
Luka Mrkić
Head of BD
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 12, 2026
Claude Fable 5 API: Access, First Calls, and What's Different from Opus

TL;DR
- Claude Fable 5 is live on the Claude API as of June 9, 2026, with model ID claude-fable-5, a 1M token context window, and 128k output tokens per request.
- Pricing is $10 per million input tokens and $50 per million output tokens. Fable 5 is also available on AWS Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
- The migration from Opus 4.8 is one line of code at the model ID. The behavior changes around adaptive thinking, refusals, fallbacks, and data retention are the parts that need new client code.
- Adaptive thinking is always on. Raw chain of thought is never returned. Use thinking.display to pick how summarized traces appear in your response.
- About 5% of sessions today return stop_reason: refusal because Fable’s safety classifiers route to Opus 4.8. Treat this as a typed event in your client.
If you are evaluating who should build production agents on Fable 5 for your team, this guide gives you both the technical blueprint and the standards to evaluate the work.
How to get access to the Claude Fable 5 API
Fable 5 is generally available on the Claude API on consumption-based plans from launch. You need an Anthropic account, a workspace with billing in good standing, and an API key generated from console.anthropic.com. No waitlist is required on the API path. If your team relies on subscription plans, Fable 5 is included on Pro, Max, Team, and seat-based Enterprise only through June 22, 2026, after which it moves to a credit-based model until Anthropic restores it as a standard subscription feature. For production workloads, plan the API path and do not rely on the subscription rollout window for anything serious.
Three other surfaces ship Fable 5 from launch and matter for capacity planning. Amazon Bedrock exposes claude-fable-5 through the InvokeModel and Converse APIs with your existing AWS IAM credentials. Google Cloud Vertex AI exposes it through publisher endpoints in supported regions. Microsoft Foundry exposes it through the Anthropic provider with Azure-managed keys. Most production teams should provision at least one cloud-side path in addition to the direct API so a regional capacity issue on one surface does not stall the product.
Why the Fable 5 API needs its own playbook
The model ID swap from Opus 4.8 to Fable 5 is one line of code. The behavior around the model is what changes. Adaptive thinking is always on. Fable 5 ships with new safety classifiers in front of the model that route about 5% of sessions to Opus 4.8 as a fallback. Raw chain of thought is never returned. Zero data retention is not available. Each of these is a small change to the request shape, the response shape, or the operational policy around the workflow. Together they decide whether your first production rollout feels smooth or feels noisy.
If you are interested in building AI agents and automation like this for your team, book a call here.
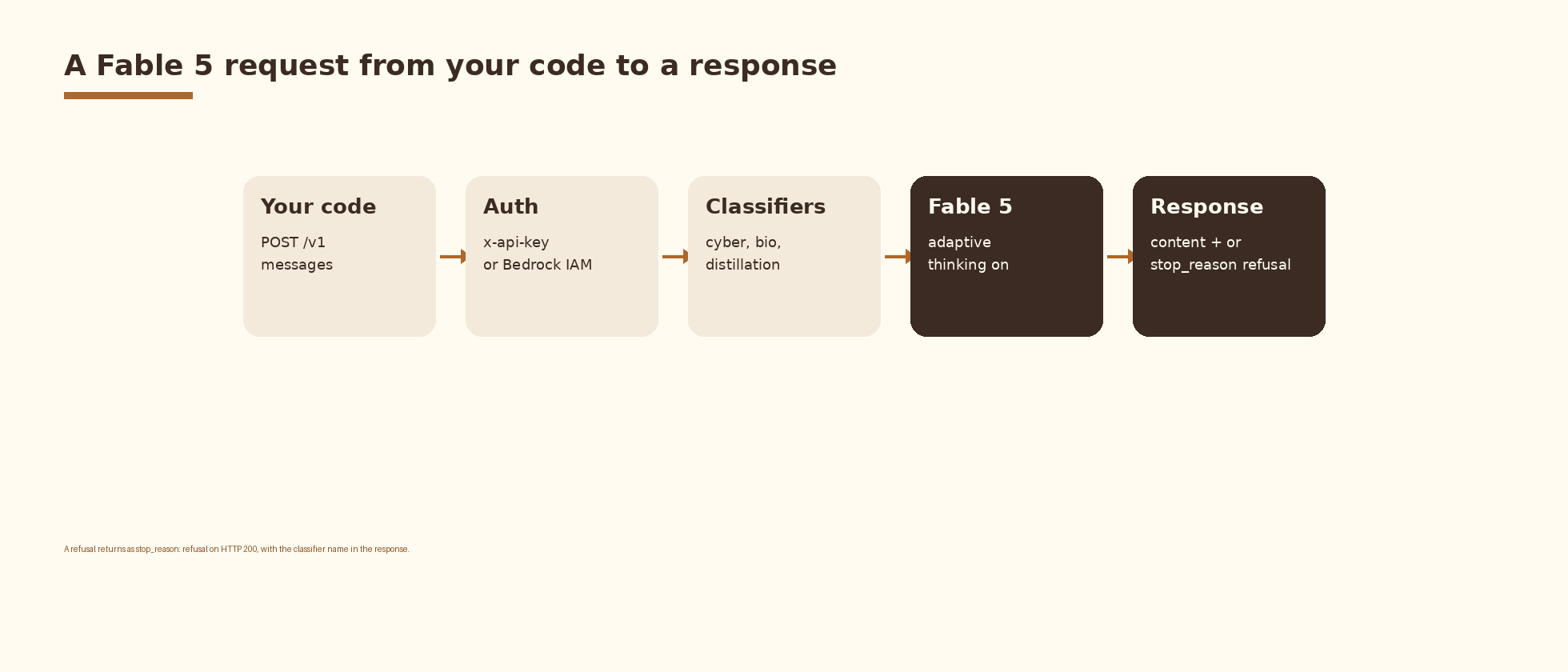
Your first API call to claude-fable-5
The Messages API surface is unchanged. The model ID is the only required swap. Here is the minimal cURL call against the Claude API.
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2026-06-09" \
-H "content-type: application/json" \
-d '{
"model": "claude-fable-5",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "Summarize this quarter\u2019s earnings release."}
]
}'The Python SDK pattern is the same as Opus 4.8. Pin the latest Anthropic SDK so the new parameters are available.
from anthropic import Anthropic
client = Anthropic()
response = client.messages.create(
model="claude-fable-5",
max_tokens=2048,
thinking={"display": "summarized", "effort": "medium"},
fallbacks=["claude-opus-4-8"],
messages=[{"role": "user", "content": "Draft a migration plan for our 2M-line Rails monolith."}],
)
if response.stop_reason == "refusal":
# Classifier fired. The fallbacks parameter already retried on Opus 4.8.
log_refusal(response)
else:
print(response.content[0].text)Three things in that call are new in Fable 5. The thinking parameter controls how the model spends thinking tokens; effort accepts low, medium, and high and is the lever for cost and latency. The thinking.display value picks between summarized and structured summaries; raw chain of thought is never returned. The fallbacks parameter is the supported way to register a model that should pick up requests when the classifiers fire on Fable 5.
How Fable 5 differs from Claude Opus 4.8 in the API
The seven differences below are the ones that change client code or operational policy. The benchmarks and capability claims are documented in the launch post and in our companion guide to the Fable 5 model itself.
Model ID and pricing
The Opus 4.8 model ID is claude-opus-4-8. The Fable 5 model ID is claude-fable-5. Pricing on Fable 5 is $10 per million input tokens and $50 per million output tokens, which is twice the per-token cost of Opus 4.8 standard mode and equal to Opus 4.8 fast mode. The right comparison for latency-sensitive workloads is Fable 5 against Opus 4.8 fast mode, where the per-token price is identical and the deciding signals become latency and quality on your eval set.
Context window
Opus 4.8 supports a 200,000 token context window. Fable 5 supports a 1,000,000 token context window with up to 128,000 output tokens per request. The memory tool and context editing are supported, which matters for agents that operate across millions of tokens of session history.
Adaptive thinking is always on
On Opus 4.8 the thinking parameter is optional and off by default. On Fable 5 thinking is always on. You cannot disable it. You can shape it. effort accepts low, medium, and high and trades latency and cost for quality. thinking.display controls how the summarized trace appears in the response. Raw chain of thought is never returned on Fable 5 or Mythos 5. Pass thinking blocks back unchanged in multi-turn conversations on the same model so the model can reuse its prior reasoning.
Safety classifiers and the refusal stop reason
Fable 5 ships with first-class safety classifiers in front of the model that detect potential misuse on cybersecurity, biology and chemistry, and distillation queries. When the classifiers fire, the response returns stop_reason: refusal as a successful HTTP 200, with the classifier name in the response. Around 5% of sessions trigger this today. Handle it explicitly in your client. The supported pattern is the fallbacks parameter on the request, which Anthropic uses to retry the request on a model you nominate (typically claude-opus-4-8) without an extra round trip from your code.
Data retention
Fable 5 and Mythos 5 are designated Covered Models. They carry mandatory 30-day data retention on first-party and third-party surfaces. Zero data retention is not available. Workflows with strict ZDR requirements (regulated industries, customer data with explicit no-retention clauses) need to stay on Opus 4.8 or earlier classes until the policy changes.
Capacity and the rollout window
Anthropic flagged capacity as the constraint most likely to bite teams in the launch window. From June 9 through June 22, 2026 Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans at no extra cost. On June 23 it moves to a credit-based model until Anthropic can return it as a standard subscription feature. The API and consumption-based Enterprise plans have Fable 5 fully available from launch. The implication for production teams: provision the API path now and avoid building anything production-critical on the subscription path through the credit cutover.
Available surfaces
Opus 4.8 is broadly available across the Claude API, Bedrock, Vertex AI, and Foundry. Fable 5 launched generally available on the same four surfaces on June 9, 2026. Mythos 5 is in limited availability for Project Glasswing partners only, with a planned trusted access program for biology research.

A production-ready Fable 5 client
A first call is a few lines. A production client adds typed refusal handling, retry on rate limits, and observability that lets you read the workflow the way the team actually operates it. The Python sketch below covers the patterns we ship for Espressio clients.
from anthropic import Anthropic
from anthropic._exceptions import RateLimitError
import time, logging
client = Anthropic()
log = logging.getLogger("fable")
def call_fable(messages, *, effort="medium", max_tokens=2048, attempt=0):
try:
resp = client.messages.create(
model="claude-fable-5",
max_tokens=max_tokens,
thinking={"display": "summarized", "effort": effort},
fallbacks=["claude-opus-4-8"],
messages=messages,
)
except RateLimitError:
if attempt >= 4:
raise
time.sleep(2 ** attempt)
return call_fable(messages, effort=effort, max_tokens=max_tokens, attempt=attempt + 1)
if resp.stop_reason == "refusal":
log.info("fable.refusal", extra={"classifier": resp.refusal})
# The fallbacks parameter already returned an Opus 4.8 response.
return resp
log.info("fable.ok", extra={"tokens_in": resp.usage.input_tokens, "tokens_out": resp.usage.output_tokens})
return respThe wrapper is small on purpose. It logs refusals as a separate event from successes, exposes effort and max_tokens as the parameters most often tuned per workflow, and treats rate limit responses as a normal backoff. Build on top of this with workflow-specific routing and an eval harness that hits the same client.
If you want this set up cleanly inside your stack with logging, retries, and a feedback loop into a CRM, that is the kind of work we ship at Espressio.
Common mistakes when calling the Fable 5 API
- Swapping the model ID without updating SDKs. Older Anthropic SDKs predate the fallbacks parameter and the thinking.display options. Pin the latest SDK and the matching anthropic-version header before flipping production traffic.
- Treating stop_reason: refusal as an error. It returns on HTTP 200 with a successful response body. Clients that catch only HTTP errors will treat refusals as successful empty responses to the end user.
- Routing every request to Fable 5. The cost profile pays off on long-horizon and high-stakes work. Route by workflow and keep Sonnet and Opus 4.8 in the stack for the workloads where they already nail the job.
- Setting effort to high on every call. Adaptive thinking is the cost lever. Cap effort per workflow and let the model spend more tokens only when the task benefits from it.
- Assuming zero data retention. Fable 5 is a Covered Model with mandatory 30-day retention. ZDR-required workflows stay on Opus 4.8 or earlier.
- Skipping the migration guides. Anthropic published step-by-step upgrade paths from Opus 4.8 and Mythos Preview. Prompts that worked on Opus may behave differently because of adaptive thinking and the new classifiers.
- Building production on the subscription window. Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans only through June 22. Production traffic belongs on the API or consumption-based Enterprise plans.
How to know your Fable 5 rollout is working
Four metrics belong on a dashboard the day Fable 5 hits production. Refusal rate by workflow tells you whether the classifiers are catching tasks your users actually want done. Fallback latency tells you whether your fallback path keeps users in the conversation or drops them out. Per-workflow token cost tells you whether Fable is paying for itself on the workloads where you routed it. Output quality, measured by your own eval set, tells you whether the model is delivering on the long-horizon promise.
Pair these with a weekly review of fallback samples. Read 20 to 50 actual fallback cases per week and check whether the classifiers are firing on the categories Anthropic described or on something benign that your prompt is triggering. If the rate climbs above 10% on a workflow, the prompt is the first place to fix.

Fable 5 versus the rest of the Claude API family
The Claude lineup now spans five tiers: Haiku, Sonnet, Opus, Fable, and Mythos. Haiku and Sonnet remain the default choices for high-volume and latency-sensitive workloads. Opus 4.8 is the workhorse for complex tasks that do not need Fable’s long-horizon capability, and it is also the model your fallback path retries on. Fable 5 sits at the generally available top of the stack. Mythos 5 is the same underlying model as Fable 5 with cyber, bio, and chem safeguards lifted, available only through Project Glasswing.
The practical implication for a production API stack is that you now have a meaningful four-way routing decision: Sonnet for high volume, Opus 4.8 for everyday complex work, Fable 5 for long-horizon and high-stakes work, and a fallback policy that respects the classifiers.
FAQ
What is the API model ID for Claude Fable 5?
claude-fable-5. The model is generally available on the Claude API, Claude Platform on AWS, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
Is there a waitlist for the Fable 5 API?
No. Fable 5 is generally available on the Claude API and on consumption-based Enterprise plans from June 9, 2026. The subscription rollout is staged through June 22 because of capacity, but the API path has Fable 5 available to any account in good standing from launch.
How much does the Fable 5 API cost?
$10 per million input tokens and $50 per million output tokens. That is twice the standard-tier Opus 4.8 price and equal to Opus 4.8 fast-mode pricing. Less than half the price of Claude Mythos Preview, which Fable 5 replaces.
What is the context window for Fable 5?
1,000,000 tokens by default, with up to 128,000 output tokens per request. The memory tool and context editing are supported for long-running agent sessions.
How do I handle a refusal from Fable 5?
When the classifiers fire, the Messages API returns stop_reason: refusal on HTTP 200 with the classifier name in the response. The supported pattern is to pass the fallbacks parameter on your request (typically [“claude-opus-4-8”]) so Anthropic retries on the fallback model in a single round trip. Log the refusal event separately from a normal success so you can review fallback samples weekly.
Can I see Fable 5’s chain of thought?
Raw chain of thought is never returned on Fable 5 or Mythos 5. Set thinking.display to summarized to receive readable summarized thinking blocks in the response. Pass thinking blocks back unchanged on multi-turn conversations on the same model.
Is Fable 5 available with zero data retention?
No. Fable 5 and Mythos 5 are designated Covered Models with mandatory 30-day data retention on first-party and third-party surfaces. Workflows that require ZDR need to stay on Opus 4.8 or earlier classes.
Can I call Fable 5 on AWS Bedrock or Google Cloud Vertex AI?
Yes. Fable 5 launched generally available on Amazon Bedrock through InvokeModel and Converse, on Google Cloud Vertex AI through publisher endpoints, and on Microsoft Foundry through the Anthropic provider, all on June 9, 2026.
Should I move all my Claude API traffic from Opus 4.8 to Fable 5?
No. Fable 5 is the right model for long, complex, and high-stakes work where senior-grade output outweighs the per-token cost. Keep Sonnet and Opus 4.8 in the stack for high-volume, latency-sensitive, and short well-scoped tasks where they already produce strong results.
What to do next
- Pin the latest Anthropic SDK and set the anthropic-version header to the current release across every service that calls the model.
- Add stop_reason: refusal handling to your client today, even if your first workflow does not touch the classifier categories.
- Provision at least one cloud-side surface (Bedrock or Vertex AI or Foundry) in addition to the Claude API for redundancy.
- Run one long-horizon workflow on Fable 5 in parallel with Opus 4.8 for a week and score the outputs on your own eval set.
- Stand up the four-metric dashboard (refusal rate, fallback latency, per-workflow cost, output quality) before any broader rollout.
If you want a Mythos-class production stack designed and shipped cleanly inside your AI engineering org with model routing, refusal handling, fallback, and observability built in, let’s talk.
Related Espressio guides
- Claude Fable 5: The Complete Guide to Anthropic’s New Mythos-Class Model
- Claude Fable 5 Pricing Explained: $10 / $50 per Million Tokens in Practice
- Inside Stripe’s 50M-Line Ruby Migration with Claude Fable 5
- Claude Fable 5 vs GPT-5 vs Gemini 3: Frontier Benchmarks Compared
- Claude Mythos 5 Explained: Project Glasswing and the Trusted Access Tier
- Claude API for Marketing Teams: Complete Setup Guide 2026

