
Luka Mrkić
Head of BD
Insights, strategies, and real-world playbooks on AI-powered marketing.
MAY 6, 2026
How to Build a CrewAI Content Research Agent Step by Step

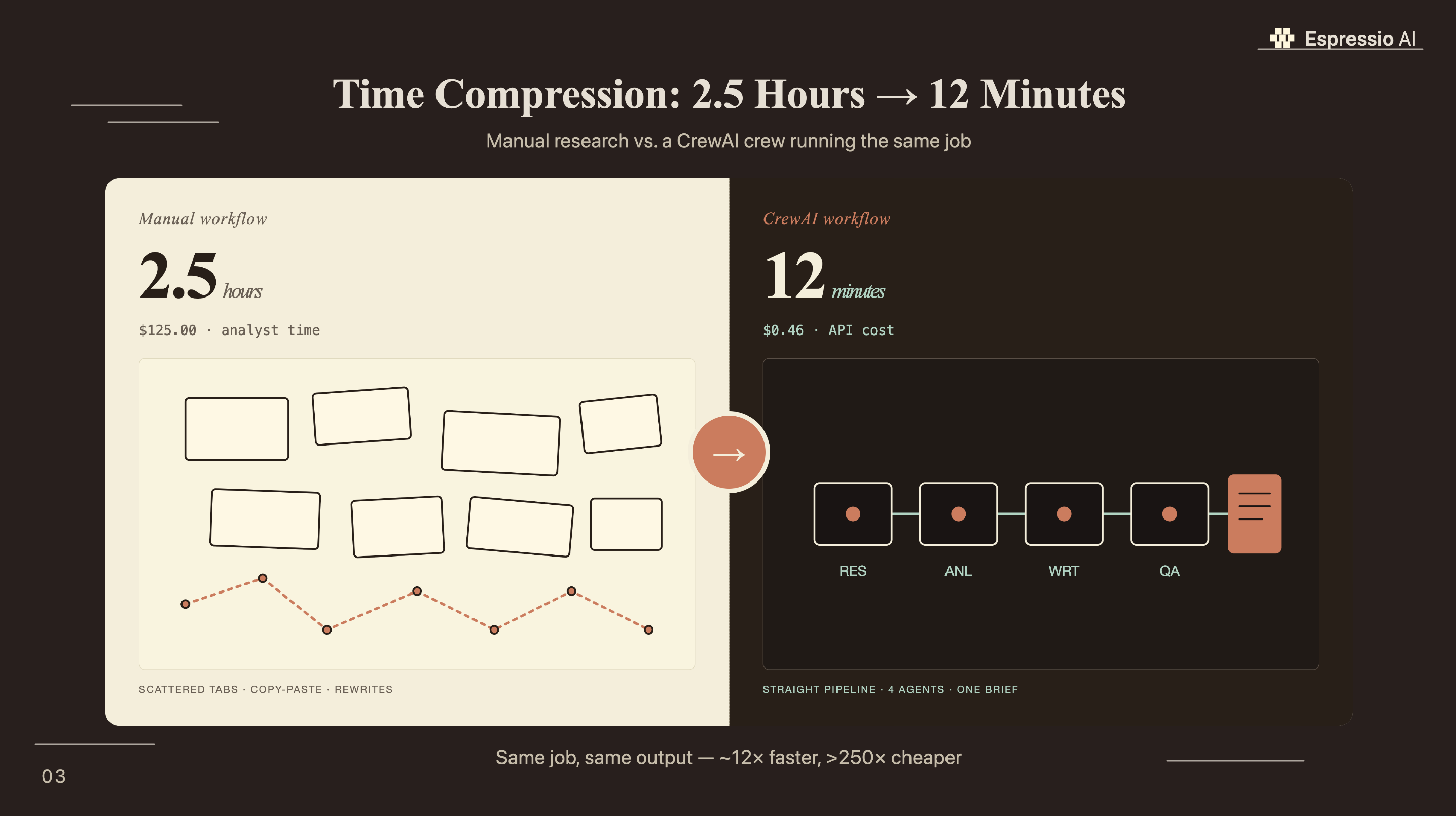
Content research is where most marketing teams bleed time. A single B2B topic brief (keyword gaps, competitor analysis, source gathering, section structure) takes 2.5 hours when done manually. A properly configured CrewAI crew runs the same job in under 15 minutes.
This guide builds a 4-agent content research crew from a fresh Python environment to a QA-reviewed brief sitting in your output folder. You get the full agents.yaml, tasks.yaml, and crew.py configs, plus the SerperDev setup that gives your agents live web search.
Key Takeaways
- CrewAI powers over 2 billion agent executions and is used by 60%+ of Fortune 500 companies (CrewAI OSS 1.0 Blog, Oct 2025). It’s production infrastructure, not a side project.
- A 4-agent content research crew (Researcher, Analyst, Brief Writer, QA Reviewer) completes a full topic brief in under 15 minutes at a cost of roughly $0.46 per run.
- Setup takes under 30 minutes: install via pip, configure agents and tasks in YAML, add API keys, run
crewai run.
What is a CrewAI content research agent?
CrewAI has logged over 2 billion agent executions and is used by more than 60% of Fortune 500 companies, with 47.8K GitHub stars and 5 million monthly PyPI downloads as of April 2026 (CrewAI OSS 1.0 Blog, Oct 2025; GetPanto, Apr 2026). Those numbers tell you what you’re building on: a framework Fortune 500 teams run in production.
A CrewAI content research agent is a software process where multiple AI instances (agents) each hold a specific role, a set of tools, and a task. They hand results to each other in sequence, like a small editorial team. Each agent only does its defined job. The Research Specialist pulls sources; the Content Analyst synthesizes them into angles. The Brief Writer structures the output, and the QA Reviewer checks it before the file lands in your folder.
The agentic AI market is on track to grow from $7.29 billion in 2025 to $139.19 billion by 2034 at a 40.5% compound annual growth rate (Fortune Business Insights, Apr 2026). Teams building these workflows now are compressing a 2.5-hour research job to 12 minutes, accumulating that advantage with every article they publish.
CrewAI’s open-source framework crossed 2 billion agent executions over the past 12 months, backed by $18 million in funding from Insight Partners and adopted by 150 enterprise customers within six months of its initial release (GetPanto, Apr 2026). For B2B content teams, this adoption trajectory signals that multi-agent research automation has passed the proof-of-concept stage.

How do you install and configure CrewAI for content research?
CrewAI runs on Python 3.10 through 3.13. The full install is a single pip command, and the project scaffold takes 30 seconds (CrewAI Documentation, 2026). Setup that used to require days of LangChain boilerplate is now under five minutes.
Start with a virtual environment, then install:
python -m venv .venv && source .venv/bin/activate
pip install crewai crewai-toolsScaffold the project:
crewai create crew content-researcher
cd content-researcherThis generates the full project structure:
content-researcher/
├── src/
│ └── content_researcher/
│ ├── config/
│ │ ├── agents.yaml
│ │ └── tasks.yaml
│ ├── crew.py
│ └── main.py
├── .env
└── pyproject.tomlAdd your API keys to .env:
OPENAI_API_KEY=sk-your_openai_key_here
SERPER_API_KEY=your_serper_key_here
# To use Claude instead of OpenAI as your LLM backend:
# ANTHROPIC_API_KEY=your_anthropic_key_hereCrewAI defaults to GPT-4o-mini for cost-efficient structured tasks. For teams already using Claude for long-form generation, the Claude API setup guide for marketing teams covers model selection and how to swap CrewAI’s default LLM to Claude Sonnet for research-heavy tasks where context depth matters.
Get your free SerperDev key at serper.dev. The Developer plan provides 2,500 monthly searches for free, enough to run the crew on 250 research topics per month before hitting a billing event.
How do you define agents and tasks in CrewAI?
AI reduces document writing time by 87% and average task completion time by approximately 80% (Anthropic Research, Nov 2025). The gap between a 2-agent crew and a 4-agent crew comes down to role specificity: the more precisely each agent’s goal and backstory match the job, the better the output quality on the first run.
Open src/content_researcher/config/agents.yaml and replace the scaffolded content:
research_specialist:
role: >
Senior Content Research Specialist
goal: >
Find comprehensive, accurate information about {topic} from authoritative
sources — key statistics, trends, competitive content gaps, and expert data
backstory: >
You're a senior researcher with ten years of B2B content experience. You
know exactly where to find credible data, how to evaluate source quality,
and what a content team actually needs to produce a strong article. You
never invent statistics — every claim you report has a verifiable URL.
content_analyst:
role: >
Content Strategy Analyst
goal: >
Synthesize the research on {topic} into a structured analysis covering
the strongest arguments, content angles, and audience pain points to address
backstory: >
You bridge raw research and editorial strategy. You spot the insight buried
in a data point, identify what competitors have missed, and turn a pile of
URLs into a clear content angle with a defensible hook.
brief_writer:
role: >
Content Brief Writer
goal: >
Transform the analyst's findings into a complete, publish-ready content brief
for {topic}: headline options, section structure, assigned stats per section,
meta description, and FAQ questions
backstory: >
You've written over 500 content briefs for B2B SaaS and agency clients.
You know what editors and writers need to start: section goals, specific
data points per section, and a headline that balances search intent with
reader engagement. Your briefs get used, not ignored.
qa_reviewer:
role: >
Editorial QA Reviewer
goal: >
Review the content brief for {topic} and flag any unsupported claims,
missing sections, weak statistics, or structural gaps before it reaches a writer
backstory: >
You're the last check before a brief reaches a writer. You've seen what
happens when a brief skips source verification — the writer publishes a
wrong stat and the credibility damage lasts for months. You check every
number, every source URL, and every section gap.Now open src/content_researcher/config/tasks.yaml:
research_task:
description: >
Research {topic} thoroughly. Find: (1) at least 8 statistics from tier-1
or tier-2 sources published 2024-2026, (2) the top 5 ranking articles with
word count estimates and content gap notes, (3) the top 5 People Also Ask
questions for the primary keyword, (4) three content angles competitors
have missed. Report each statistic with: exact figure, source name, URL,
and publication date.
expected_output: >
A structured research report with 8+ cited statistics, competitor summary,
top 5 PAA questions, and three unique angle recommendations.
agent: research_specialist
analysis_task:
description: >
Using the research report, identify the strongest hook statistic, the most
defensible content angle, and the top three audience pain points for {topic}.
Flag any statistics that need additional verification.
expected_output: >
A 300-400 word content strategy memo covering: hook stat, content angle,
three audience pain points, recommended H2 structure (6-8 sections), and
any stats flagged for verification.
agent: content_analyst
context:
- research_task
brief_writing_task:
description: >
Write a complete content brief for {topic}. Include: three headline options,
meta description (150-160 characters with one statistic), H2 outline with
one assigned statistic per section, FAQ section with four questions, and
a recommended word count.
expected_output: >
A formatted markdown content brief ready to hand to a writer.
agent: brief_writer
context:
- research_task
- analysis_task
qa_review_task:
description: >
Review the content brief for {topic}. Check: (1) all statistics have source
URLs, (2) no section lacks a supporting data point, (3) the meta description
is 150-160 characters, (4) headline options include the primary keyword.
Flag issues with a specific fix recommendation.
expected_output: >
The final content brief beginning with "QA PASS" or "QA FAIL: [issues]",
followed by the approved or corrected brief.
agent: qa_reviewer
context:
- brief_writing_task
output_file: output/brief.mdIn Espressio’s testing, the backstory field in agents.yaml has more impact on output quality than any other single setting. An agent told “you’ve written 500 briefs and know writers need specific data points per section” produces structured, usable output on the first run. The same agent without that backstory produces generic summaries that still need significant editorial work.
Which tools give your CrewAI agents real-time search?
36% of marketers who use AI spend less than one hour writing a long-form article, compared to 38% of non-AI users who spend two to three hours on the same task (Semrush, 2025). The research phase is where AI closes that gap fastest, but only when agents can run live search rather than relying on the LLM’s training cutoff alone.
Three tools cover most content research needs.
SerperDevTool is the standard choice for keyword-driven research. It queries Google and returns structured results: title, URL, snippet, and date. It’s best for finding what’s currently ranking, surfacing statistics from recent reports, and scraping People Also Ask results. At $50/month for the Starter plan (50,000 queries), it costs roughly $0.001 per search call.
ScrapeWebsiteTool fetches the full text of a URL. Use it when your Research Specialist needs to read a source rather than just see its snippet. It’s the tool that turns “found a Gartner press release” into “read the Gartner press release and extracted three specific data points.”
EXASearchTool handles semantic queries rather than keyword queries. Better when you need conceptually similar content: “find articles arguing that AI writing tools hurt SEO” rather than “AI writing tools SEO study.” It’s slower and costs more per call, so use it for analysis tasks where keyword search returns obvious results.

Running the cost math on a 4-agent crew for a single content brief: the Research Specialist makes roughly 10 SerperDev calls ($0.01) and scrapes 3 pages (negligible). The three remaining agents (Analyst, Writer, QA) run on GPT-4o-mini at approximately $0.15 per million input tokens. A full 4-task run averages around 2,500 tokens input and 1,500 tokens output across all agents, for a total model cost around $0.35. Combined with SerperDev calls, the all-in cost per brief is approximately $0.46. A mid-level content researcher billing at $50/hour takes 2.5 hours for the same output: $125. That’s a 270x cost difference per brief.
How do you run your CrewAI content research crew?
33.5% of daily AI users save four or more hours per week, and that figure comes from workers using standard AI chat tools (ITIF / Federal Reserve Bank of St. Louis, May 2025). A properly configured CrewAI content research crew is built specifically for research workflows, chaining research, analysis, brief writing, and QA without a human prompt at each step.
Open src/content_researcher/crew.py and replace the default scaffold:
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task
from crewai_tools import SerperDevTool, ScrapeWebsiteTool
@CrewBase
class ContentResearcherCrew():
"""4-agent content research crew for B2B marketing briefs"""
agents_config = 'config/agents.yaml'
tasks_config = 'config/tasks.yaml'
@agent
def research_specialist(self) -> Agent:
return Agent(
config=self.agents_config['research_specialist'],
tools=[SerperDevTool(), ScrapeWebsiteTool()],
verbose=True
)
@agent
def content_analyst(self) -> Agent:
return Agent(
config=self.agents_config['content_analyst'],
tools=[SerperDevTool()],
verbose=True
)
@agent
def brief_writer(self) -> Agent:
return Agent(
config=self.agents_config['brief_writer'],
verbose=True
)
@agent
def qa_reviewer(self) -> Agent:
return Agent(
config=self.agents_config['qa_reviewer'],
verbose=True
)
@task
def research_task(self) -> Task:
return Task(config=self.tasks_config['research_task'])
@task
def analysis_task(self) -> Task:
return Task(config=self.tasks_config['analysis_task'])
@task
def brief_writing_task(self) -> Task:
return Task(config=self.tasks_config['brief_writing_task'])
@task
def qa_review_task(self) -> Task:
return Task(config=self.tasks_config['qa_review_task'])
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True
)Edit src/content_researcher/main.py to set your topic:
from content_researcher.crew import ContentResearcherCrew
def run():
inputs = {
'topic': 'AI content agents for B2B marketing teams in 2026'
}
ContentResearcherCrew().crew().kickoff(inputs=inputs)
if __name__ == "__main__":
run()Create the output directory and run:
mkdir -p output
crewai runThe terminal shows each agent working in sequence. The Research Specialist makes search calls and scrapes sources, then hands the report to the Content Analyst, who produces a strategy memo. The Brief Writer drafts from there, and the QA Reviewer approves the final output before it writes to output/brief.md.
How do you connect CrewAI output to your marketing stack?
Marketing automation returns $5.44 for every $1 invested over three years (Cropink, 2026). Routing the crew’s output/brief.md into your team’s actual workflow is what turns a terminal output into a compounding editorial asset.
Three practical integration patterns:
The simplest push is Airtable: read the output file and write key fields (headline options, primary keyword, status) to an Airtable base where your editorial calendar lives. The pyairtable library handles this in under 20 lines. Claude and Airtable for content workflows covers the base setup if you’re starting from scratch.
n8n webhook trigger. Configure output_file in your qa_review_task to write the brief, then add an n8n File Trigger node watching the output/ folder. When the file lands, n8n routes it: create a Notion page, notify the Slack editorial channel, and assign it to a writer in your project tool, with no code changes needed after the initial setup.
Cron scheduling. Run the crew on a daily or weekly schedule using a system cron job or a Python schedule library call. A 7 AM research run on Monday’s editorial topics means writers start the week with briefs already in their queue.
For the full picture of how multiple AI systems (research crew, generation layer, distribution automation) work together across 18 months of real agency deployment, how Lunar Strategy built an AI operating system in 18 months shows what the production architecture looks like.
The counter-intuitive case for four agents over two: most tutorials start with a 2-agent crew (Researcher + Writer) because it’s simpler. The problem is that a 2-agent crew still requires 45–60 minutes of human editing per brief to fix source quality, section gaps, and un-cited claims. Adding the Analyst and QA Reviewer reduces human editing time to 10–15 minutes. At any reasonable hourly rate, the extra two agents pay for themselves on the first brief. The saved editing time, not the research time, is where the ROI calculation changes.
What results should you expect from a CrewAI content research agent?
92% of marketers now report using AI tools as part of their marketing work (HubSpot 2025 State of Marketing, via inBeat Agency). The teams pulling ahead aren’t using AI chat for one-off drafts; they’re running structured pipelines where every content brief goes through a research agent before it reaches a writer.
A correctly configured 4-agent crew on GPT-4o-mini produces: a research report with 8–12 cited statistics and source URLs, a competitive gap analysis of the top five ranking articles, a structured H2 outline with one stat assigned per section, and a QA-reviewed meta description. On complex B2B topics with good SerperDev coverage, the brief quality is comparable to what a strong research contractor produces, and it arrives in 12 minutes.
Where human review still matters: source tier verification (the crew will occasionally cite a Tier 4 aggregator site as if it were primary research), brand voice alignment in the headline options, and topical judgment calls where your team’s first-hand experience should override what’s ranking. The crew accelerates research; editorial judgment still decides source tier, brand voice, and topical priorities.
According to Anthropic’s November 2025 productivity research, AI assistance reduces document writing time by 87% and overall task completion time by approximately 80% (Anthropic Research, Nov 2025). A 4-agent content research crew applies that efficiency at the research and brief stage, compressing the highest-time-cost step in the content pipeline before a writer ever opens a document.

If you’re looking to integrate AI into your marketing automation workflows, get in touch with us and we’ll map out where automation adds the most value for your team.
Frequently asked questions
What Python version does CrewAI require?
CrewAI supports Python 3.10 through 3.13. Python 3.11 is the recommended version for production deployments. It’s stable, well-supported by all major ML libraries, and is the version used in CrewAI’s official Docker images. The crewai create scaffold command sets up a virtual environment automatically if you’re on a supported version (CrewAI Documentation, 2026).
How much does it cost to run a CrewAI content research crew?
A 4-agent content research crew using GPT-4o-mini and SerperDev costs approximately $0.46 per brief: roughly $0.35 in model tokens and $0.01 in SerperDev search calls. Monthly costs for a team running 50 briefs per month: under $25. The free SerperDev Developer plan (2,500 queries/month) covers roughly 250 research runs before billing starts (SerperDev Pricing, 2026).
What’s the difference between CrewAI and LangChain?
LangChain is a framework for building individual chains and RAG pipelines. CrewAI is built specifically for multi-agent workflows where distinct agents hold roles, use tools, and hand results to each other in sequence. For content research, CrewAI’s role-based agent model produces more structured, review-ready output than a LangChain chain because each step has a defined responsible agent with a specific backstory and goal (CrewAI Documentation, 2026).
Can CrewAI use Claude or Gemini instead of OpenAI?
Yes. CrewAI supports any LiteLLM-compatible model. To use Claude Sonnet as your LLM, set ANTHROPIC_API_KEY in .env and add llm="claude-sonnet-4-5" to each Agent() constructor in crew.py. Claude’s 200K context window makes it worth the higher token cost for research tasks that require reading long source documents. The Claude API setup guide for marketing teams covers Claude model selection and pricing for this use case.
How do I add memory so CrewAI agents learn across sessions?
Set memory=True in your Crew() constructor to enable short-term memory within a single run. For cross-session memory, CrewAI integrates with a vector store (Chroma or Qdrant) via long_term_memory=True. This lets the Research Specialist remember which sources were high-quality from prior runs and prioritize them in future searches. 98% of B2B marketers consider marketing automation crucial for success (Cropink, 2026). Memory-enabled crews are the step from automation to genuine institutional knowledge.
Conclusion
A CrewAI content research crew compresses 2.5 hours of manual brief work into 12 minutes. The setup is 30 minutes: install via pip, configure four agents in YAML with specific roles and backstories, add SerperDev for live search, run crewai run. Use GPT-4o-mini for cost efficiency; swap to Claude Sonnet when long source documents require a larger context window.
Key actions this week:
- Install CrewAI and scaffold your first project with
crewai create crew content-researcher - Add the four-agent YAML configs above and run one topic brief before customizing anything
- Time the output vs. your current manual research process and record the delta
- Route
output/brief.mdto Airtable or Notion before scaling to weekly scheduled runs
For agencies managing CrewAI workflows across a full client book, how Lunar Strategy built an AI operating system in 18 months covers how AI tools layer across departments and client accounts at scale.

