
Luka Mrkić
Head of BD
Insights, strategies, and real-world playbooks on AI-powered marketing.
APR 30, 2026
How to Automate Content Pipelines with Claude and AWS
Over 100,000 teams now run Claude on Amazon Bedrock, yet most content teams still trigger it the same way: open a chat window, type a prompt, copy the output. That workflow doesn’t scale. A team publishing 50 pieces a week can’t staff enough manual API calls to keep up.
AWS makes it possible to wire Claude into an event-driven pipeline that runs without anyone at the keyboard. A brief drops into S3 and a structured draft appears in your CMS 90 seconds later. The choice of architecture (which AWS services to connect and in what sequence) determines whether that pipeline handles 10 pieces a week or 10,000.
If you’re earlier in the journey, automating marketing briefs with Claude and Slack is the faster entry point before committing AWS infrastructure.
Key Takeaways
- 100,000+ teams run Claude on Amazon Bedrock (Anthropic, April 2026); five architecture paths suit different pipeline scales.
- Bedrock Prompt Caching cuts inference costs by up to 90%; a 10,000-document monthly pipeline drops from ~$450 to under $100.
- 88% of companies use AI in at least one function; only 6% capture 5%+ EBIT impact (McKinsey, 2025). Production-grade pipeline infrastructure is what separates them.
Why do content teams use AWS instead of the Claude API directly?
Over 100,000 customers now run Claude on Amazon Bedrock; it’s the most widely deployed path for enterprise Claude integrations (Anthropic, April 2026). The McKinsey State of AI 2025 report found 88% of organizations use AI in at least one business function, but only 6% qualify as high performers capturing 5% or more EBIT impact. Production-grade infrastructure is what separates those two groups.
The direct Claude API (api.anthropic.com) is the right starting point for individual use and small-team prototyping. Bedrock becomes worth the setup when three conditions appear: your data already lives in AWS (S3, RDS, DynamoDB), your security team requires audit trails and VPC isolation, or your pipeline runs at a volume where Provisioned Throughput pricing saves money over on-demand calls.
Claude Sonnet 4.6 returns identical output on both endpoints. Bedrock wraps each call in AWS IAM routing, CloudTrail audit logging, and VPC isolation. For teams in regulated industries, that infrastructure is the approval the security team needs. Bedrock also eliminates cross-origin data egress costs when your S3 documents stay inside the same AWS region as your Bedrock endpoint, real cost savings for pipelines processing thousands of PDFs monthly.
The McKinsey State of AI 2025 report shows that organizations capturing real EBIT impact from AI have moved from experiments to production infrastructure. AWS is what that scale requires.
What are the five ways to run Claude on AWS?
AWS Step Functions integrates natively with more than 9,000 API actions across 200+ services, including direct Amazon Bedrock invocation, meaning a multi-step Claude content pipeline (S3 upload → Claude draft → review trigger → CMS publish) can be built without any custom Lambda orchestration code (AWS, 2025). Each path below uses Bedrock as the Claude access layer and adds orchestration on top.
| Path | Setup | Best For | Max Task Duration | Infra Cost |
|---|---|---|---|---|
| Bedrock standalone | 15 min | Direct SDK calls, prototypes | No limit | $0 beyond inference |
| Lambda + Bedrock | 30–45 min | Event-triggered single-step tasks | 15 min (Lambda max) | ~$0.10/1,000 invocations |
| S3 + Lambda + Bedrock | 1–2 hrs | Bulk document processing | 15 min | ~$0.10 + S3 costs |
| Step Functions + Bedrock | 2–4 hrs | Multi-step pipelines with branching | Unlimited | ~$0.025/1,000 transitions |
| EventBridge + Step Functions | 4–8 hrs | Long-running inference, enterprise async | Unlimited | ~$1.00/M events |

For teams starting out, the Lambda + Bedrock path handles 95% of content pipeline use cases with less than an hour of setup. Move to Step Functions when you need parallel generation, human review gates, or retry logic that Lambda chains can’t provide cleanly.
How do you set up Claude on Amazon Bedrock?
Bedrock is the Claude access layer every path above uses. Claude Sonnet 4 on AWS Bedrock delivers 66.3 tokens per second, the fastest throughput among all tested providers for this model (Artificial Analysis, April 2026). Four steps get you to a first response.
Step 1. Enable model access in the AWS Console. Navigate to Amazon Bedrock → Model access → Request access for anthropic.claude-sonnet-4-6. As of late 2025, on-demand model access activates automatically on first call for serverless deployments.
Step 2. Install the Anthropic SDK with Bedrock support:
pip install "anthropic[bedrock]"Step 3. Attach an IAM role with bedrock:InvokeModel permission to your Lambda execution role.
Step 4. Make your first call:
import anthropic
client = anthropic.AnthropicBedrock(aws_region="us-east-1")
response = client.messages.create(
model="anthropic.claude-sonnet-4-6",
max_tokens=2048,
messages=[{
"role": "user",
"content": "Write a 300-word product description for a B2B SaaS analytics tool."
}]
)
print(response.content[0].text)The IAM permission most teams miss: bedrock:InvokeModel and bedrock:InvokeModelWithResponseStream are separate permissions. Teams that want real-time streaming output set up bedrock:InvokeModel only and find their streaming calls return a 403. Add both permissions from the start. For cross-region inference endpoints, you also need bedrock-runtime:InvokeModel for the inference profile ARN alongside the base model ARN.
How do you build a serverless content pipeline with Lambda and S3?
A brief lands in S3 and Claude generates a structured draft without anyone initiating the call. At Claude Sonnet 4.5 on-demand pricing, that generation costs $0.03–$0.08 per 1,000-word article depending on system prompt length and output complexity (AWS Bedrock pricing, 2026). At 500 articles per month, the full inference bill runs under $40.
The core architecture connects four services:
Step 1. S3 PUT event: a new brief file triggers an S3 Event Notification to an SQS queue.
Step 2. SQS queue: the event lands in a queue rather than calling Lambda directly. This decoupling is the key architectural decision explained below.
Step 3. Lambda function: polls SQS, calls bedrock:InvokeModel with the brief as user content, stores the generated draft back in S3 or DynamoDB.
Step 4. Output: draft available for human review in S3, or pushed to a CMS staging endpoint via webhook.
The failure mode AWS documentation skips: if you route Lambda through API Gateway synchronously (the pattern every tutorial shows), API Gateway imposes a default 29-second timeout. Claude Sonnet generating a 1,000-word draft takes 15–25 seconds under normal load. A longer brief, a more complex system prompt, or Sonnet on a busy endpoint can push that to 35–45 seconds. The fix is decoupling: API Gateway returns 202 Accepted immediately, Lambda writes the job to SQS, a separate consumer Lambda processes the generation asynchronously, and the client polls a status endpoint or receives a webhook callback. This pattern handles any generation duration without modification.
A serverless Claude content pipeline on AWS (S3 upload triggering Lambda that calls Bedrock and stores output back in S3) costs $0.03–$0.08 per 1,000-word draft at Claude Sonnet 4.5 pricing. At 500 articles per month, that’s $15–$40 in inference costs, with Lambda and SQS adding under $1 on top.
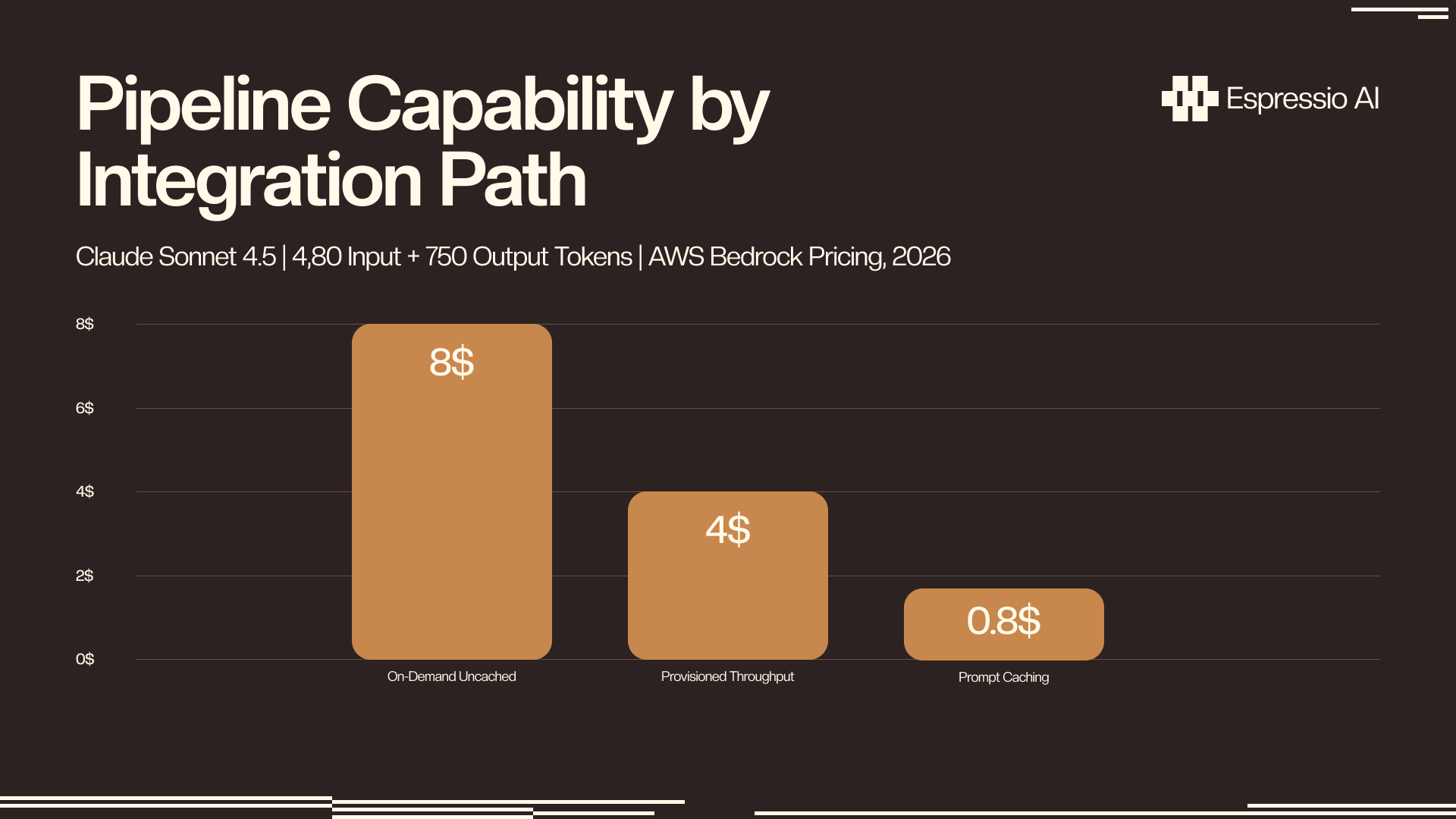
At 500 articles per month, uncached on-demand costs roughly $40. Cached costs under $4. Teams using HubSpot can connect the Lambda output stage directly to CRM deal sequences using Claude’s HubSpot integration for AI sales follow-up.
How does prompt caching reduce content pipeline costs on AWS?
Amazon Bedrock Prompt Caching reduces inference costs by up to 90% and latency by up to 85% by storing frequently reused prompt prefixes in cache between calls (AWS, 2025–2026). For content pipelines that run the same brand-voice instructions or editorial guidelines on every document, caching converts a per-call cost into a per-session cost.
The implementation requires one change to your Bedrock call. Add cache_control to the system prompt block:
response = client.messages.create(
model="anthropic.claude-sonnet-4-6",
max_tokens=2048,
system=[{
"type": "text",
"text": "You are a senior content writer for Acme Corp...\n[2,000 tokens of brand guidelines]",
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": brief_text}]
)The cache TTL is 5 minutes for on-demand models. Provisioned Throughput extends that window; this suits pipelines that batch documents in runs rather than one at a time.
For a content pipeline running the same brand-voice system prompt across 10,000 documents monthly, Amazon Bedrock Prompt Caching cuts Bedrock spend from roughly $450 to under $100. The reduction comes from storing frequently reused prompt prefixes in cache between calls; the system prompt pays a one-time cache write fee and costs 10% of standard input pricing on every subsequent call (AWS, 2025–2026).

The 85% latency reduction matters as much as the cost savings for production pipelines. A 20-second uncached generation becomes a 3-second cached call. At 500 articles per month, that’s roughly 140 minutes saved on generation time per batch.
How do you orchestrate content workflows with Step Functions?
AWS Step Functions integrates natively with 9,000+ API actions from 200+ services, including direct Bedrock invocation without any Lambda wrapper between them (AWS, 2025). For content pipelines with more than two sequential steps, Step Functions replaces fragile Lambda chains with a visual workflow that handles retries, timeouts, parallel branches, and human review gates declaratively.
A typical content pipeline state machine runs five states:
Step 1. Input validation: verify the incoming brief has all required fields before invoking Bedrock.
Step 2. Claude draft: invoke Bedrock directly via the Step Functions SDK integration; no Lambda wrapper required.
Step 3. Parallel review: run a brand-voice check and SEO structure check simultaneously using a Parallel state, cutting review time compared to sequential checks.
Step 4. Human review gate: pause using waitForTaskToken until a reviewer approves in your CMS; Step Functions holds state for up to one year.
Step 5. CMS publish: send the approved draft to your publishing endpoint via an HTTP API call.
The Map state handles batch generation: feed an array of briefs and Step Functions spawns a parallel Bedrock call for each one. For arrays under 40 items, use the inline Map. For larger batches (monthly content calendars, bulk product descriptions), use Distributed Map with no concurrency cap.
A Forrester Total Economic Impact study for enterprise content automation found 333% ROI and an 85% reduction in content review time (Forrester / WRITER, May 2025). The Step Functions pattern, with its parallel review states and human-approval gate, is the architecture that produces those review-time numbers.

If you’re looking to integrate AI into your content workflows, from pipeline automation to distribution and reporting, get in touch with us and we’ll map out where automation adds the most leverage for your team.
Frequently Asked Questions
What is the difference between the Claude API and Amazon Bedrock?
The Claude API (api.anthropic.com) is Anthropic’s direct endpoint; it requires no AWS infrastructure and takes minutes to start. Bedrock is the same Claude models hosted inside your AWS account, with IAM routing, CloudTrail logging, and HIPAA/SOC2 compliance built in. Bedrock adds no markup over on-demand API pricing. Provisioned Throughput (30–50% cost reduction at scale) is Bedrock-only.
How much does a Claude content pipeline on AWS cost?
Claude Sonnet 4.5 on-demand runs $0.03–$0.08 per article (4,000 input + 750 output tokens). At 500 articles per month: $15–$40 uncached, under $5 with Prompt Caching. Lambda and Step Functions add under $1 at that volume. Provisioned Throughput cuts per-token costs 30–50% for teams running 10,000+ monthly requests (AWS Bedrock pricing, 2026).
Can Claude on Bedrock process documents stored in S3?
Yes. The S3 + Lambda + Bedrock pattern (S3 PUT → SQS → Lambda → Bedrock) processes PDFs, images (JPEG, PNG, WebP), and plain text natively. Claude Sonnet 4.6’s 1M-token context window handles documents up to roughly 750,000 words per call. The AWS ML Blog’s intelligent document processing reference architecture is the canonical starting point, updated October 2025.
What is the AWS MCP proxy and how does it work with Claude?
AWS released an open-source MCP (Model Context Protocol) proxy in October 2025, connecting Claude Code, Claude Desktop, and Cursor to AWS-hosted services via SigV4 authentication. Content engineers can trigger Step Functions workflows, query S3 outputs, or inspect DynamoDB results without leaving their IDE. Official MCP servers for AWS services are open-source at github.com/awslabs/mcp.
Conclusion
Five paths connect Claude to AWS content automation, and the right one matches your pipeline’s complexity:
- Bedrock standalone: direct SDK calls, prototypes, scripts with no event triggers
- Lambda + Bedrock: event-triggered single-step generation from S3 uploads or API calls
- S3 + Lambda + Bedrock: bulk document processing with SQS decoupling and the 29-second timeout fix
- Step Functions + Bedrock: multi-step pipelines with parallel reviews, retry logic, and human approval gates
- EventBridge + Step Functions: enterprise-scale async pipelines where generation duration is unbounded
Start with Lambda + Bedrock for most use cases. Add Prompt Caching on day one; the code change is two lines and the cost impact is immediate. Upgrade to Step Functions when your pipeline needs branching or human gates.
For teams connecting Claude to Google Analytics 4, the pipeline produces content and GA4 measures it; the two together close the brief-to-performance loop. For the full picture of how agencies deploy this stack end to end, how to build an AI operating system for your agency shows what that looks like end to end.

