multi-step biology tasks is the signal R&D teams should focus on. It reflects the kind of reasoning quality that matters in hypothesis generation workflows where a model needs to connect findings across a literature set, not retrieve a known answer.
GPQA Diamond assesses graduate-level reasoning at a different level of abstraction. Fable 5’s 94.1% score on that benchmark reflects strong performance on structured scientific reasoning, though GPQA Diamond is less demanding than BioMysteryBench at the hard-set level.
Drug discovery workflows are multi-step, domain-specific, and context-dependent. Benchmark scores measure reasoning capacity under controlled conditions; the complex, document-dependent context of actual discovery work adds layers that controlled benchmarks don’t capture.
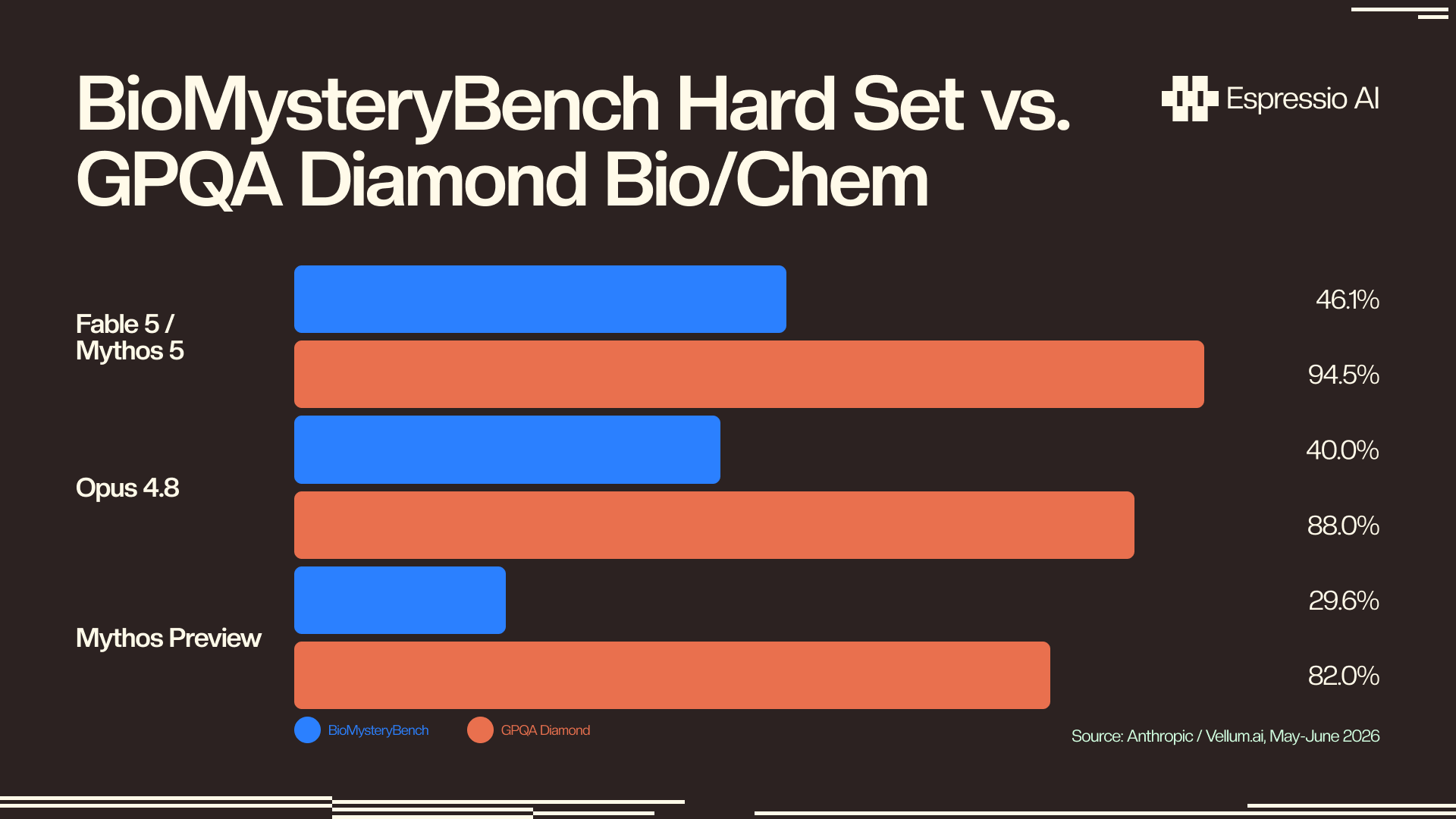
On BioMysteryBench (hard set), Fable 5/Mythos 5 scored 46.1%, ahead of Opus 4.8 at 40.0% and Mythos Preview at 29.6% (Vellum.ai, May–June 2026). On GPQA Diamond, Fable 5 scored 94.1% (Anthropic, June 2026). These scores reflect expert-level multi-step biological reasoning across molecular biology, genetics, and biochemistry: the reasoning profile most relevant to hypothesis generation workflows.
What does the 10x protein design acceleration claim actually mean for your team?
Anthropic’s internal protein design experts reported roughly 10x acceleration using Mythos 5, which produced promising drug candidates for 9 of 14 protein targets tested (Anthropic, June 2026). In blinded comparisons, Anthropic scientists preferred Mythos 5 molecular biology hypotheses approximately 80% of the time over Opus-class models. This acceleration is in the hypothesis generation and candidate identification cycle, not in wet-lab validation. Each candidate still requires experimental confirmation.
The 9 of 14 protein target result describes drug candidates that cleared initial AI-assisted screening, not clinical-stage compounds. “Promising” at this stage means the candidates passed a computational plausibility filter and were flagged for wet-lab follow-up. That’s still a meaningful output rate: 64% of targets producing screened candidates at a fraction of traditional timelines.
The 80% blinded preference methodology matters for interpreting the figure. Anthropic scientists evaluated hypothesis outputs without knowing which model generated them. Preferring Mythos 5’s output 80% of the time over Opus-class models is a strong signal on hypothesis quality, not just volume. The evaluators were internal protein design experts, not generalist reviewers.
Mythos 5 also ran an autonomous genomics task: assembling single-cell data spanning millions of cells across 138 animal species in more than a week, with a custom ML model that outperformed a recent Science publication at 100 times smaller model size (Anthropic, June 2026). That result demonstrates multi-step autonomous reasoning across large biological datasets, not just document synthesis.
For teams with standard Fable 5 access: the 10x figure is a Mythos 5 ceiling from a vetted partner environment. Fable 5 on the standard API delivers improved hypothesis quality over prior Claude models. The gains are real but the acceleration figure is not directly portable to a standard API deployment.
Running multi-paper synthesis prompts against Fable 5 for hypothesis generation work, the output depth shifts with how the system prompt is framed. “Surface novel hypotheses ranked by strength of evidence from the uploaded literature” produces substantially different output than “summarize these papers”: the former returns prioritized candidates with document citations and confidence qualifications; the latter returns a summary. Adding a researcher context note before the hypothesis request (covering the research team’s coverage track record, known blind spots, and the specific question under investigation) consistently reduces generic outputs and pushes the model toward the edges of the literature where the genuinely novel hypotheses sit.
These results came from Anthropic’s internal protein design team under Mythos 5 partner access, not standard API deployment. Standard API teams get Fable 5, which leads all published models on BioMysteryBench and GPQA Diamond but doesn’t include the protein design optimization layer built into Mythos 5 access (Anthropic, June 2026).
How do you structure a hypothesis generation workflow with Claude Fable 5?
Generative AI could unlock $60–$110 billion annually in economic value for the pharmaceutical and medical products sector (McKinsey Global Institute, 2023). The workflows that capture that value in early drug discovery share a consistent structure: document-grounded inputs, evidence-citation output requirements, and a researcher correction loop that feeds back into subsequent runs.
Three components determine whether a synthesis run returns useful hypothesis candidates or generic summary: how the document set is assembled, how the system prompt frames the task, and whether the researcher carries a correction log forward.
Start with document upload. Batch-upload the relevant literature set via the Files API: PubMed full-text PDFs, preprints, internal assay data. Each upload returns a persistent file ID reusable across runs without re-uploading. Build the document set around a specific target or mechanism, not a general disease area.
The system prompt frame drives output quality. Ask Fable 5 to “surface novel hypotheses ranked by strength of supporting evidence from the uploaded literature, with citations to specific document sections.” A synthesis-framed prompt produces grounded, citable output. A question framed as “what experiments should we run?” pushes toward generative territory where safety routing checks apply.
Before the hypothesis request, add 2 to 4 sentences on known domain constraints, prior experiment outcomes, and the specific question under investigation. This is what separates synthesis from generic summary. The model responds to the specificity of the constraint; broad context notes produce broad outputs.
Fable 5 returns ranked hypotheses with document citations. The researcher reviews, annotates corrections, and logs the reason: missing context, conflicting data, or framing error. This override log feeds back into the next run’s context note. Over 5 to 6 cycles on a single target, it becomes a calibration layer specific to the research area. The model doesn’t retain memory between sessions, but the context note carries forward the accumulated constraint history.
Framing the system prompt as “analyze published findings and identify gaps in the current evidence base” rather than “propose new experiments” consistently produces better-grounded outputs and reduces the likelihood of triggering safety routing. The published-findings frame anchors the model in the document set and keeps the output in the analysis register. The experimental-design frame pushes the model toward generative territory where safety checks apply, particularly for chemistry-adjacent targets.
R&D applications (hypothesis generation, target identification, lead optimization) represent the largest share of pharma GenAI value capture. Structured hypothesis workflows that pair document-grounded inputs with researcher correction loops are how teams actually capture it.
For Files API configuration for Claude, including persistent file ID management and multi-session document handling, see the Claude API setup guide.
What is the safety routing issue, and how should R&D teams work with it?
Claude Fable 5 routes a subset of biology and chemistry queries to Claude Opus 4.8 as a fallback. This applies to dual-use biosecurity edge cases, not standard research workflows. Fewer than 5% of biology sessions trigger the fallback, and approximately 0.03% of traffic hits AI-development-specific restrictions (OnHealthcare.tech, June 2026). For standard biopharma R&D, the practical impact is minimal.
Routing applies to a narrow category: hazardous compound synthesis routes, gain-of-function research framing, and weapons-adjacent biology contexts. These are the dual-use biosecurity edge cases the system is designed to address.
Target identification, protein structure analysis, literature synthesis, clinical data interpretation, biomarker hypothesis generation, and mechanism-of-action analysis all run on Fable 5 without restriction. Standard pharmaceutical R&D teams work primarily in this unrestricted category.
The Opus 4.8 fallback is a workable outcome for the cases where it applies. Opus 4.8 handles general scientific reasoning competently; it scores below Fable 5 on BioMysteryBench and GPQA Diamond, but provides useful output for the narrow edge cases that trigger routing.
The perception risk from safety routing coverage is larger than the operational reality. Media coverage has conflated all biology-related AI restrictions with the narrow dual-use biosecurity routing that affects approximately 0.03% of traffic. Most R&D teams running standard hypothesis generation, literature synthesis, and target analysis workflows won’t encounter routing in practice. Understanding this distinction matters when evaluating Fable 5 against specialized platforms: the routing limitation is real but affects a very small fraction of what standard biopharma teams actually do.
On the standard Anthropic API, Claude Fable 5 covers literature synthesis, hypothesis generation, target analysis, biomarker work, and mechanism-of-action reasoning without restriction; fewer than 5% of biology sessions route to the Opus 4.8 fallback, and roughly 0.03% of overall traffic hits AI-development-specific restrictions. Both figures are consistent with Fable 5 serving the large majority of standard pharmaceutical R&D workflows without interruption (OnHealthcare.tech, June 2026).
Teams building governance structure across AI deployments can apply the same correction-log principle to non-research workflows; see the AI workflow automation guide for revenue teams for a parallel framework covering validation loops and audit trails.
What does a production-ready biopharma AI workflow look like with Claude Fable 5?
GenAI could unlock $5 to $7 billion in total value for the life sciences industry, with pharma R&D capturing 30 to 40% of that total, making it the largest single category of AI value capture in the sector (Deloitte Life Sciences, 2025). A production-ready Fable 5 workflow captures that value through four layers: document ingestion, structured hypothesis generation, researcher validation, and governance.
Document ingestion starts with the Files API for persistent literature sets: PubMed full-text PDFs, internal assay data, ClinicalTrials.gov reports, competitive intelligence. File IDs persist across sessions; re-upload only when the document set changes. Structure the ingestion by target or mechanism, not disease area. Broad document sets produce broad outputs.
Structured hypothesis generation uses the same system prompt pattern from the previous section: evidence-citation requirements, researcher context note, confidence qualifiers. The prompt structure is the lever; the document set is the constraint.
Researcher validation is the layer most teams skip and most regret skipping. Log every Fable 5 hypothesis the researcher overrides, with a reason code: missing context, conflicting data, or interpretation error. The correction log feeds back into the next run’s context note and becomes a durable calibration asset for the research area over time.
Governance determines whether the workflow survives regulatory review. Log the model version on every AI-assisted output used in a research decision, maintain a source-cited audit trail covering which documents grounded each hypothesis, and keep a clear boundary between AI hypothesis generation and researcher experimental design decisions.
On cost: Fable 5 runs at $10 per million input tokens and $50 per million output tokens on the standard API. A 15-paper literature synthesis run costs cents at API rates versus hours of manual extraction. The economic argument for structured AI hypothesis generation in early discovery is straightforward at those figures.
The question of when to escalate to Mythos 5 access is simpler than it sounds. Most commercial R&D teams running literature synthesis, hypothesis generation, and target analysis workflows don’t need it. Mythos 5 access is worth pursuing when the research genuinely requires unrestricted synthesis work on chemistry-adjacent targets where the standard routing would apply to core workflow tasks. That’s a narrow set of use cases.
The Insilico Medicine result is the ROI anchor for AI-accelerated early drug discovery. Insilico used a purpose-built AI platform applied across hypothesis generation, lead identification, and lead optimization, not a single language model. Fable 5 addresses the hypothesis generation layer of that pipeline; the full result required a broader toolchain.
The Insilico Medicine IND result establishes the ROI ceiling for AI-accelerated early discovery and anchors the business case for structured AI workflows in pharmaceutical R&D (IntuitionLabs, 2025). A purpose-built AI platform spanning multiple pipeline stages drove that result. Fable 5 addresses the hypothesis generation layer; realistic expectations for compression should reflect that scope.
See how IMC evaluated Claude Fable 5 for institutional deployment for a four-dimension scoring framework that maps directly to life sciences contexts. For analyst workflow automation with Claude Fable 5, the parallel workflow guide covers pipeline architecture.
Next steps
If your R&D team is evaluating Claude Fable 5 for hypothesis generation or literature synthesis, scope which workflows fit within Fable 5’s standard access tier first. Most do. Reserve the Mythos 5 partnership conversation for cases where your research genuinely requires unrestricted synthesis work.
IMC’s four-dimension evaluation framework (factual lookup, conceptual reasoning, root-cause analysis, expected-value analysis) translates directly to a life sciences context. Replace expected-value analysis with mechanism-of-action plausibility, and you have a scoring template for testing Fable 5 against your own literature set before committing to production deployment.
For parallel deployment patterns in a different domain, see multi-source document reasoning with Claude Fable 5.
If you want us to build this for your team, let’s chat.
Frequently Asked Questions
Does Claude Fable 5 require Anthropic’s Mythos 5 access for drug discovery work?
Standard Claude Fable 5 API access covers the majority of biopharma R&D workflows without triggering the routing fallback. Fewer than 5% of biology sessions route to Opus 4.8, and roughly 0.03% of traffic hits AI-development-specific restrictions (OnHealthcare.tech, June 2026). Literature synthesis, hypothesis generation, target analysis, and biomarker work all run on standard Fable 5.
How does Claude Fable 5 compare to Schrödinger or BioNeMo for drug discovery?
They serve different functions. Schrödinger and BioNeMo run physics-based molecular simulation and structure prediction; Fable 5 synthesizes scientific literature, generates ranked hypotheses from document sets, and assists with mechanism-of-action reasoning. Teams running both route simulation work to specialized platforms and document-heavy hypothesis generation to Fable 5, treating them as complementary layers in the same discovery pipeline.
What is BioMysteryBench, and what does a 46.1% score mean for R&D teams?
BioMysteryBench evaluates expert-level biology reasoning across molecular biology, genetics, and biochemistry (tasks that require multi-step inference, not recall). On the hard set, Fable 5/Mythos 5 scored 46.1% versus Opus 4.8’s 40.0% (Anthropic/Vellum.ai, May–June 2026). The 46.1% reflects a meaningful lead on expert-difficulty tasks; it’s the highest published score on this benchmark.
How do you prevent Claude Fable 5 from triggering the biology safety routing?
Frame queries in the context of published literature analysis rather than experimental design generation. Requests framed as “analyze published findings and surface supported hypotheses” stay on Fable 5; requests framed as “design a synthesis route” or “propose gain-of-function modifications” are more likely to trigger routing. The fallback affects fewer than 5% of biology sessions in practice (OnHealthcare.tech, June 2026).
What is the ROI case for using Claude Fable 5 in early-stage drug discovery?
Insilico Medicine delivered a preclinical candidate in just under 18 months versus the traditional three to six years, at $2.6 million versus the industry average (IntuitionLabs, 2025). That result used a specialized AI platform rather than Fable 5 alone, and it establishes the value range. GenAI could unlock $60-$110 billion annually across pharma and medical products (McKinsey, 2023).