
Luka Mrkić
Head of BD
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 12, 2026
Inside Stripe's 50M-Line Ruby Migration with Claude Fable 5

TL;DR
- In the Claude Fable 5 launch on June 9, 2026, Anthropic published a customer signal from Stripe: Fable 5 performed a codebase-wide migration on a 50-million-line Ruby codebase in a day where the manual path would have taken a whole team over two months.
- Stripe’s result is the headline. The structural lesson is that Fable 5 is the first generally available Claude model where long-horizon code migrations behave more like a planning and review problem than a typing problem.
- The capabilities that make this tractable are the 1M token context window, adaptive thinking that stays focused across long tasks, persistent file-based memory, and frontier scores on coding benchmarks like Cognition’s FrontierCode.
- About 5% of Fable 5 sessions fall back to Opus 4.8 because of safety classifiers. For an internal migration the categories are unlikely to fire, but your client needs to handle stop_reason: refusal anyway.
- You do not need to be Stripe-sized to benefit. The same workflow applies to Rails monoliths, big TypeScript codebases, legacy Java services, and any framework upgrade where a clear before-and-after seam can be defined.
If you are evaluating who should plan and run a Fable 5 migration on your own codebase, this guide gives you both the technical blueprint and the standards to evaluate the work.
What Stripe actually reported
Anthropic’s Fable 5 launch post on June 9, 2026 includes a specific Stripe data point inside the software engineering section. Stripe reported during early testing that Fable 5 compressed months of engineering into days. In one example, the model performed a codebase-wide migration on a 50-million-line Ruby codebase in a day where the manual path would have taken a whole team over two months by hand.
Anthropic did not publish the specific migration (Ruby version upgrade, framework version, internal API refactor, lint or type rule rollout, deprecated API removal). What the post does establish is the scale of the codebase, the elapsed time on the model-driven path, and the implied team size and elapsed time on the hand path. That is enough to draw three useful conclusions for an engineering org weighing its own migration.
Why this migration needs its own playbook
Long-horizon code migrations failed before Fable 5 for one structural reason. Earlier Claude models, GPT-5 family models, and Gemini family models could plan a migration on a small example, but the context window and the model’s ability to stay focused across millions of tokens of cross-file state collapsed as the codebase grew. The agent would patch a file, lose track of an invariant somewhere else in the tree, and the team would spend most of the cycle debugging the patch trail.
Fable 5 changes the math on three dimensions: a 1M token context window, adaptive thinking that is always on, and persistent file-based memory that Anthropic reports improves long-task performance roughly three times more on Fable 5 than on Opus 4.8 in their internal tests. Stripe’s reported result is the first public benchmark that pushes those capabilities against a real production codebase at frontier scale.
If you are interested in building AI agents and automation like this for your team, book a call here.
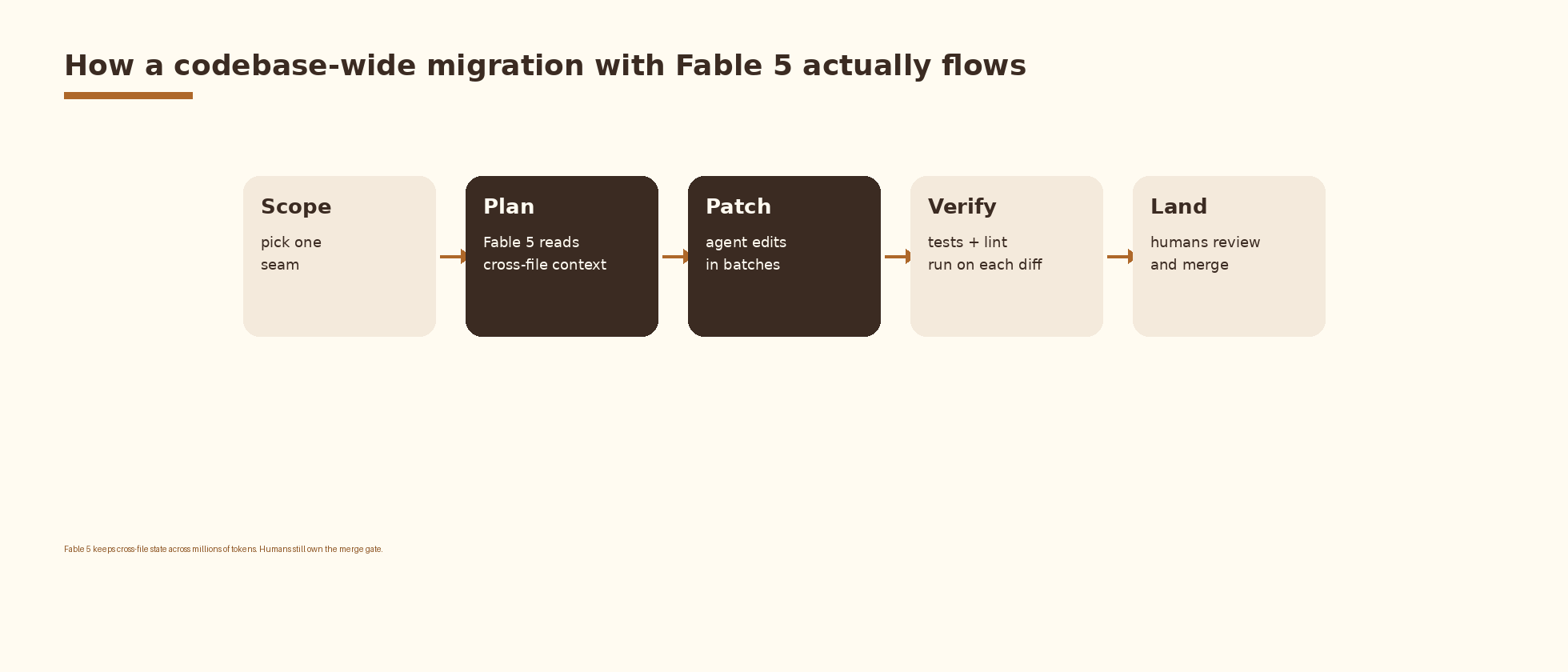
How a Fable 5 driven migration actually flows
The right mental model for a Fable 5 driven migration is a planning loop wrapped around a patch loop wrapped around a verification loop. The model handles the planning and the patching. Your build system, your tests, and your code review process handle the verification and the merge. The four phases below are the same phases your team would use to run a hand migration; what changes is which phases are on the model’s hot path and which stay with humans.
1. Scope selection
Pick a single migration seam with a clear before-and-after. Examples that fit cleanly: a Ruby version upgrade, a Rails major version, a deprecated internal API removal, a lint or type rule rollout across the tree, a logging library swap. Open-ended refactors (“clean up the billing module”) lose the verification loop because there is no objective check on whether a given patch moved you closer to done. A defined seam is what lets the agent and your CI agree on what completion looks like.
2. Planning
Hand Fable 5 the seam definition, the project layout, and the cross-file invariants the migration must preserve (database constraints, public API shapes, performance budgets, security properties). The 1M token context window means the model can hold the conventions, the style guide, the build config, and the relevant subset of the tree in one prompt. The memory tool lets the model carry that state across long sessions without paying for the full re-read on every batch.
3. Patching
The agent emits patches in batches. The right batch size is the largest unit your CI can verify in one run cleanly: usually one to a few dozen files at a time, grouped by intent. Stripe’s reported one-day timeline implies a tight loop where the model could emit, get test signal back, and emit the next batch without sitting on a slow CI queue.
4. Verification and merge
Every batch runs through the same test, lint, type check, and smoke build process the team uses for human PRs. The model reads the failures and produces the next patch. Humans own the merge gate. Reviewers see a structured patch trail with one batch per intent, which is faster to review than the same change emitted as one giant diff. Stripe’s result is interesting because the bottleneck moves from coding to review, and the org that wins is the org that prepared its review surface for that load.
What about Stripe’s result is reproducible
Three signals from the Anthropic launch post and Stripe’s customer quote are reproducible for a typical engineering org. The remaining details are Stripe-specific.
Reproducible
First, the order-of-magnitude compression on a defined migration seam. Fable 5’s combination of 1M context, always-on thinking, and persistent memory does compress migration timelines by a large factor on real codebases. Second, the structural shift from coding bottleneck to review bottleneck. Whether your seam is a 50,000-line Rails app or a 5,000,000-line Java service, the bottleneck moves to whoever is approving the patches. Third, the importance of the verification loop. Stripe’s CI is exceptional, and the speed of the loop matters more than any single capability of the model.
Stripe-specific
The 50-million-line scale is a Stripe number. Most engineering orgs are working with codebases two to four orders of magnitude smaller. The one-day timeline is Stripe-specific because Stripe’s build, test, and code review infrastructure is unusually fast for its size. Whether your team can replicate the exact ratio depends as much on your CI as on the model. The takeaway is the structural lesson.

How to run a Fable 5 migration on your own codebase
If you want to take a serious shot at a Fable 5 driven migration on your own codebase this quarter, the workflow below is the one we ship for Espressio clients. It assumes you have an API key on console.anthropic.com or access to claude-fable-5 through Bedrock, Vertex AI, or Foundry, and that you have a CI pipeline that can run tests on demand against branch builds.
Step 1: Pick the seam
Write a one-paragraph seam definition: the before state, the after state, the file globs in scope, the invariants that must hold, and the success criteria your CI can check. If you cannot write that paragraph in fifteen minutes, the seam is not defined cleanly enough yet.
Step 2: Build the migration agent
Use the Claude API with the model ID claude-fable-5. The Anthropic Python SDK is the simplest path. Set the thinking effort to medium for routine batches and high for batches that touch invariants. Pass the fallbacks parameter as [“claude-opus-4-8”] so refusals route to Opus 4.8 without an extra round trip. Use the memory tool to keep the seam definition, the style guide, and the cross-file invariants in scope across batches.
Step 3: Wire the verification loop
Point the agent at a sandbox branch in your repo. After each batch of patches, run the test suite, the lint pass, the type check, and a smoke build against the branch. Feed the failure output back into the next prompt. The total cycle time per batch is what bounds your migration timeline. Aim for batches under fifteen minutes end to end so the agent stays in the loop.
Step 4: Stage the review
Group patches by intent. Open one pull request per intent so reviewers can read each batch as a unit. Reviewers should see a written plan from the model, the diffs grouped by file, and the CI status. The merge gate stays with humans. Your code review velocity is now the binding constraint on the migration.
If you want this set up cleanly inside your stack with logging, retries, and a feedback loop into a CRM, that is the kind of work we ship at Espressio.
Common mistakes when running a Fable 5 migration
- Picking an open-ended refactor as the seam. Without a clear before-and-after the verification loop has nothing to check and the agent drifts. Pick a seam with a CI-checkable success criterion.
- Loading every file every batch. Use the memory tool and context editing so the agent does not re-read the full tree on every call. Costs and latency climb fast otherwise.
- Skipping the verification loop. Patches without tests are how invariants drift quietly in a long migration. Run the test and lint pass on every batch.
- Treating stop_reason: refusal as an error. The Messages API returns HTTP 200 on a refusal. Internal migrations rarely trigger the cyber, bio, or distillation classifiers, but your client needs to handle the case anyway.
- Reviewing the migration as one giant PR. The model emits a structured patch trail; preserve that structure by opening one PR per intent so reviewers can read each change in context.
- Comparing your timeline to Stripe’s one-day number. Stripe runs an unusually fast CI for its size. Score the migration against your own hand baseline.
- Skipping the rollback plan. Even with a strong verification loop, a migration of any size needs a documented rollback path. Plan it before the first patch lands on main.
How to know your Fable 5 migration is working
Four metrics belong on a dashboard the day the migration starts. Test pass rate per batch tells you whether the agent is converging or thrashing. Refusal rate tells you whether the classifiers are firing on something benign in your codebase. Per-batch token cost tells you whether the migration is paying for itself against your hand baseline. Review throughput tells you whether the bottleneck has shifted to the merge gate yet.
Pair these with a daily review of one or two failed batches. Read the patch trail the model produced, the failure output it received, and the next patch it emitted. That is the fastest way to tell whether the seam definition needs to be tightened or whether the agent is genuinely making progress.

What this means for your engineering org
Stripe’s reported result lands a few weeks into the broader Mythos-class moment. The structural takeaway for your engineering org is that long-horizon code migrations are now in the set of workflows where a single frontier model plus a careful verification loop produces real production value. That was not reliably true on Opus 4.8. It is reliably true on Fable 5 inside the seams the verification loop can check.
Three implications for the next quarter. First, the backlog of deferred migrations on most engineering orgs is now actionable in a way it was not in early 2026. Second, the engineering bottleneck is shifting from coding to review, which changes what “senior engineering capacity” should be spending time on. Third, the value of a strong CI pipeline goes up sharply because the model’s cycle time is bounded by your verification loop.
FAQ
Did Stripe really migrate 50 million lines of Ruby in a day with Claude Fable 5?
Anthropic published that data point in the Fable 5 launch post on June 9, 2026. Stripe reported during early testing that Fable 5 compressed months of engineering into days, and that in one example the model performed a codebase-wide migration on a 50-million-line Ruby codebase in a day where the manual path would have taken a whole team over two months. Anthropic did not publish which specific migration this was.
What migration did Stripe actually run?
Anthropic’s launch post does not specify the migration. The framing in the post (“codebase-wide migration”) and the Stripe team’s prior public talks suggest the kind of work this fits is a major version upgrade, a deprecated API removal, a Ruby or framework version bump, or a sweeping internal refactor. The post is clear about the scale (50 million lines), the elapsed time (a day), and the hand baseline (over two months) but not the seam itself.
Can my team replicate Stripe’s result on a smaller codebase?
The order-of-magnitude compression is reproducible on a defined seam. The exact ratio depends on the speed of your CI, the size of your verification loop, the clarity of the seam definition, and how prepared your code review process is for batched patches. The structural lesson (timeline decouples from codebase size, bottleneck moves from coding to review) holds across codebase sizes.
What model ID and pricing apply for this kind of work?
Use claude-fable-5. Pricing is $10 per million input tokens and $50 per million output tokens. On a large migration most of the cost is output tokens. Cap effort per workflow and use prompt caching and the Batch API where they apply to keep the bill aligned to the value of the migration.
What about Claude Opus 4.8 for a migration this size?
Opus 4.8 is the right default for many everyday coding tasks. For long-horizon migrations on a large codebase, Fable 5 is the model whose context window, always-on thinking, and memory behavior were designed for the workload. Use Opus 4.8 as the fallback model when classifiers fire on Fable 5, and as the production model for shorter coding tasks where Fable’s profile is overkill.
Do I need the 1M context window for this?
Yes in practice. The point of the 1M context window for a migration is to keep the seam definition, the style guide, the relevant subset of the tree, and the cross-file invariants in scope for the model at the same time. Smaller context windows force you to swap context in and out per batch, which is the structural reason earlier models lost track of invariants on large codebases.
Do safety refusals matter for an internal code migration?
Internal codebase migrations almost never trigger the cyber, biology, chemistry, or distillation classifiers that Fable 5 falls back to Opus 4.8 on. Your client still needs to handle stop_reason: refusal as a typed event because the response returns on HTTP 200. The simplest path is to pass the fallbacks parameter as [“claude-opus-4-8”] so refusals route to the fallback model in one round trip.
What to do next
- Pick one migration seam on your codebase with a clear before-and-after and a CI-checkable success criterion. Write the seam definition in one paragraph.
- Stand up a sandbox branch and wire your test, lint, type check, and smoke build into the agent’s verification loop.
- Build the migration agent on the Claude API with claude-fable-5, the memory tool, and the fallbacks parameter set to claude-opus-4-8.
- Run the agent against the seam for a day. Score the result against your team’s hand-baseline estimate for the same migration.
- Prepare the review surface. One PR per intent, a written plan per batch, and a documented rollback path before anything lands on main.
If you want a Fable 5 migration designed and shipped cleanly inside your engineering org with seam selection, agent setup, verification loop, and reviewer load all built in, let’s talk.
Related Espressio guides
- Claude Fable 5: The Complete Guide to Anthropic’s New Mythos-Class Model
- Claude Fable 5 API: Access, First Calls, and What’s Different from Opus
- Claude Fable 5 Pricing Explained: $10 / $50 per Million Tokens in Practice
- Claude Fable 5 vs GPT-5 vs Gemini 3: Frontier Benchmarks Compared
- Claude Mythos 5 Explained: Project Glasswing and the Trusted Access Tier
- How to Integrate Claude with Amazon Web Services to Automate Content Pipelines

