Kimmo Hakonen
Chief Innovation Officer
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 18, 2026
How Trading Desks Use Claude Fable 5: What IMC's Evaluation Found
IMC, a major global proprietary trading firm and market maker, reported that Claude Fable 5 “aced their trading-analysis evaluations nearly across the board” across factual lookup, conceptual reasoning, root-cause analysis, and expected-value analysis (Anthropic, June 2026). That’s an unusually direct endorsement from a firm that trades billions of dollars daily across equities, options, fixed income, and derivatives globally.
Most trading desks aren’t short of AI tools. They’re short of a framework for knowing which tasks actually reward the investment in a frontier model and which tasks a cheaper extraction tool handles well enough. The IMC evaluation gives that framework a starting point.
Key Takeaways
- IMC reported that Claude Fable 5 “aced their trading-analysis evaluations nearly across the board” across factual lookup, conceptual reasoning, root-cause analysis, and expected-value analysis (Anthropic, June 2026).
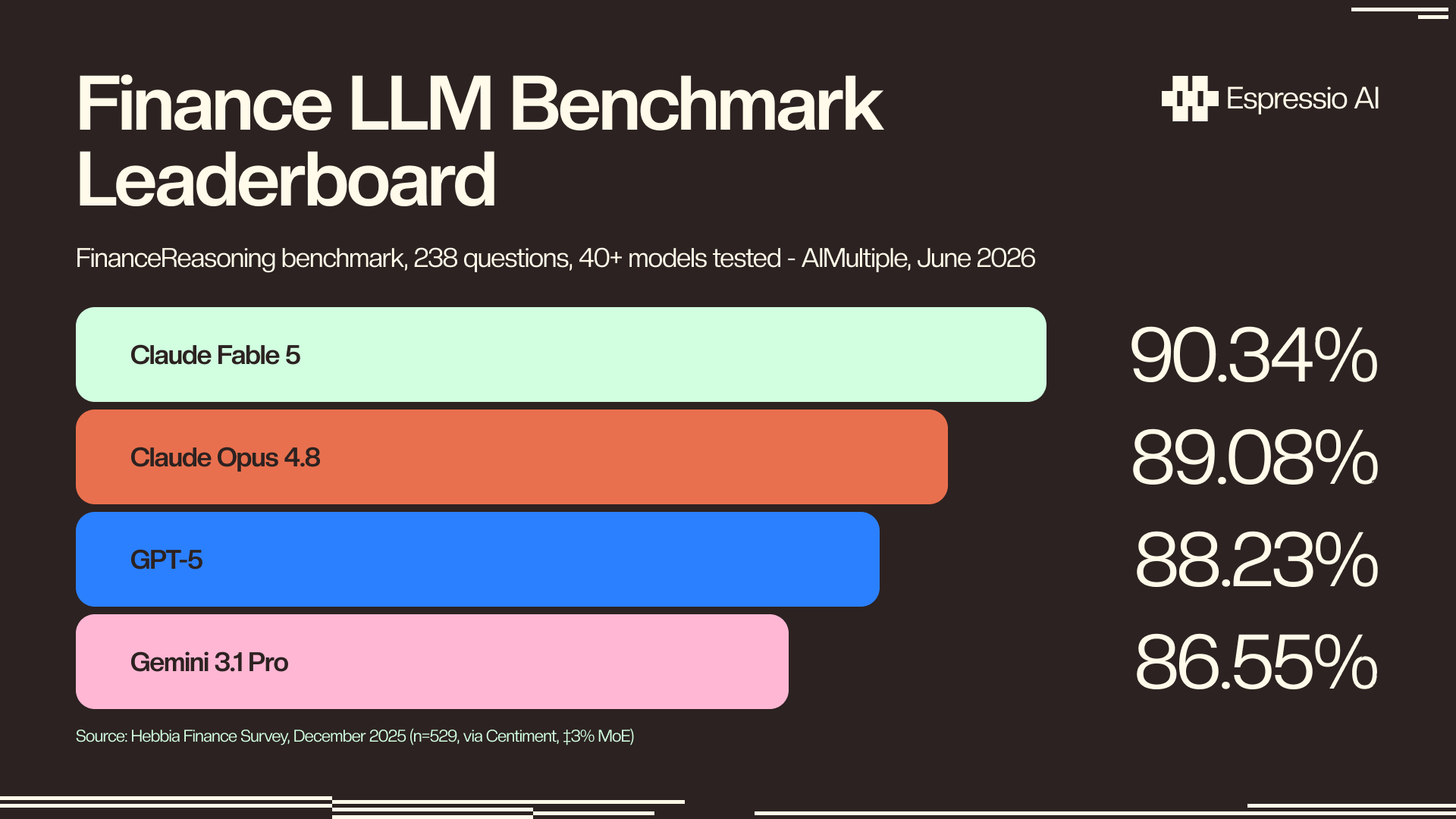
- Fable 5 is the first model to break 90% on the FinanceReasoning benchmark (90.34%), ahead of GPT-5 at 88.23% and Gemini 3.1 Pro Preview at 86.55% (AIMultiple, June 2026).
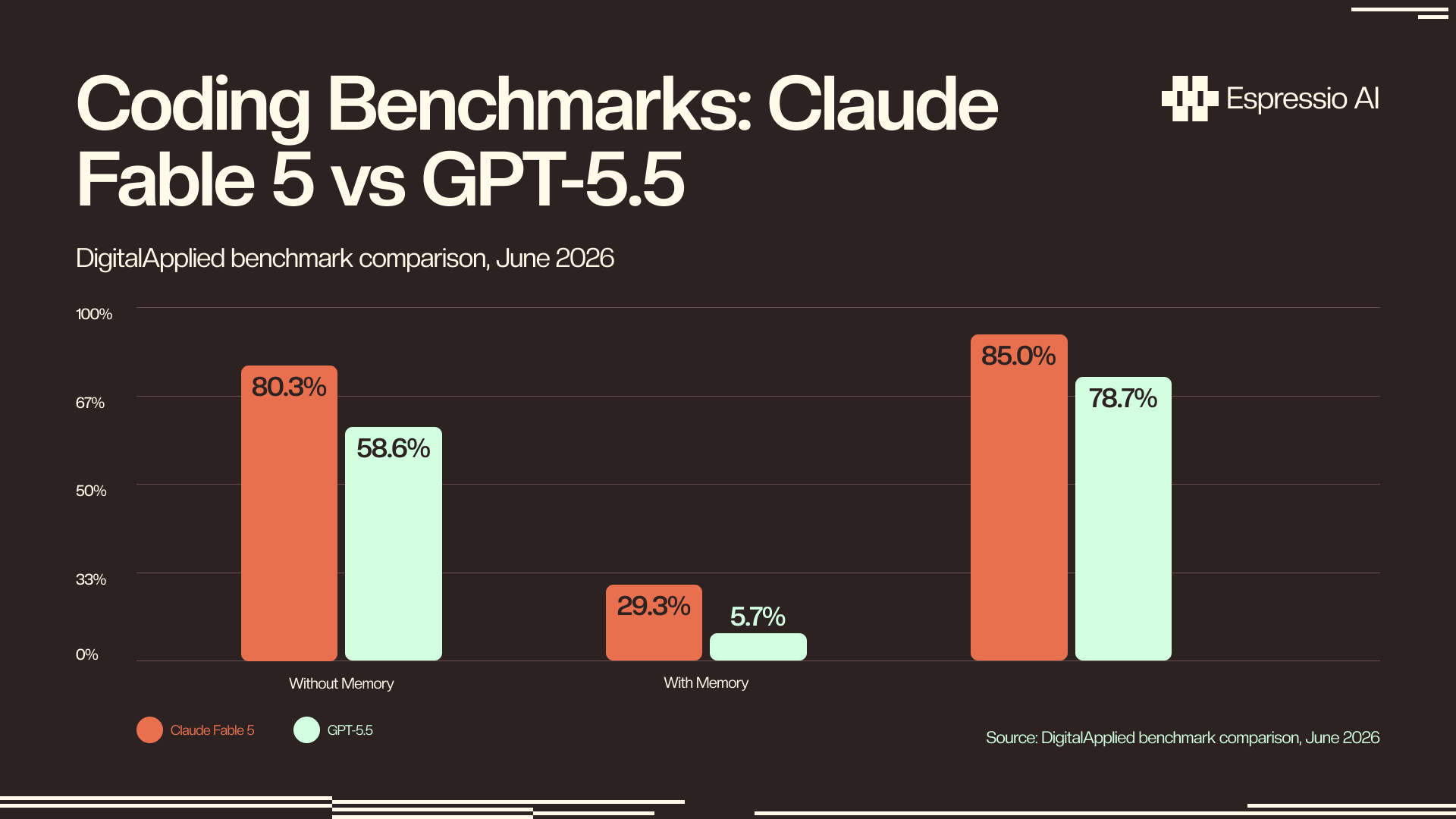
- On SWE-bench Pro (the coding benchmark most relevant for quant strategy development), Fable 5 scored 80.3% versus GPT-5.5’s 58.6% (DigitalApplied, June 2026).
- The key differentiator IMC flagged is long-horizon task completion: Fable 5 finishes extended analysis chains in a single pass with fewer abandoned attempts than prior Claude models.
- Nearly 85% of firms plan to increase AI use in bond trading in 2026, up from 57% in 2024 (LTX / The TRADE, January 2026).
What did IMC evaluate when they tested Claude Fable 5 on the trading desk?
IMC’s evaluation covered four trading-analysis dimensions: factual lookup, conceptual reasoning, root-cause analysis, and expected-value analysis (Anthropic, June 2026). Fable 5 passed all four. That result carries weight because of what the four dimensions actually test in practice.
Factual lookup tests whether the model retrieves specific data points from market research documents accurately, without hallucinating numbers or misattributing sources. Get that wrong and every downstream analysis is unreliable. Conceptual reasoning goes a level deeper: understanding why a correlation holds, what a spread signals, how a rate move propagates across instruments, or why a sector rotation is occurring.
Root-cause analysis works backward. Given unusual price behavior or a system anomaly, the model identifies candidate explanations by working through a document set rather than guessing from priors. Expected-value analysis structures trade scenarios as probability-weighted outcomes given known constraints, drawing on information in the document set.
Completion rate on extended chains is the most operationally important finding from IMC’s evaluation. Prior Claude models abandoned multi-step analysis partway through; Fable 5 finishes those chains in a single pass with fewer abandoned attempts. Completion rate determines whether a multi-step workflow can be built around a model at all, and for production trading desk use that’s the question that matters most.
Cognition, in the same Anthropic announcement, cited Fable 5’s FrontierCode Diamond lead as the benchmark result most relevant to their software engineering work. Hebbia cited Fable 5’s Finance Benchmark document reasoning performance across chart interpretation and multi-step problem-solving. Three separate evaluations from distinct firm types all point toward the performance gains being real rather than artifacts of any single test design.
How does Claude Fable 5 score on the finance and coding benchmarks that matter for quant desks?
Fable 5 is the first model to break 90% on the FinanceReasoning benchmark, scoring 90.34% across 238 questions tested on 40+ LLMs (AIMultiple, June 10, 2026). GPT-5 sits at 88.23% and Gemini 3.1 Pro Preview at 86.55%. A two-point gap at that accuracy ceiling is meaningful.
FinanceReasoning tests financial arithmetic, ratio calculations, financial statement interpretation, and multi-step reasoning under numerical constraints. It runs as a Chain-of-Thought evaluation with 0.2% numerical tolerance. It’s the closest published comparison across current frontier models for finance-specific reasoning, though it doesn’t cover every trading workflow.
The coding benchmarks are where the quant developer picture gets sharper. On SWE-bench Pro, Fable 5 scored 80.3% versus GPT-5.5’s 58.6% (DigitalApplied, June 9, 2026). That’s the benchmark most relevant to quant strategy work: it tests whether a model produces working code from realistic software engineering tasks, which maps directly to writing backtesting frameworks, signal generation code, data pipeline scripts, and portfolio optimization tooling.
FrontierCode Diamond is harder. Fable 5 scored 29.3% versus GPT-5.5’s 5.7% on advanced code completion. The absolute numbers look low because FrontierCode Diamond selects genuinely difficult tasks, but the relative gap is substantial at more than five times GPT-5.5’s score.
For quant developers, the SWE-bench Pro result matters most practically. A model that produces working Python 80% of the time on realistic engineering tasks generates far fewer review-and-fix cycles than one sitting at 58%. That difference compounds fast over an active strategy development sprint.
Which trading desk tasks should Claude Fable 5 handle, and where do other models still compete?
Fable 5 leads on synthesis and reasoning across multi-source documents, but fully autonomous trading workflows remain out of reach for all current models. Financial modeling accuracy peaks at 23% across every model tested on Vals AI’s Finance Agent v2 (Vals AI, May 2026). The useful framework is task routing based on task type and cost per token.
Fable 5 earns its cost on these task types: multi-source research synthesis covering earnings transcripts, sell-side notes, 10-K filings, and management commentary in a single context window; expected-value scenario modeling; root-cause hypothesis generation from document evidence; strategy code generation; and backtesting framework scaffolding. These are tasks where synthesis quality matters more than cost per token.
GPT-5 and GPT-4.1 are competitive on bulk field extraction from structured documents, where cost per token matters more than synthesis depth. EBITDA figures, covenant terms, data normalization tasks, and structured field extraction at high volume are good candidates. The routing decision is economic: Fable 5 on the synthesis layer, a lower-cost model on the extraction layer.
The 23% financial modeling ceiling across all models places AI’s strongest value in research acceleration, code scaffolding, document analysis, and first-pass synthesis. Fully autonomous model construction remains out of reach for every current LLM, and execution stays with the analyst.
More than 80% of enterprise data is unstructured (Gartner estimate, via BizTech, 2025). That’s why LLMs surface more value in document-heavy synthesis tasks than in structured data operations. Your desk probably has more unstructured research sitting in inboxes and shared drives than you’ve ever routed through a model. Finance teams in adjacent verticals run the same routing model with similar results. For how that plays out in a financial operations context, AI agent-driven accounting automation for crypto finance teams covers a parallel deployment architecture.
On Vals AI’s Finance Agent v2, financial modeling accuracy peaks at 23% across all models tested (Vals AI, May 2026), establishing the clearest current limit of AI in trading workflows. The compounding gains on the trading desk come from directing AI at document reasoning, synthesis, and strategy code, with execution judgment staying with the analyst.
How do you build a root-cause analysis workflow with Claude Fable 5?
Root-cause analysis is one of the four dimensions IMC evaluated, and it’s the trading desk workflow most immediately deployable through direct API access. Fable 5 scored 90.34% on FinanceReasoning, the benchmark that most directly tests multi-step reasoning over financial documents (AIMultiple, June 2026). The question a root-cause workflow answers: why did this position move?
Start with the document upload. Batch-upload the relevant document set via the Files API. For a single-name root-cause run, this typically covers the last two to four earnings transcripts, sell-side research from the past quarter, and the most recent annual report sections on management guidance and risk factors. Each upload returns a persistent file ID you reuse across runs without re-uploading.
The system prompt frame matters more than most teams realize. Asking Fable 5 to “predict price direction” produces hedged output that’s hard to act on. Asking it to “surface candidate hypotheses for the observed move, with evidence from the uploaded documents, ranked by strength of supporting evidence” produces something an analyst can actually work with. The frame shapes the output format, the level of sourcing, the confidence tone, and the specificity of citations.
Add a brief analyst context note before the hypothesis request. Two to four sentences covering the company’s guidance reliability track record, relevant sector dynamics, prior analyst concerns that went unaddressed, and any known management communication patterns. This is what most separates useful synthesis from generic document summary. The model can’t know what it hasn’t been told.
Fable 5 returns ranked hypotheses with source citations. Each hypothesis includes the specific document section supporting it, along with a stated confidence qualifier. The analyst reviews, scores each hypothesis, and logs any corrections.
Running this workflow across earnings seasons reveals a consistent pattern. The model handles factual retrieval accurately: management guidance changes, named risks, capital allocation language, and revenue outlook shifts come through correctly from the uploaded documents. It’s weaker on credibility signals where the relevant context is the analyst’s own memory of prior quarters, specifically how many times this management team has guided conservatively, or whether they’ve missed their own targets before. The calls that generate corrections share this characteristic: the analyst holds context the document doesn’t carry. Adding a two-sentence analyst note before each run (prior guidance track record, known blind spots) reduces those corrections noticeably.
The correction log from step five feeds back into the next run as a refined context note. Over five or six cycles on a single name, this becomes a calibration layer specific to that position. The outputs improve, and you’re also building a document of what the model gets wrong for this particular company, which becomes a durable asset for that research coverage.
For the document pipeline structure, including how the Files API handles multi-document persistence and the earnings call workflow architecture, Hebbia Finance Benchmark results and document reasoning workflows covers that in detail.
For Claude API setup and initial Files API configuration, Claude API setup and Files API configuration covers the integration steps.
What does a governance layer look like for AI-assisted trading decisions?
Regulatory oversight of AI in trading is moving from optional to expected, with nearly 85% of firms already planning expanded AI use in bond trading in 2026 (LTX / The TRADE, January 2026). Four elements cover the minimum viable governance layer: model version logging, override records, an explicit boundary for where AI output stops and analyst decision begins, and an audit trail that links each AI-assisted output to the analyst who reviewed it.
Model version logging means every Fable 5 output used in a trading decision gets tagged with the model version and system prompt version that produced it. If an AI-assisted analysis is ever questioned in a compliance review, the version log answers “which model, under what instructions” directly. That’s a one-field addition to your existing trade decision log.
Override logging records every analyst correction to a Fable 5 output, with a brief reason code: factual error, missing context, interpretation difference, or insufficient sourcing. Over twenty or thirty cycles, this log is simultaneously a model calibration resource and a regulatory evidence trail. The pattern for override logging in due diligence pipelines applies here without modification.
The EV analysis boundary is where governance becomes most important for trading specifically. Fable 5 can structure expected-value calculations and surface probability-weighted trade scenarios. The execution decision, whether to take the trade and at what size, stays with a named analyst. The system prompt should state this boundary explicitly, and the workflow should log the analyst name alongside each AI output used in the final decision.
The IMC evaluation framework is worth treating as a model-agnostic scoring template, reusable beyond its original benchmark context. Most coverage of Fable 5’s trading desk performance reports the outcome. The four dimensions IMC used (factual lookup, conceptual reasoning, root-cause analysis, expected-value analysis) are a scoring rubric any trading desk can run internally before committing to a production deployment. Write four test scenarios, one per dimension, using real documents from your own desk. Score the outputs on accuracy and completion rate. The result gives you a deployment confidence level calibrated to your document types and your question patterns, rather than a general benchmark population.
For the broader organizational governance layer across AI workflow deployments, covering ownership, escalation, and measurement across teams, strategic framework for AI workflow automation covers that in detail.
How fast is the trading desk AI adoption window closing?
Nearly 85% of firms plan to increase AI use in bond trading in 2026, up from 57% in 2024 (LTX / The TRADE, January 2026). That 28-point jump in a single year represents a market that’s past the evaluation phase and into production deployment.
95% of fund managers now use generative AI, up from 86% in 2023 (AIMA, September 2025, n=150, $788B AUM). The shift from 86% to 95% represents full-market saturation; differentiation is no longer about adoption but depth of integration. The teams pulling ahead are building structured workflows and accumulating calibration data from their override logs. At 95% adoption, workflow depth is the differentiator.
Teams reporting productivity gains on quant workflows in 2025 averaged 20 to 30% improvement on coding and analytics tasks (BizTech, March 2025, Quant Strats conference). These gains compound through calibration. Teams running structured workflows today are accumulating override logs, prompt refinements, document-type-specific calibration data, and coverage-specific context notes. A team that starts in twelve months starts from scratch on all of it.
90% of institutional investors believe generative AI will positively impact fund manager performance over the next three years (AIMA, September 2025, n=18 institutional investors). That figure reflects allocation-level conviction from the entities that control where capital moves.
For broader analyst productivity workflows across the deal cycle, including benchmarks covering multi-step document analysis tasks, analyst workflow automation with Claude Fable 5 covers that angle.
Frequently asked questions
Does Claude Fable 5 work with Bloomberg Terminal or live market data feeds?
Claude Fable 5 and Bloomberg Terminal serve different functions. Bloomberg delivers live market data feeds and price discovery; Fable 5 processes documents you already have. The practical workflow exports structured Bloomberg data first, then uploads it via the Files API for Fable 5 to analyze, synthesize, and reason across alongside research documents and earnings transcripts.
What did IMC find that other models couldn’t deliver on their evaluation?
IMC identified two differentiators. Fable 5 completed the expected-value analysis dimension with higher reliability than prior models, and it finished extended multi-step analysis chains in a single pass with fewer abandoned attempts. That long-horizon completion quality matters most for trading workflows where a mid-chain failure means restarting the analysis from scratch.
How does Claude Fable 5 compare to GPT-5 for quant strategy coding?
On SWE-bench Pro, the coding benchmark most relevant for quant strategy development, Claude Fable 5 scored 80.3% versus GPT-5.5’s 58.6%, a 21-point gap (DigitalApplied, June 2026). On FrontierCode Diamond, which tests more advanced code completion, Fable 5 scored 29.3% versus GPT-5.5’s 5.7%.
What is the right model for a small trading desk versus a large one?
Team size doesn’t change the routing logic; task type does. Fable 5 handles multi-source synthesis, EV reasoning, and strategy code generation regardless of desk size. Lower-cost models handle bulk field extraction from structured documents. A two-person desk and a 50-person desk run the same routing decision; volume changes, the task taxonomy doesn’t.
What is expected-value analysis with Claude Fable 5, and how does it work in practice?
Expected-value analysis with Fable 5 structures trade hypotheses as probability-weighted scenarios against known information in the document set. The system prompt defines the scenario frame (position sizing, risk constraints, time horizon), and the model surfaces EV calculations with explicit assumptions and source citations. Final execution decisions remain with the analyst.
Next steps
IMC’s four-dimension evaluation framework is a practical scoring template any trading desk can use before committing to a production deployment. Run four test scenarios against your own documents, one per dimension, and score on completion rate and accuracy. The result is a deployment confidence level specific to your document types and question patterns.
Fable 5’s leads on FinanceReasoning (90.34%, first model to break 90%) and SWE-bench Pro (80.3% vs 58.6%) reflect specific advantages for the two workflows with the clearest trading desk payoff: finance reasoning and strategy code generation. Those two workflows are also the most straightforward to pilot before committing to a full desk deployment.
The governance layer takes one additional implementation step and makes every AI-assisted output defensible to a compliance review. It covers model version logging, override records, an analyst-linked audit trail, and an explicit EV decision boundary. Build it before you need it rather than retrofitting it after a compliance question arrives.
If you want us to build this for your team, let’s chat.