Kimmo Hakonen
Chief Innovation Officer
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 17, 2026
How to Use Claude Fable 5 for Financial Analysis: Hebbia Benchmark Results and Real Workflows

Sixty-three percent of finance professionals now save six or more hours every week on analysis tasks with AI. That figure comes from a survey of deal-focused professionals at hedge funds, private equity firms, and investment banks (Hebbia, December 2025). The profession has been automating research tasks for two years, and the gap between teams doing it well and teams still wrestling with document volume is widening.
Two frictions keep most teams from compounding those gains. Document volume remains overwhelming for 46% of finance professionals, and the trust question (whether AI outputs are accurate enough for a partner, a client, or a regulator) still holds teams back from committing workflows to production.
Key Takeaways
- Claude Fable 5 achieved the highest score of any model on Hebbia’s Finance Benchmark for senior-level reasoning across 600+ workflows (Anthropic, June 2026).
- On Vals AI’s Finance Agent v2, which tests 450 agentic tasks with live tools including SEC EDGAR, calculator, and web search, no model cleared 58%. Fable 5 scored 56.31%, narrowly behind Gemini 3.5 Flash at 57.86% (Vals AI, May 2026).
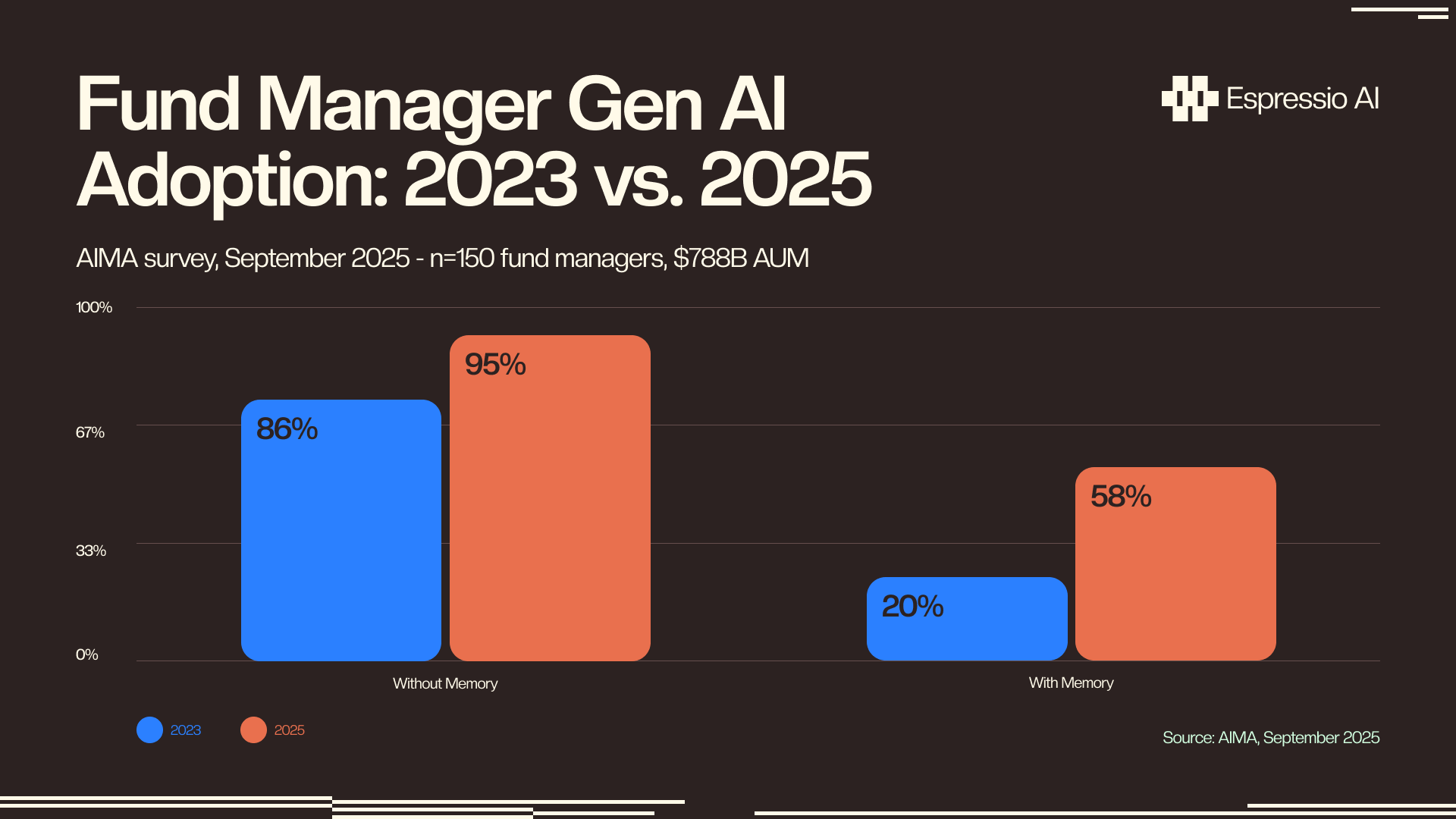
- 95% of fund managers now use generative AI, up from 86% in 2023; 58% expect to increase AI use in their investment process within the year (AIMA, September 2025, n=150, $788B AUM).
- Financial modeling peaks at 23% accuracy across all models on Vals AI’s benchmark; no current LLM does autonomous financial modeling reliably. Fable 5’s lead is in document-based senior reasoning.
- The earnings analysis and due diligence workflows below are production-ready using Fable 5’s Files API, structured JSON output, and an override log that doubles as a regulatory audit trail.
Why do finance teams still lose most of their week to document work despite having AI?
Ninety-three percent of finance professionals use or are actively evaluating AI, yet only 25% have fully integrated it into their workflows (Hebbia, December 2025). The gap between experimenting and compounding is the document-volume problem. A CIM arrives as a 120-page PDF. Earnings transcripts stack up across four quarters, and credit memos, legal agreements, management accounts, and board decks arrive simultaneously for a live deal. Single-file LLM uploads address one document at a time; multi-source aggregation is the actual constraint.
Forty-six percent of finance professionals report being overwhelmed by document volume, and 46% struggle specifically with extracting information across multiple sources at once (Hebbia, December 2025). Those two figures point at the same root cause: the 63% saving six or more hours weekly are the teams that built workflows to aggregate across sources.
The trust question resolves when source grounding is present. Practitioners who structure workflows around constrained extraction against specific documents report far higher confidence in outputs than those using open-ended generation against general context. Source citation is architecture: every financial analysis workflow should require the model to cite the specific document section it drew from.
For teams still working through which workflows to prioritize first, the prioritization matrix for revenue team workflows covers the sequencing framework before committing to a specific stack.

What do the Hebbia and Vals AI benchmarks actually tell you about Fable 5 in finance?
Two benchmarks test financial AI from different angles, and they tell different stories. Hebbia’s Finance Benchmark covers 600+ real workflows across investment banking, private equity, credit, and public equities, categorized into extraction, summarization, and senior-level reasoning tasks (Hebbia, 2025). On that benchmark, Claude Fable 5 achieves the highest score of any model for senior-level reasoning (Anthropic, June 2026). The Vals AI Finance Agent v2 measures something structurally different: 450 agentic tasks at 2nd–3rd year IB analyst depth, using six live tools including SEC EDGAR, a financial calculator, web search, HTML parser, document retrieval, and price history APIs (Vals AI, May 2026). On that benchmark, Gemini 3.5 Flash scores 57.86%, Claude Fable 5 scores 56.31%, and Claude Opus 4.8 scores 53.92%. No model clears 58%.
The benchmark’s three categories reveal where each model earns its spot. Extraction tasks (CIM field capture, covenant review, structured data normalization) favor Claude Opus and GPT-4.1, which handle high-volume repetitive extraction at lower cost. Summarization tasks (earnings call synthesis, management commentary distillation) favor o3 and GPT-5. Senior-level reasoning tasks (valuation challenges, strategic risk flag generation, competitive positioning across mixed qualitative and quantitative sources) favor Fable 5.
The practical implication is model routing, and no competitor article has made this distinction explicit. Fable 5’s lead on the Hebbia benchmark applies specifically to the reasoning category. GPT-4.1 remains competitive on extraction at lower cost. Routing all document work through a single model sacrifices either performance on reasoning tasks or cost efficiency on extraction tasks. The decision framework: Fable 5 for synthesis and senior-level reasoning on documents you already have; a lower-cost extraction model for bulk field capture; an agentic approach when the task requires live tool use and autonomous research.
The Vals AI financial modeling result is the honest number most coverage buries. Financial modeling peaks at 23% accuracy across all models (Vals AI, May 2026). Document Q&A and research synthesis score far higher across the same benchmark, which aligns with what practitioners observe in real workflows. Teams reporting compounding productivity gains direct AI at document reasoning and research synthesis, keeping financial modeling under analyst control.
For the Hex analytics benchmark comparison and general analyst workflow context, analyst workflow automation with Fable 5 covers that angle in detail.
Which financial tasks should Claude Fable 5 own — and where do other models compete?
Generative AI could lift investment banking front-office productivity 27–35%, with banking roles standing to gain most at 34% (Deloitte, 2023). The AIMA survey confirms the shift is already underway: 95% of fund managers now use generative AI, up from 86% in 2023, and 58% plan to increase use in their investment process within the year, up from 20% in 2023 (AIMA, September 2025, n=150, $788B AUM). Sixty percent of institutional investors say they’re more likely to allocate to hedge funds with meaningful generative AI budgets (AIMA, September 2025).
Fable 5’s strongest territory is multi-document synthesis: quarterly filing comparisons, strategic risk flag generation from mixed qualitative and quantitative data, valuation narratives, earnings transcript cross-referencing across multiple quarters, and competitive positioning analysis spanning several sources in a single context window. GPT-4.1 remains competitive for single-document field extraction (EBITDA, revenue growth, customer concentration, debt covenants, working capital metrics) where processing volume and cost per run matter more than synthesis quality. o3 handles complex modeling tasks where the reasoning chain structure itself is part of what the analyst needs to see.
Junior bankers handling 2–3× more live deals simultaneously is the downstream result when document processing shifts to AI, with top performers reporting 20 or more hours saved per deal cycle. AIG’s deployment of Claude demonstrates production-scale impact: a 5× compression in underwriting timeline and data accuracy rising from 75% to above 90% (Anthropic, July 2025).
How do you build an earnings call analysis workflow with Claude Fable 5?
AI has compressed mid-market acquisition document review from 6–8 weeks to 10–14 days, reducing manual review time by up to 70% on structured document-heavy phases (Thomson Reuters, 2025). Hebbia serves one-third of the top 50 asset managers globally, and their deployed workflows show a 95% reduction in response time when prompt caching is active (Anthropic, 2025). That response time compression is what makes deal-volume scaling possible without proportional headcount growth.
The earnings call analysis workflow below is production-ready. It assumes API access to Claude and an output destination (Notion, Google Sheets, or a deal CRM).
Step 1. Upload the earnings call transcript via the Files API. The file persists for 30 days, reusable across multiple analysis runs without re-uploading or re-processing costs.
Step 2. Set a system prompt defining the structured JSON extraction schema: revenue guidance (current quarter and forward), management tone shift markers (language change relative to prior call), competitive references (named competitors and context), forward-looking risk language, and capex signals.
Step 3. Fable 5 returns structured JSON. An n8n or Make.com webhook writes the output to the deal team’s Notion workspace or Google Sheets tracker.
Step 4. The analyst reviews flagged items, not the full transcript. Each flagged item gets a binary confirmation or override. Overrides require a one-line reason code.
Step 5. Analyst-approved output populates the earnings notes section of the deal CRM. The override log updates the prompt context for the next quarter’s transcript run.
Running 20+ earnings calls through this workflow reveals a consistent pattern. The model handles factual extraction reliably: guidance changes, named risks, capital allocation shifts come through accurately. It is weaker on management credibility signals where the relevant context lives in the analyst’s memory from prior quarters, a history that the uploaded transcript can’t provide. The calls that generate corrections share this characteristic: the analyst holds context the document doesn’t carry. In the next iteration, prime each run with a brief analyst context note before processing begins: what this management team has said before and whether their guidance has proven reliable.
Reading a 75-page CIM and extracting 12 key fields takes a skilled analyst 2–3 hours per document. This workflow reduces that to reviewing the flagged items. For the pipeline orchestration layer connecting transcript processing to downstream tools, n8n competitive intelligence automation covers the workflow architecture in detail.
How do you build a due diligence document pipeline with Claude’s Files API?
Forty-seven percent of US banks now run generative AI in production, up from 10% in 2023 (EY-Parthenon, 2025). The shift is concentrated at the document pipeline layer, where persistent document storage and batch processing create the most compounding efficiency gains. The Files API is built for both: persistent document storage and batch processing at deal volume.
The due diligence pipeline recipe:
Step 1. Batch upload the CIM, management accounts, legal agreements, and board deck to the Files API. Each document gets a persistent file ID. One API call per document, reusable across the full deal lifecycle.
Step 2. Set a system prompt defining the extraction schema for the specific deal type: PE acquisition, credit facility, or equity research. Each deal type has a different field set and risk flag hierarchy.
Step 3. Fable 5 processes all uploaded documents in one context window and returns a structured DD memo: key risks, upsell signals, financial red flags, covenant summary, and management credibility markers with source citations.
Step 4. An n8n webhook routes the structured memo to the deal team’s Notion workspace or deal room (DealCloud, Intralinks).
Step 5. The senior analyst reviews and annotates the memo. Every edit is logged as a prompt refinement for the next deal of the same type. Over ten deals, this log becomes a deal-type-specific calibration layer.
The Files API advantage compounds over deal volume. The same document set reused across financial model validation, legal review, and compliance screening requires no re-uploading and no repeated processing costs. Hebbia’s own implementation achieves 95% response time reduction through prompt caching (Anthropic / Hebbia, 2025). Teams running direct API access can replicate this using the Files API’s persistent storage with Claude’s prompt caching on the system prompt.
The governance gap most teams miss is the audit trail. Finance teams focused on output-generation workflows typically skip the step that regulatory defensibility requires. A DD memo generated by AI and reviewed by an analyst is a different audit artifact from a DD memo with a logged override history. The override log, which captures every instance where an analyst corrects or rejects a model output along with a reason code, is simultaneously the model calibration data and the regulatory evidence trail. Building it into the workflow from day one takes one additional step. Waiting until after a regulatory inquiry typically means doing the work under time pressure and legal oversight.
For Claude API access and Files API setup, that post covers the configuration steps for teams without an existing API integration.
What does governance look like for AI-generated financial analysis?
Eighty-five percent of finance professionals are at least somewhat confident in AI accuracy when answers are grounded in source documents (Hebbia, December 2025). That “when grounded” qualifier is the load-bearing condition for every financial analysis workflow. Source grounding is what makes AI outputs defensible to a partner, a client, or a regulator.
Four requirements shape how that works in practice. Source citations must be mandatory: every Fable 5 output in a financial analysis workflow should cite the specific document section and page number it drew from. A partner who receives a DD memo with no source citations cannot put it in front of a client or regulator with confidence. Source citation belongs in the system prompt.
Override logging gives the workflow memory. Every instance where an analyst corrects a model output should be logged with a reason code — factual error, interpretation difference, or missing context. Over ten deals, this log becomes your model calibration data and, over twenty, the audit trail a regulator would request if an AI-assisted recommendation were ever questioned.
The deal-value circuit breaker sets the human approval threshold. For transactions above $100M in PE or $50M in leveraged finance, no AI output should reach a client or counterparty without named senior analyst sign-off on the relevant sections. Automating this enforcement in the workflow tool costs one conditional step. Retrofitting it after a compliance question costs multiple days of legal and compliance review per deal.
Model version tracking closes the loop. When the underlying model or system prompt changes, log that change alongside the outputs it produced. If a regulatory inquiry ever asks which AI produced an analysis and under what instructions, the version log answers the question directly.
Whether the workflow runs through Hebbia Matrix or directly against the Claude API, these requirements follow the use case. The regulatory context the output enters remains constant.
For teams building the broader governance model across revenue and operations workflows, the strategic framework for AI workflow automation covers the organizational layer in detail. For cost management when deal volume scales and token consumption becomes material, Fable 5 token efficiency for production pipelines covers caching strategy and model selection at scale.
Frequently asked questions
Does Claude Fable 5 replace Bloomberg Terminal or Refinitiv?
Claude Fable 5 and Bloomberg Terminal serve different functions. Bloomberg delivers live market data feeds, price discovery, and proprietary terminal data. Fable 5 processes documents you already have: earnings transcripts, CIMs, 10-K filings, credit memos. The practical workflow pairs them: Bloomberg feeds the data, Fable 5 synthesizes the analysis across it.
How does Claude Fable 5 compare to Hebbia Matrix directly?
Hebbia Matrix is the platform; Claude Fable 5 is one model it can route tasks to. They are complementary: Hebbia routes tasks across extraction, summarization, and reasoning categories, and Fable 5 leads on the senior-level reasoning category. Teams without Hebbia can replicate the core reasoning capability through direct API access with structured prompts.
What file types does Claude Fable 5 process for financial analysis?
Via the Files API, Fable 5 handles PDF, DOCX, XLSX, HTML, and plain text. It does not process live Bloomberg data feeds or proprietary financial data formats directly. The practical workflow extracts structured data from Bloomberg or Refinitiv first, then uploads that structured output to Fable 5 for reasoning and synthesis across documents.
How do you handle hallucinations in financial analysis outputs?
The source grounding requirement is the primary control. Every Fable 5 output in a financial analysis workflow should cite the specific document section it drew from. Hebbia’s December 2025 survey found 85% of finance professionals are at least somewhat confident in AI accuracy specifically when outputs are grounded in source documents. Open-ended generation without source documents carries a different risk profile entirely.
Can Claude Fable 5 process 10-K filings and full earnings transcripts end to end?
Yes. Fable 5’s extended context window handles complete 10-K filings in a single pass, without chunking or summarization loss across sections. The Files API persists uploaded documents for 30 days, so the same filing supports multiple analysis runs (earnings comparison, covenant review, competitive positioning) without re-uploading or paying repeated processing costs.
Next steps
The Hebbia benchmark result is meaningful because it reflects real financial workflows (extraction, summarization, and senior reasoning across deal-relevant documents) rather than synthetic test questions. The practical implication is model routing based on task type. Fable 5 leads where senior document reasoning matters most; other models remain competitive for bulk extraction at lower cost.
The two workflows above are production-ready this week with existing API access. The governance layer (source citations, override logs, deal-value circuit breakers) takes one additional day to implement and makes every AI-assisted output defensible.
If you want us to build this for your team, let’s chat.