
Luka Mrkić
Head of BD
Insights, strategies, and real-world playbooks on AI-powered marketing.
MAY 7, 2026
How to Build a LangChain Lead Qualification Agent (2026)

The average B2B company responds to inbound leads in 47 hours, according to a Drift study of 433 B2B websites. By then, most buyers have moved on. Leads contacted within 5 minutes are 21 times more likely to qualify than those reached after 30 minutes (InsideSales.com / MIT Sloan, 2024). That gap is an architecture problem, and it has a direct solution.
In December 2025, LangChain’s own sales team built a GTM agent to handle lead qualification in real time. By March 2026, lead-to-qualified-opportunity conversion was up 250% and each SDR had reclaimed 40 hours per month (LangChain, 2026). This tutorial builds the same architecture: a stateful LangGraph agent that ingests leads, scores them against BANT criteria, and routes them to your CRM automatically.
Key Takeaways
- LangChain’s own GTM agent increased lead-to-qualified-opportunity conversion by 250% and saved each SDR 40 hours per month (LangChain, 2026).
- Leads contacted within 5 minutes are 21× more likely to qualify than those reached after 30 minutes (InsideSales.com / MIT Sloan).
- Only 44% of organizations use lead scoring today; automating qualification with LangGraph puts you ahead of the majority (Landbase, 2026).
- Stack for this build: LangGraph 0.3+, GPT-4o mini, Salesforce or HubSpot, LangSmith tracing.
Why does manual lead qualification fail?
Only 44% of organizations use lead scoring, and 67% of lost sales result from inadequate lead qualification (Landbase, 2026). Qualified leads convert at 40% on average; unqualified prospects convert at 11%. That 3.6x gap grows wider the longer a rep spends working the wrong pipeline.
The problem is structural. Reps need to be available at the moment a lead arrives, apply the same ICP criteria they used yesterday, and respond fast enough to matter. All three conditions break regularly. An agent runs the same BANT criteria on every lead, in seconds, regardless of when it arrives.
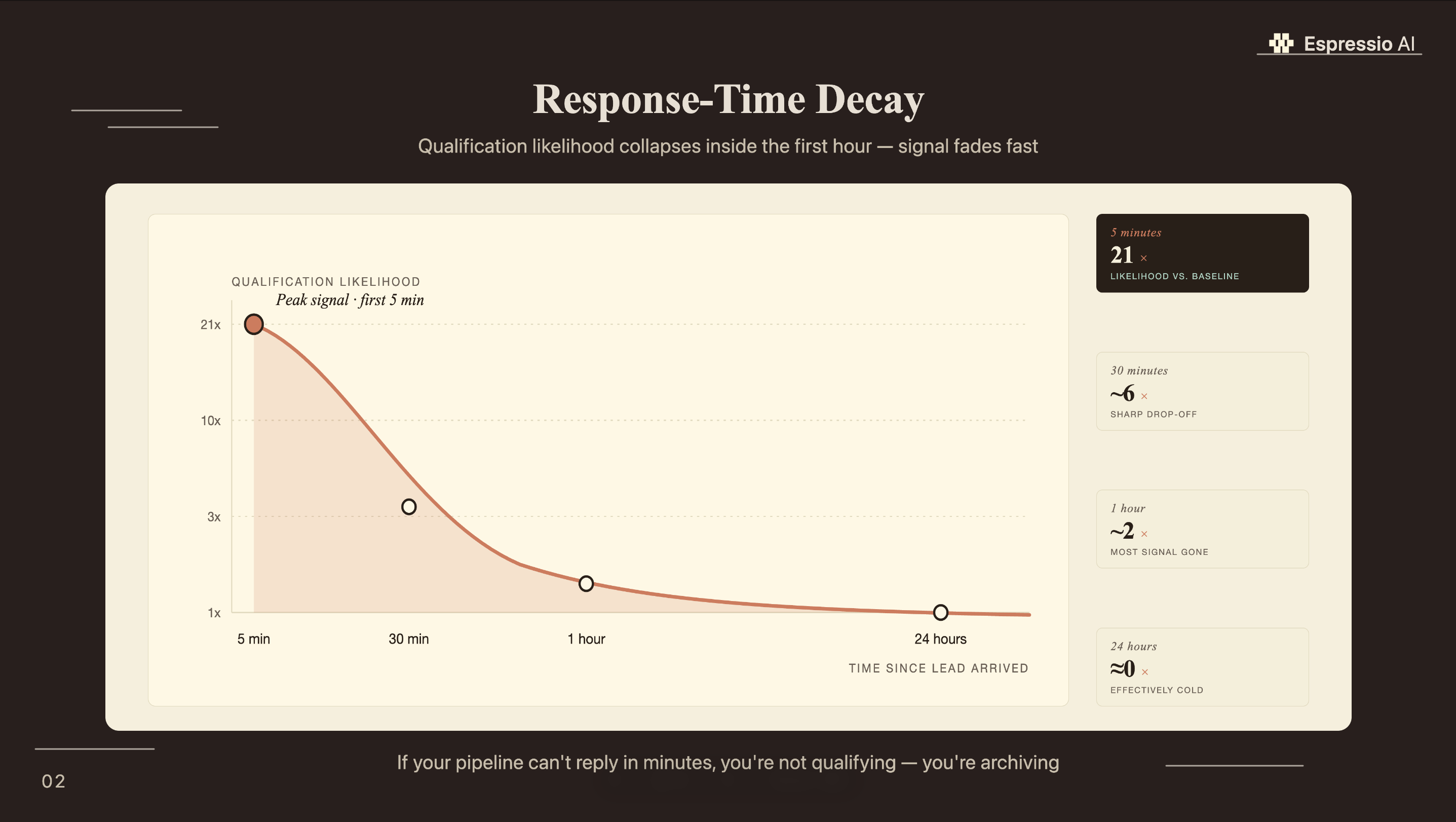
LangChain’s own GTM agent is the most compelling proof point for this architecture, and it’s hiding in plain sight. The same company that built LangChain deployed a qualification agent for their own sales team and documented the result publicly. It’s first-party evidence from the framework’s creators that the technology works in production for exactly this use case.
For a broader look at how companies are building AI operations around agents like this, how Lunar Strategy built an AI operating system in 18 months covers the full stack that surrounds a qualification agent in a production content and sales workflow.
What does the LangGraph architecture look like?
LangGraph is LangChain’s stateful agent framework, recommended for production use as of v0.3+. The 2025 LangChain State of Agent Engineering survey (n=1,340 engineers) found that 57.3% of respondents have AI agents in production. Teams running multi-step workflows like lead qualification consistently report LangGraph as the production choice over bare LCEL-based agents.
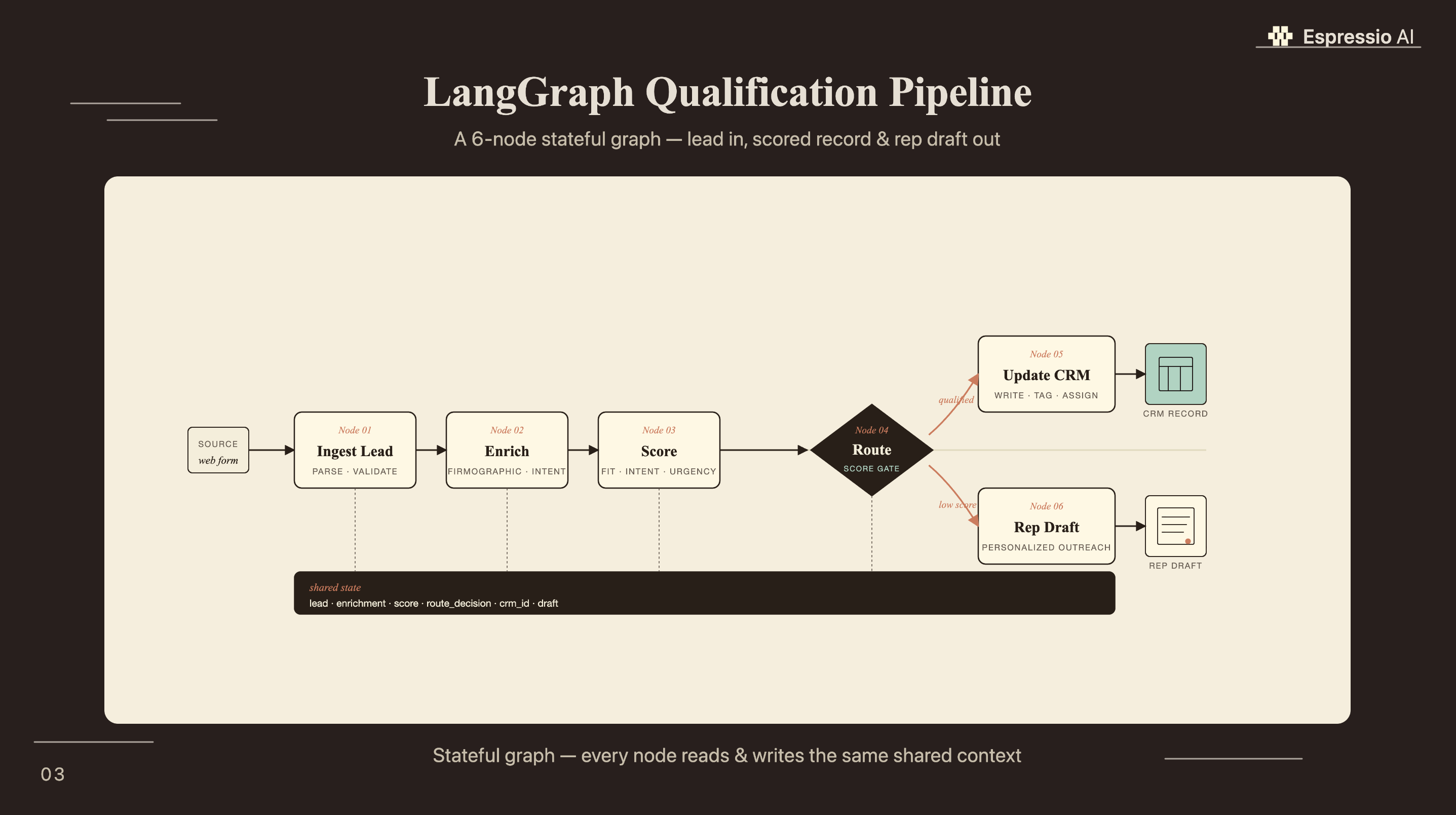
The qualification pipeline has six nodes, each responsible for one decision:
- Ingest Lead - receive lead data from web form, CRM webhook, or CSV
- Enrich Lead - pull firmographic data (company size, industry, revenue signals)
- Score Lead - apply BANT criteria, output scores 0–10 per dimension
- Route Decision - conditional edge: SQL, nurture, or disqualify
- Update CRM - write score and routing decision back to Salesforce or HubSpot
- Send Rep Draft - generate a personalized outreach draft for SQL leads
The LeadState TypedDict holds everything across all six nodes:
from langgraph.graph import StateGraph
from typing import TypedDict, Optional
class LeadState(TypedDict):
# Identity
lead_id: str
email: str
company: str
title: str
# Enrichment output
company_size: Optional[int]
industry: Optional[str]
annual_revenue: Optional[float]
# BANT scores (0–10 each)
budget_fit: Optional[int]
authority_fit: Optional[int]
need_fit: Optional[int]
timing_fit: Optional[int]
# Composite
icp_match: Optional[bool]
lead_score: Optional[int] # sum of BANT scores, 0–40
next_action: Optional[str] # "sql_route" | "nurture" | "disqualify"
rep_draft: Optional[str]Why LangGraph over a bare LCEL agent? LCEL agents run tool calls in a loop without persistent state between steps. If the enrichment tool times out and you retry, the agent starts fresh with no memory of what it already retrieved. LangGraph’s checkpointing keeps the LeadState object alive across retries, tool failures, and even human-in-the-loop interrupts, which matters when you’re writing results to a live CRM.
How do you install and configure LangChain for lead qualification?
LangChain appears in 34.3% of all agentic AI engineering job listings as of April 2026 (the top framework by a wide margin), and the combined LangChain + LangGraph ecosystem covers 39.9% of roles requiring agentic AI skills (agentic-engineering-jobs.com, April 2026, analysis of n=534 listings on that platform). The install is straightforward; the configuration choices are where teams make costly mistakes.
pip install langchain langgraph langchain-openai langchain-community \
langsmith python-dotenv simple-salesforce hubspot-api-client# .env - required environment variables
OPENAI_API_KEY=sk-...
LANGCHAIN_API_KEY=ls__...
LANGCHAIN_TRACING_V2=true
LANGCHAIN_PROJECT=lead-qualification-agent
# CRM credentials - Salesforce OR HubSpot
SALESFORCE_USERNAME=your@email.com
SALESFORCE_PASSWORD=yourpassword
SALESFORCE_TOKEN=yoursecuritytoken
HUBSPOT_TOKEN=pat-na1-...A few decisions to make before you start:
LLM choice: GPT-4o mini handles BANT scoring well at $0.003–$0.008 per lead. GPT-4o improves reasoning accuracy on ambiguous titles and industries but costs roughly 10x more per run. For most B2B qualification use cases, mini is the right starting point.
Python version: LangGraph 0.3+ requires Python 3.10 or higher. Check yours with python --version before starting.
LangSmith: Set LANGCHAIN_TRACING_V2=true from day one. You’ll need traces to debug misrouting decisions, and retroactively adding tracing to a running agent is painful. The free tier covers 5,000 traces per month, which handles 5,000 leads.
If your team is also evaluating the Claude API as an alternative LLM backbone for this pipeline, setting up the Claude API for marketing teams covers the authentication and rate-limit decisions that apply equally to a qualification agent workload.
How do you build the BANT scoring and routing nodes?
Companies using lead scoring see 138% ROI compared to 78% without it (Landbase / LLCBuddy, 2026). The difference is consistent ICP logic, and that’s what the qualification nodes encode. Here’s the full implementation:
Node 1: Enrich the lead
from langchain_community.tools import DuckDuckGoSearchRun
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
search = DuckDuckGoSearchRun()
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
@tool
def enrich_lead(company: str, title: str) -> dict:
"""Pull firmographic signals for a lead's company."""
raw = search.run(f"{company} employees revenue industry site:linkedin.com OR site:crunchbase.com 2026")
# Extract structured data via LLM
extraction_prompt = f"""
Extract from this text: company size (employees), industry, and revenue signals.
Text: {raw}
Return JSON only: {{"company_size": int_or_null, "industry": "string_or_null", "revenue_signal": "string_or_null"}}
"""
result = llm.invoke(extraction_prompt)
import json
try:
return json.loads(result.content)
except Exception:
return {"company_size": None, "industry": None, "revenue_signal": None}Node 2: Score BANT
BANT_PROMPT = """
You are a B2B lead qualification specialist. Score this lead on BANT (0–10 each).
Budget (0–10): Does company size/revenue suggest they can afford a $25K–$100K engagement?
Authority (0–10): Is the title a buying decision-maker? (VP, Director, C-suite = high; IC = low)
Need (0–10): Does the company size and industry match our ICP (B2B SaaS, 50–500 employees)?
Timing (0–10): Any active buying signals? (recent funding, job listings for roles we solve, tech migrations)
Lead:
Company: {company}
Title: {title}
Company size: {company_size}
Industry: {industry}
Revenue signal: {revenue_signal}
Respond in JSON only:
{{"budget": 0-10, "authority": 0-10, "need": 0-10, "timing": 0-10, "reasoning": "one sentence"}}
"""
def score_lead_node(state: LeadState) -> LeadState:
prompt = BANT_PROMPT.format(**state)
result = llm.invoke(prompt)
import json
scores = json.loads(result.content)
total = scores["budget"] + scores["authority"] + scores["need"] + scores["timing"]
return {
**state,
"budget_fit": scores["budget"],
"authority_fit": scores["authority"],
"need_fit": scores["need"],
"timing_fit": scores["timing"],
"lead_score": total,
}Node 3: Route decision (conditional edge)
def route_lead(state: LeadState) -> str:
score = state.get("lead_score", 0)
if score >= 28: # 70%+ of max 40 → SQL
return "sql_route"
elif score >= 16: # 40–69% → nurture sequence
return "nurture"
else: # below 40% → disqualify
return "disqualify"When tuning routing thresholds, start at 70% (score ≥ 28) and calibrate over 30 days by comparing agent routing decisions against rep judgments on the same leads. If the SQL-to-close rate is lower than baseline, the threshold is too permissive. If reps are complaining about pipeline volume dropping, it’s too strict. Most B2B SaaS teams settle between 65–75% after the first calibration cycle.
For a comparison of how this sequential scoring pattern maps to a multi-agent crew architecture, building a CrewAI content research agent shows the same 4-node pipeline applied to content workflows, with useful parallels to where LangGraph state and CrewAI crew patterns converge.
How do you connect the agent to Salesforce and HubSpot?
LangChain ships native Salesforce toolkits via langchain-community, and HubSpot integrates through the official Python client. This CRM routing step is what turns a qualification prototype into a production system, and it’s the step that zero competing tutorials cover.
Salesforce integration
from simple_salesforce import Salesforce
import os
sf = Salesforce(
username=os.getenv("SALESFORCE_USERNAME"),
password=os.getenv("SALESFORCE_PASSWORD"),
security_token=os.getenv("SALESFORCE_TOKEN")
)
SQL_REP_ID = "0050x000001234AAA" # replace with your rep's Salesforce user ID
NURTURE_QUEUE_ID = "00G0x000001234BBB" # replace with your nurture queue ID
def update_salesforce(state: LeadState) -> LeadState:
sf.Lead.update(state["lead_id"], {
"Lead_Score__c": state["lead_score"],
"Qualification_Status__c": state["next_action"],
"BANT_Budget__c": state["budget_fit"],
"BANT_Authority__c": state["authority_fit"],
"BANT_Need__c": state["need_fit"],
"BANT_Timing__c": state["timing_fit"],
"OwnerId": SQL_REP_ID if state["next_action"] == "sql_route" else NURTURE_QUEUE_ID,
})
return stateNote: The four BANT_*__c fields are custom fields; create them in Salesforce Setup before deploying. Each should be a Number(3,0) field type.
HubSpot integration
from hubspot import HubSpot
hs = HubSpot(access_token=os.getenv("HUBSPOT_TOKEN"))
def update_hubspot(state: LeadState) -> LeadState:
hs.crm.contacts.basic_api.update(
contact_id=state["lead_id"],
simple_public_object_input={
"properties": {
"hs_lead_status": "QUALIFIED" if state["next_action"] == "sql_route" else "IN_PROGRESS",
"lead_score": str(state["lead_score"]),
"bant_reasoning": state.get("reasoning", ""),
}
}
)
return stateRep draft generation
For SQL leads, the agent generates a short personalized outreach draft before routing:
REP_DRAFT_PROMPT = """
Write a concise outreach message for a sales rep to send. Keep it under 80 words.
Casual but professional - no subject line needed.
Lead: {title} at {company}
Lead score: {lead_score}/40
Key signals: {reasoning}
The rep should come across as knowledgeable about the company's situation.
"""
def generate_rep_draft(state: LeadState) -> LeadState:
if state.get("next_action") != "sql_route":
return state
prompt = REP_DRAFT_PROMPT.format(**state)
result = llm.invoke(prompt)
return {**state, "rep_draft": result.content}For teams already running Salesforce proposal automation, automating Salesforce proposals with Claude shows how this rep draft output can feed directly into a proposal workflow, closing the loop from qualification to proposal in a single pipeline.
How do you run and debug the agent with LangSmith?
Eighty-nine percent of engineers running AI agents in production have implemented some form of observability tooling (LangChain State of Agent Engineering, n=1,340, 2025). For a lead qualification agent, tracing is a production requirement. When the agent misroutes a lead - and it will, during calibration - you need to see exactly which node produced the wrong score and why.
LangSmith tracing is already configured if you set the environment variables in the setup step. Once running, every lead generates a trace. The enrichment node shows what the search tool returned and how the LLM extracted structured data from it. The scoring node logs the full BANT prompt, the LLM’s JSON response, and the computed total. The route decision shows which conditional branch was taken, and the CRM node confirms whether the Salesforce/HubSpot write succeeded.
The two most common failure patterns in qualification agents: the enrichment step returns stale or ambiguous data (a company that recently rebranded shows the old employee count), and the BANT scoring prompt anchors too heavily on job title while underweighting timing signals. LangSmith traces make both patterns visible within the first week of live routing.
To run the full graph:
from langgraph.graph import StateGraph, END
workflow = StateGraph(LeadState)
workflow.add_node("enrich", enrich_lead_node)
workflow.add_node("score", score_lead_node)
workflow.add_node("update_crm", update_salesforce) # or update_hubspot
workflow.add_node("draft", generate_rep_draft)
workflow.set_entry_point("enrich")
workflow.add_edge("enrich", "score")
workflow.add_conditional_edges("score", route_lead, {
"sql_route": "draft",
"nurture": "update_crm",
"disqualify": END,
})
workflow.add_edge("draft", "update_crm")
workflow.add_edge("update_crm", END)
app = workflow.compile()
# Run a lead
result = app.invoke({
"lead_id": "00Q0x000001234CCC",
"email": "jane.doe@acme.com",
"company": "Acme Corp",
"title": "VP of Marketing",
})
print(result["next_action"], result["lead_score"], result["rep_draft"])What results does a LangChain qualification agent deliver?
LangChain’s own GTM agent delivered 250% higher lead-to-qualified-opportunity conversion in 3 months, recovered 40 hours per SDR per month, and drove a 97% increase in follow-up activity on lower-intent leads that reps had previously ignored (LangChain, 2026). For a 5-person SDR team, that’s 200 hours per month redirected from admin to selling.

Realistic deployment expectations: Weeks 1–2, run the agent in shadow mode. It classifies leads but doesn’t write to the CRM; compare its routing decisions against what your reps would have done. Week 3 is calibration: adjust the SQL threshold based on where the agent’s routing diverges from rep judgment on unambiguous leads. Month 2 is live routing with LangSmith monitoring: watch for enrichment failures and scoring outliers. By month 3, you have enough data to measure the delta in SQL-to-close rate and SDR time on admin tasks.
In our own client deployments, the first calibration run reveals that 30–40% of leads reps were manually pursuing fall below the agent’s SQL threshold. This doesn’t mean the reps were wrong. It usually means the qualification criteria were never written down consistently. The agent makes implicit standards explicit, which is often the most valuable outcome of the first deployment.
If you’re looking to integrate AI into your sales qualification workflows, get in touch with us and we’ll map out where automation adds the most value for your team.
Frequently Asked Questions
How long does it take to build a LangChain lead qualification agent?
A minimal LangGraph agent - ingest, score, route - can be running in 2 to 3 days of focused development. Adding Salesforce or HubSpot integration and LangSmith observability adds another 3 to 5 days. Production-ready deployment with threshold calibration typically takes 2 to 4 weeks total, based on team experience with LangGraph and existing CRM configuration.
What is the ROI of an AI lead qualification agent?
Companies using lead scoring see 138% ROI compared to 78% without it (Landbase, 2026). LangChain’s own GTM agent delivered 250% higher lead-to-qualified-opportunity conversion in 3 months, with each SDR reclaiming 40 hours per month (LangChain, 2026). The primary source of gains is response time: AI agents respond in seconds, while the average human sales team responds to inbound leads in 47 hours.
Does LangChain integrate with Salesforce and HubSpot?
Yes. LangChain ships native Salesforce toolkits via the langchain-community package and Composio’s MCP toolkit. HubSpot integrates via the official hubspot-api-client Python library. Both integration patterns are shown in the CRM section of this guide. Lead records can be updated, ownership reassigned, and rep drafts generated - all within the LangGraph workflow, without leaving Python.
What is LangGraph and why use it instead of LangChain agents?
LangGraph is LangChain’s stateful agent framework, recommended for production as of v0.3+. Unlike LCEL-based agents, LangGraph maintains a typed state object across tool calls, supports conditional routing - SQL, nurture, or disqualify - and enables human-in-the-loop interrupts. For multi-step workflows like lead qualification, LangGraph provides the state persistence and error recovery that bare LCEL agents lack.
How much does it cost to run a LangChain lead qualification agent?
Using GPT-4o mini as the scoring LLM, a typical lead qualification run - enrichment plus BANT scoring plus draft generation - costs approximately $0.003 to $0.008 per lead in API tokens. For 1,000 leads per month, that’s $3 to $8 in model costs. LangSmith is free for up to 5,000 traces per month. Total infrastructure cost for a 1,000-lead-per-month agent runs under $50 per month.
Conclusion
The architecture in this guide mirrors what LangChain’s own sales team deployed in December 2025: a LangGraph state machine that runs six nodes (enrich, score, route, update, draft) automatically from lead arrival to CRM routing. What took 47 hours of average human response time now takes seconds. What produced inconsistent qualification decisions now runs against the same BANT criteria every time.
The three things that determine whether this deployment succeeds: clean ICP definition before you write a single line of the scoring prompt, a shadow-mode calibration period before live routing, and LangSmith tracing from day one. Skip any of them and you’re debugging misroutes without the data you need.
For teams looking to extend this beyond qualification into a full AI sales operating system, how Lunar Strategy built an AI operating system in 18 months covers the infrastructure layer that surrounds individual agents like this one.

