
Kimmo Hakonen - Chief Innovation Officer
Espressio AI
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 16, 2026
Claude Fable 5 on FrontierCode: Why Token Efficiency Decides Agent Economics

Gartner predicts more than 40% of enterprise AI agent projects will be canceled by end of 2027, with escalating costs and unclear ROI as the primary causes (Gartner, August 2025). Most of those cancellations won’t trace back to the model picking the wrong answer. They’ll trace back to the token bill.
Claude Fable 5 launched at $10 per million input tokens and $50 per million output tokens, exactly 2× what Opus 4.8 costs. Engineering leads see that price and start the wrong calculation: can we justify paying twice as much per token? The right calculation starts somewhere else: what does this model cost per completed task?
Once you apply FrontierCode Diamond’s pass-rate data, the 2× per-token premium inverts. Fable 5 comes out cheaper per solved task than both Opus 4.8 and GPT-5.5 on the problems that matter for production agents. The catch is that this advantage exists only inside an optimized loop. An unoptimized loop erases it entirely. This article explains why, and what three architectural changes restore the math.
Key Takeaways
- Fable 5 costs $6.83 per solved FrontierCode task vs. $7.46 for Opus 4.8 and $19.30 for GPT-5.5, despite 2× the per-token rate, because pass rate is the real denominator (TokenMix / Anthropic / Cognition, June 2026).
- Re-sent context = 62% of a typical agent bill; unoptimized loops cost 10–100× single-call interactions (LeanOps, May 2026).
- Prompt caching, model-tier routing, and context editing cut agent spend 55–75% in 30 days without switching models.
- Gartner: 40%+ of enterprise AI agent projects will be canceled by 2027, primarily due to cost overruns, with token economics as the deciding variable.
What does FrontierCode Diamond actually measure?
Claude Fable 5 scores 29.3% on FrontierCode Diamond, more than double Opus 4.8’s 13.4% and more than five times GPT-5.5’s 5.7% (Anthropic, June 2026). A gap that large changes the economics of running agents on hard problems. Understanding why requires knowing what Diamond tier is actually testing.
FrontierCode is Cognition’s hardest benchmark tier. Diamond-class problems arrive with incomplete specifications, ambiguous requirements, unfamiliar codebases, and no agreed definition of done. Think of the Monday-morning task that lands in a senior engineer’s queue, not a scenario designed to produce clean benchmark pass rates. The real task is deciding what the spec should have said, filling in the missing context, and building from there.
The gap between models narrows on cleaner work. On SWE-bench Pro (using Anthropic’s own scaffolding), Fable 5 scores 80.3% versus Opus 4.8 at 69.2%, a meaningful lead but nowhere near a 5× difference. The harder and more ambiguous the specification, the larger Fable 5’s advantage. For agents handling genuinely novel tasks (competitive analysis across unfamiliar markets, codebase exploration in new repositories, multi-source research synthesis, or proposal drafting from call transcripts), the Diamond score gap is the relevant cost predictor.
Why does pass rate predict cost? Pass@1 on Diamond tier measures how often the model produces a usable output on the first attempt. Every failed attempt consumes tokens and time. When GPT-5.5’s pass rate is 5.7%, a team running it at scale needs roughly 18 attempts per completed task. Fable 5 at 29.3% needs roughly 3.4. What does that math look like in dollars?
Anthropic’s June 2026 launch documentation includes an account of Fable 5 reaching near-equivalent results on a frontier physics research task in 36 hours, using roughly one-third the reasoning tokens GPT-5.5 consumed over four days on the same problem. Higher pass rate plus lower token consumption per successful run makes FrontierCode Diamond the closest publicly available proxy for real production agent economics on hard, open-ended work.
Why cost-per-token is the wrong unit
At standard pricing and Cognition’s FrontierCode pass rates, Fable 5 costs approximately $6.83 per solved task versus $7.46 for Opus 4.8 and $19.30 for GPT-5.5, despite Fable 5’s 2× per-token rate (TokenMix analysis of Anthropic pricing and Cognition benchmark data, June 2026). The premium model is cheaper than its competitors on the hard problems that matter for production agents.
Think about this the way you’d compare two engineers on a fixed project. Engineer A charges $200 per hour and solves the problem correctly on the first try 30% of the time. Engineer B charges $100 per hour but gets it right only 6% of the time on the first try. Even at double the hourly rate, Engineer A is more cost-efficient: fewer total hours billed per completed project. Token rate is the hourly rate. Pass rate decides the actual invoice.
The formula for cost per solved task: (cost per attempt) ÷ (pass rate). At 100K input tokens and 20K output tokens per attempt:
- Fable 5 ($10/M input, $50/M output): $1.00 + $1.00 = $2.00 per attempt ÷ 0.293 = $6.83 per solved task
- Opus 4.8 ($5/M input, $25/M output): $0.50 + $0.50 = $1.00 per attempt ÷ 0.134 = $7.46 per solved task
- GPT-5.5 (calculated from Anthropic pricing and Cognition pass-rate data, per TokenMix): $19.30 per solved task at 5.7% pass rate

This logic doesn’t hold across every task. On routine work with clear specifications (data formatting, templated content, structured lookups, and classification tasks), Opus 4.8 and Fable 5 both achieve high pass rates, and the 2× token cost difference tips Opus 4.8 into the lead. The cost-per-solve advantage is specific to hard, ambiguous work where pass rates diverge substantially. A team running nothing but templated tasks on Fable 5 is paying a premium it doesn’t need.
How agentic loops destroy the economics
Agentic AI workflows cost 10–100× more per task than single-call interactions at equivalent complexity; by step 10 in a typical agent loop, context accumulation alone produces a 10× cost multiplier that compounds with every additional turn (LeanOps, 2026). The cost-per-solve advantage Fable 5 earns on the benchmark disappears inside an unoptimized loop.
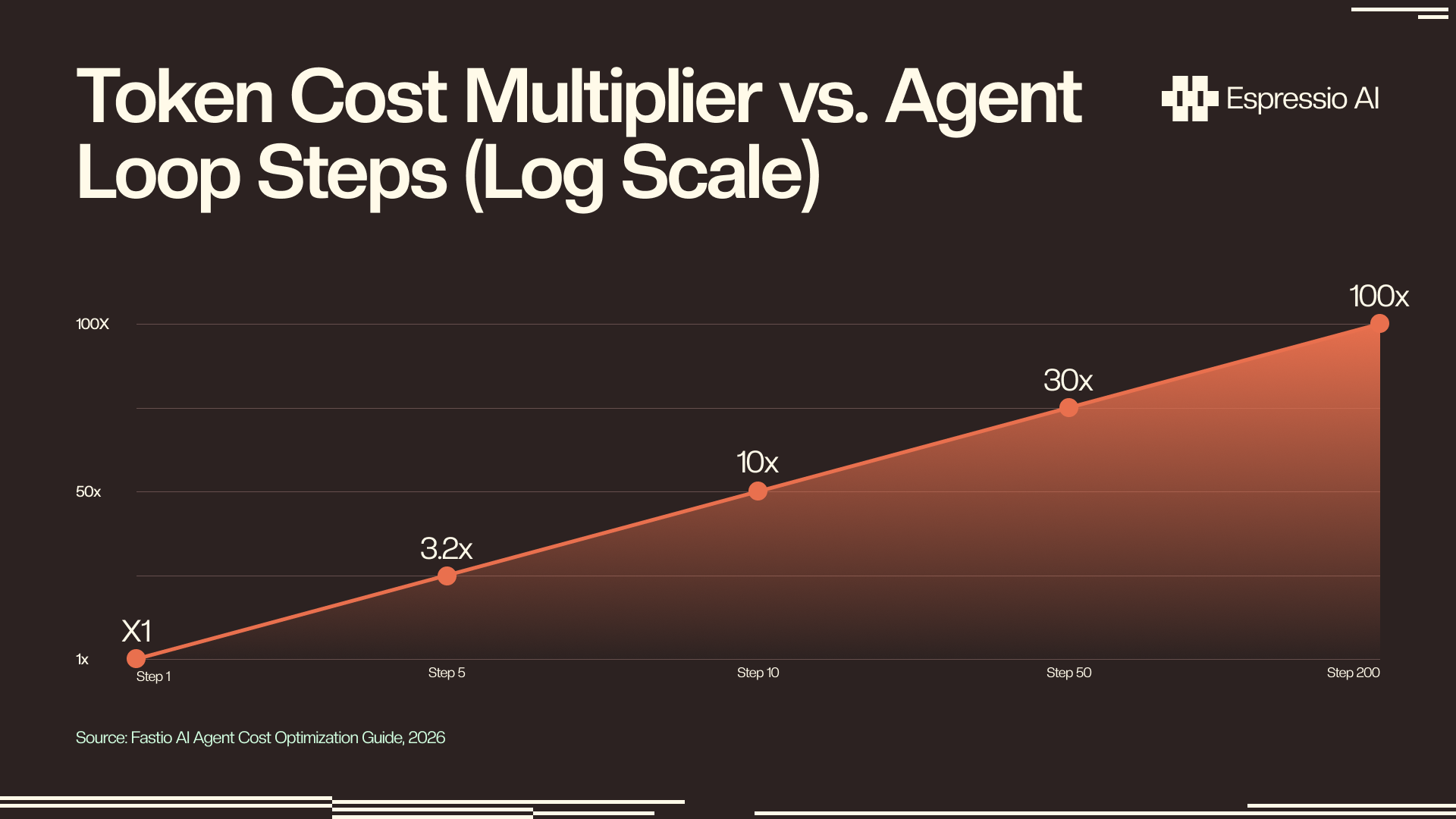
The mechanism is straightforward: each turn of an agent loop re-sends the full conversation history. By turn 50, the agent might be re-sending 40,000 tokens of completed work to get a 2,000-token response. LeanOps audited 30 engineering teams running production agents and found that re-sent context accounts for 62% of a typical agent bill, before a single new reasoning step executes (LeanOps, May 2026).
At Fable 5’s pricing, a competitive intelligence agent running 200-turn sessions with no context optimization carries a 100× cost multiplier. At team scale, that turns a workload that should cost $13,200 per month into one running at $110,000.
Espressio’s first deployment of our Competitive Intel agent ran into this precisely. The agent produced correct source data in phase one of each session, but we left all those outputs in context through phase three. By the time phase three’s retrieval logic ran, it was reading 80,000 tokens of completed work alongside its active task and re-fetching the same 12 competitor pages it had already processed. A session priced at roughly $40 was regularly hitting $200. Two API calls using context editing between phases solved it, but the problem was completely invisible in per-call pricing data.
That’s what an unoptimized loop does to a sub-$7-per-task model: context overhead turns it into a $68-per-task problem inside 20 turns. The benchmark economics are real. They survive only inside an architecture that doesn’t re-send everything the agent has already processed.
Three levers that restore the economics
Teams applying all three optimization levers (prompt caching, model-tier routing, and context editing) reduce agent spend by more than half within 30 days without switching models or degrading output quality, according to LeanOps’s audit of 30 engineering teams (LeanOps, May 2026). The savings compound because each lever addresses a different layer of the cost stack.
Prompt caching
Prompt caching charges 0.1× the standard input rate on cache reads, a 90% discount. Cache writes cost 1.25× for a 5-minute TTL (or 2× for 1-hour), but pay back after a single cache read on the 5-minute window (Tygart Media, 2026).
Structure your context in four layers: (1) stable system prompt, (2) project context and semantic memory, (3) episodic summary from the memory tool, (4) current-turn volatile content. Only the fourth layer changes each turn; the first three hit the cache. One mistake to avoid: mutating a cached value mid-loop breaks the cache prefix and eliminates the discount on every subsequent turn.
Model-tier routing
Routing 80% of tasks to Opus 4.8 and escalating only the hardest 20% to Fable 5 costs roughly 60% of what an all-Fable fleet costs, delivering comparable end-to-end results at 40% lower spend (TokenMix, June 2026). The routing decision follows a single signal: specification clarity. FrontierCode-class work (open-ended synthesis, novel problem solving, orchestration) goes to Fable 5. Everything else runs on Opus 4.8 or Haiku 4.5.
For async workloads (overnight research runs, scheduled batch processing), Anthropic’s Batch API cuts costs an additional 50%, bringing Fable 5 to $5/M input, matching Opus 4.8’s standard rate.
Context editing
Context editing (the context-management-2025-06-27 beta header) removes completed subtask outputs and stale tool results from the message history without touching data downstream phases need. It preserves source URLs, structured facts, and verified outputs while clearing the conversational overhead that drives re-sent context costs.
This is the single highest-impact lever in the LeanOps data: context editing accounts for more than half of the total cost reduction teams achieve. The key distinction from context compaction is precision: compaction summarizes the entire history (simpler, but lossy), while context editing removes only what you specify. When later phases depend on raw data from earlier phases, context editing is the right tool.
For the full API implementation of context editing and task budgets, the long-horizon agent architecture guide covers the beta headers, cache-prefix discipline, and phase-boundary patterns step by step.
When does Fable 5 win and when does Opus 4.8 win?
At identical tokens per attempt, the break-even is when Fable 5’s pass rate is at least 2× Opus 4.8’s: double the price per attempt, double the success rate, equal cost per solve. On FrontierCode Diamond, the 29.3% vs. 13.4% ratio gives a 2.2× advantage, clearing that threshold comfortably. Below it, Opus 4.8’s lower token rate wins. Fable 5’s 1M-token context window also carries no long-context surcharge; GPT-5.5 doubles input pricing past 272K tokens, a separate cost advantage for agents holding large codebases or research corpora in working memory.
| Task type | Recommended model | Rationale |
|---|---|---|
| Open-ended problem solving, novel codebases | Fable 5 | Pass-rate differential exceeds break-even threshold |
| Agent orchestration and synthesis steps | Fable 5 with effort: "high" | Novel synthesis quality justifies the premium |
| Routine data extraction, templated output | Opus 4.8 | High pass rate on clean specs; 2× cheaper per token |
| Async batch workloads (overnight, scheduled) | Fable 5 Batch API | 50% off brings it to Opus 4.8 standard pricing |
| Deterministic lookups, structured formatting | Haiku 4.5 | Fastest and cheapest for unambiguous tasks |
For implementation patterns with a multi-model fleet using fan-out architecture, see how to build autonomous coding agents on Fable 5. For a multi-agent routing example using a CrewAI-style orchestration layer, see the multi-model CrewAI agent patterns.
What this means for marketing and RevOps teams
Fifty-seven percent of organizations now deploy multi-step agent workflows and 80% report measurable economic impact (Anthropic State of AI Agents via Arcade, 2026). The token economics described above apply to those teams with equal force; the API, cost multipliers, and optimization levers are unchanged.
RevOps and marketing workflows map directly to the decision matrix. Competitive research, proposal synthesis from call transcripts, multi-source brief generation, and competitive landscape monitoring are FrontierCode-class tasks: ambiguous inputs, high reasoning load, no single right answer, and output quality that depends heavily on problem framing. These belong on Fable 5. Templated email sequences, scheduled social content, data formatting from structured sources, and CRM field updates are Opus 4.8 territory. Most growth teams run both workload types through the same pipeline without segmenting model selection, which is where unnecessary costs accumulate.
That Gartner projection deserves a closer read. The cancellations will trace back to token economics: teams prototyping on an unoptimized baseline, seeing $80K in monthly API costs, and concluding agents aren’t economically viable. Those same programs would run at $13K per month with proper context management in place. The three levers in this article are the baseline configuration required to evaluate whether an agent program makes business sense at all.
Do you need a Python environment to access these economics? Espressio’s implementations run the Anthropic API behind Make.com or n8n for session triggers and data routing, with Airtable or Notion as the memory store. The context editing and prompt caching patterns this article describes are exactly what’s happening under the hood of every no-code wrapper running on those platforms.
If you want to map these optimization levers to your specific stack, let’s chat. The Espressio team scopes model routing and context engineering for your workload in 45 minutes.
For the broader AI workflow automation playbook for revenue teams, including CRM, project management, and data platform integrations, see AI workflow automation for revenue teams. For a LangChain-based routing example applied to lead qualification, see the LangChain lead qualification agent guide.
Frequently asked questions
Is Claude Fable 5 worth the 2× per-token price?
On FrontierCode-difficulty work, the economics favor Fable 5. The higher token rate is outweighed by the pass-rate differential: Fable 5’s 29.3% vs. Opus 4.8’s 13.4% success rate means fewer total attempts per completed task, bringing the real invoice below Opus 4.8’s despite the 2× per-token premium (TokenMix analysis of Anthropic pricing and Cognition benchmark data, June 2026). On routine tasks with clear specifications, Opus 4.8 produces comparable results at half the token cost.
How much does prompt caching actually save on a long agent session?
Cached tokens cost 0.1× the standard input rate, a 90% discount on re-sent context. Cache writes cost 1.25× for a 5-minute TTL but pay back after a single read. A well-structured agent with a 30K-token stable system prompt and context layer saves 60–80% of per-turn input costs across a 50-turn session (Tygart Media, 2026), before model routing or context editing are applied.
When should I route to Opus 4.8 instead of Fable 5?
Route to Opus 4.8 when the task has a clear, unambiguous specification: templated drafts, structured data extraction, deterministic lookups, or content generation from a well-defined brief. Routing 80% of tasks to Opus 4.8 and escalating the hard 20% to Fable 5 costs roughly 60% of an all-Fable fleet, with comparable end-to-end output quality at 40% lower spend (TokenMix, June 2026).
What is FrontierCode Diamond and why does it predict real-world agent costs?
FrontierCode Diamond is Cognition’s hardest benchmark tier: incomplete specs, ambiguous requirements, novel codebases, and no clear success metric before you start. Pass@1 on Diamond measures how many attempts a model needs per completed task. That figure, multiplied by cost per attempt, gives cost per solve: the number that actually governs your agent infrastructure bill on hard, open-ended work.
Next steps
Token price is a headline figure. Cost per solved task is the operating reality. Fable 5’s 29.3% FrontierCode Diamond score makes it the most cost-effective choice for hard agent work — but that arithmetic is fragile. An unoptimized loop multiplies that per-task figure tenfold inside 20 turns.
Apply the three levers before running any cost evaluation: prompt caching on stable context, model-tier routing for task segmentation, and context editing between phases. Teams that complete all three steps land 55–75% below their initial API bill without touching output quality or switching models.
- For context editing and task budget API implementation, see the long-horizon agent architecture guide.
- For multi-model fleet patterns and fan-out architecture, see how to build autonomous coding agents on Fable 5.
- For the broader revenue team automation context, see AI workflow automation for revenue teams.
If you want us to build this for your team, let’s chat.

