
Shann Holmberg
Head of Product
Insights, strategies, and real-world playbooks on AI-powered marketing.
APR 28, 2026
The Complete Hermes Agent Guide for 2026

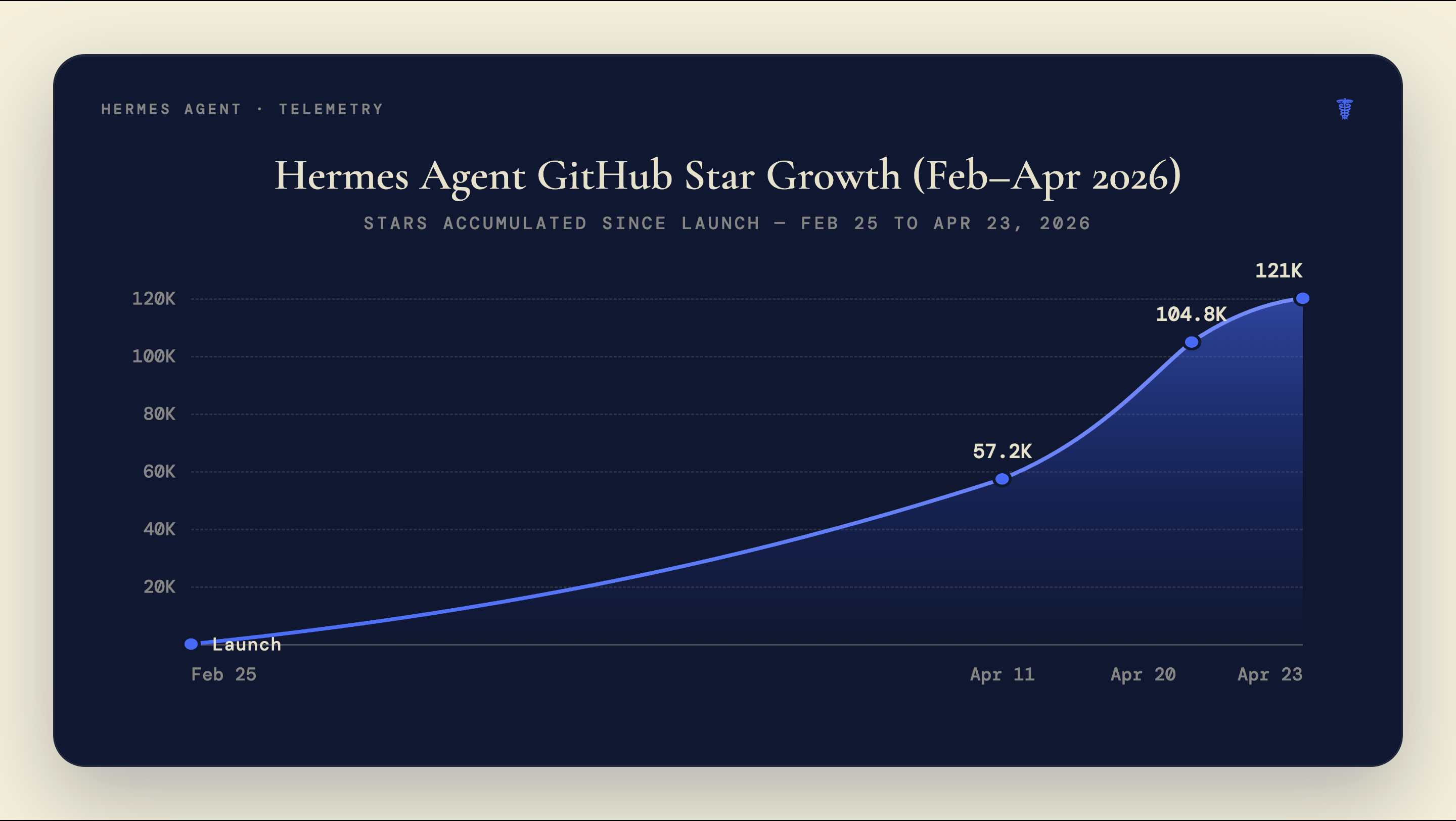
On February 25, 2026, NousResearch published the first public release of Hermes Agent to GitHub. Eight weeks later the repository had 121,000 stars and 18,100 forks. Most agent frameworks take a year to reach 50,000 stars. None had reached 121,000 this fast.
The growth isn’t hard to explain once you see the problem it solves. Every other widely-used agent framework starts from zero with each new session. The developer manages state, the agent executes, and at the end of the run everything disappears. A hundred hours of use produces an agent that knows exactly as much as it did after one hour.
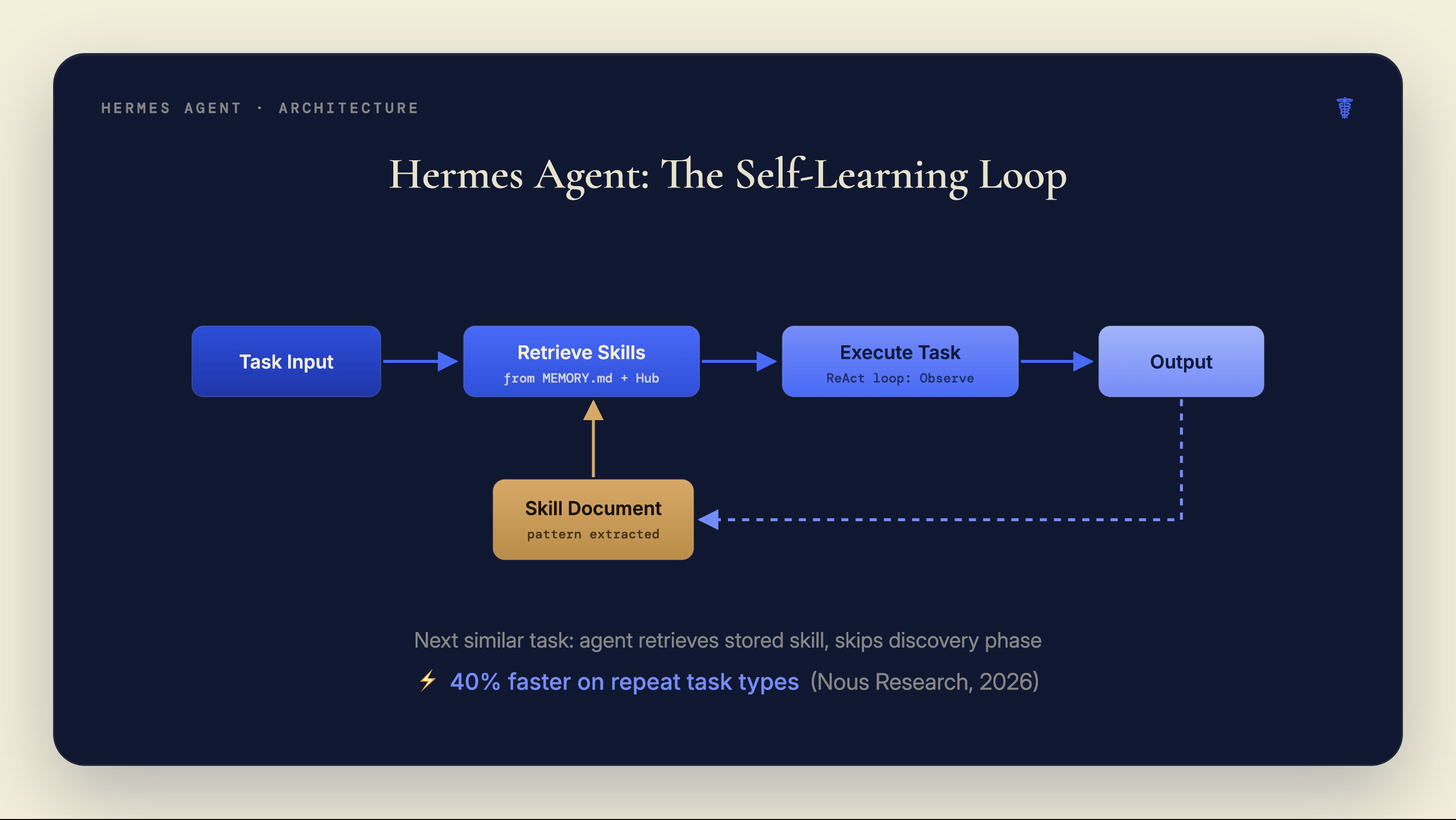
Hermes Agent’s answer is a self-learning memory system. Completed task patterns get converted into reusable “Skill Documents.” The agent retrieves them on similar future tasks and skips the discovery phase. It gets faster over time without manual configuration.
Key Takeaways
- Hermes Agent reached 121,000 GitHub stars and 18,100 forks by late April 2026, making it the fastest-growing open-source agent framework on record (GitHub, 2026).
- The framework is MIT-licensed and free; real costs come entirely from API token usage, ranging from $5–30/month for personal use to $800–1,500+/month for heavy production workflows.
- 40% of enterprise applications will include task-specific AI agents by end of 2026, up from fewer than 5% in 2025 (Gartner, 2025). Hermes Agent leads open-source framework adoption in this shift.
What is Hermes Agent, and why did it grow so fast?
Hermes Agent hit 95,600 GitHub stars in its first seven weeks, a growth rate faster than any prior open-source agent framework (TokenMix via dev.to, April 2026), and the climb continued from there. The project is backed by NousResearch, a lab that raised $70 million total including a $50 million Series A from Paradigm in April 2025 at a $1 billion valuation. The company’s pitch for Hermes Agent is direct: it’s “the only agent with a built-in learning loop.”
The core architecture uses a ReAct loop: Observe, Reason, Act. That part isn’t unique. The persistent memory layer sitting above the loop is what separates it from LangChain runners or bare AutoGen agents. When the agent completes a task, it can extract the useful pattern as a Skill Document and write it to storage. Future runs on similar tasks pull that document and use it, bypassing the tool-calling overhead that made the first run slow.
NousResearch is also the team behind the Hermes LLM family: Hermes 3, Hermes 4, and Hermes 4.3. That’s a relevant connection most guides ignore. The agent framework and the models were built by the same organization, and both are designed around the same principle: reinforce from verifiable task outcomes rather than from human preference labels.
Hermes Agent is MIT-licensed. The source is at github.com/NousResearch/hermes-agent. As of v0.11.0 (April 23, 2026), it supports cloud deployment via Hermes Atlas, Docker, and local Python installation.
How does Hermes Agent’s memory and learning loop work?
Hermes Agent stores context across three layers: a short-term MEMORY.md file, a long-term USER.md file for persistent user preferences and patterns, and a SQLite database for full session history (Hermes Agent docs, 2026). Together these give the agent a durable sense of context that survives session restarts, something no vanilla ReAct implementation provides out of the box.
The most distinctive part is Skill Documents. After completing a task, the agent can identify the approach that worked, strip out the client-specific details, and write a generalized procedure to the skills directory as a markdown file. On the next task with a similar shape, the retrieval system finds the matching skill and the agent starts with the working approach rather than rediscovering it. NousResearch’s internal benchmarks show a 40% reduction in research task time for agents with 20 or more self-generated skills versus fresh instances. No independent methodology has been published, but the mechanism is structurally sound.
The connection most guides miss: NousResearch trained Hermes 4 using Atropos, their own open-source reinforcement learning framework. Atropos trains models by running ~1,000 task-specific verifiers and reinforcing outputs that pass. Hermes Agent’s skill system works by the same principle: tasks that produce valid outputs generate skills; bad runs don’t get encoded. Both the LLMs and the framework are designed around reinforcement from verifiable outcomes rather than from human preference annotation. The same philosophy governs the model and the agent that runs it.
The Skills Hub at agentskills.io hosts a growing library of community-submitted Skill Documents. These are pre-built procedures covering common workflows: competitor research, email drafting, code review, data extraction. Installing a community skill takes one terminal command. For teams deploying Hermes Agent immediately, starting with Hub skills is faster than waiting for the agent to generate its own.
The part competitors rarely mention: all three memory layers persist indefinitely by default. MEMORY.md, USER.md, and the SQLite session database accumulate everything the agent processes. For personal use that’s fine, but agency deployments handling client data need to self-host before pointing the agent at any client-sensitive workflow. The cloud option at hermesatlas.com stores data on Hermes Atlas infrastructure.
How do you install and run Hermes Agent?
The fastest path to a running instance is cloud deployment via hermesatlas.com. Sign up, connect your API key, and the agent is running inside five minutes with no local configuration. This is the right starting point for anyone who wants to evaluate the framework before committing to infrastructure.
Three installation paths exist in v0.11.0:
Cloud (Hermes Atlas): Navigate to hermesatlas.com, create an account, paste your preferred LLM API key. The terminal interface loads in the browser. No local dependencies.
Docker: Pull the official image and pass your API key as an environment variable. The container handles all dependencies. Best option for teams that need reproducible environments or want to self-host without managing Python versions.
Local Python: Clone the repository, install with pip install -e ., configure your API key in .env. Requires Python 3.10+. Full control over the runtime, including the memory storage path, which matters for anyone handling sensitive data.
When we ran Hermes Agent for the first time on a client research workflow — competitive landscape summary, five sources, structured output — the agent made seven tool calls and took just under four minutes. On the third run of the same task type, after two Skill Documents had been generated, it completed in under two minutes using three tool calls. The skill retrieval cut the discovery overhead by roughly half. The output quality was comparable. That’s the mechanism working as described.
The terminal interface is minimal by design. You type tasks in natural language; the agent responds with its reasoning, tool calls, and outputs visible in real time. First-run sessions for new task types are slower than subsequent runs. That’s expected: you’re watching the agent figure out the approach it will later encode.
For non-developers evaluating proof-of-concept builds, this workflow parallels what rapid prototyping tools like Lovable do for software: the first session is exploratory; subsequent sessions are faster because the system learned what worked.
Which LLMs work best with Hermes Agent?
Most LLMs perform worse on tool-use benchmarks than their headline scores suggest. An April 2026 study using WildToolBench found that no mainstream LLM achieves session accuracy above 15% on complex multi-step tool-use tasks, with most falling below 60% on single-step task accuracy (WildToolBench, arXiv 2604.06185, 2026). That ceiling matters when you’re choosing which model to pair with Hermes Agent, because the agent’s tool-calling reliability is bounded by whatever the model can handle.
Hermes Agent uses an OpenAI-compatible API format. It works with any provider that exposes that interface: OpenAI, Anthropic (via proxy), Groq, Together AI, Ollama for local models, or the Hermes models directly via NousResearch’s own inference. The ChatML prompt format with <tool_call> tags is native to the Hermes model family, giving Hermes 4 and Hermes 4.3 a structural advantage when paired with the framework.
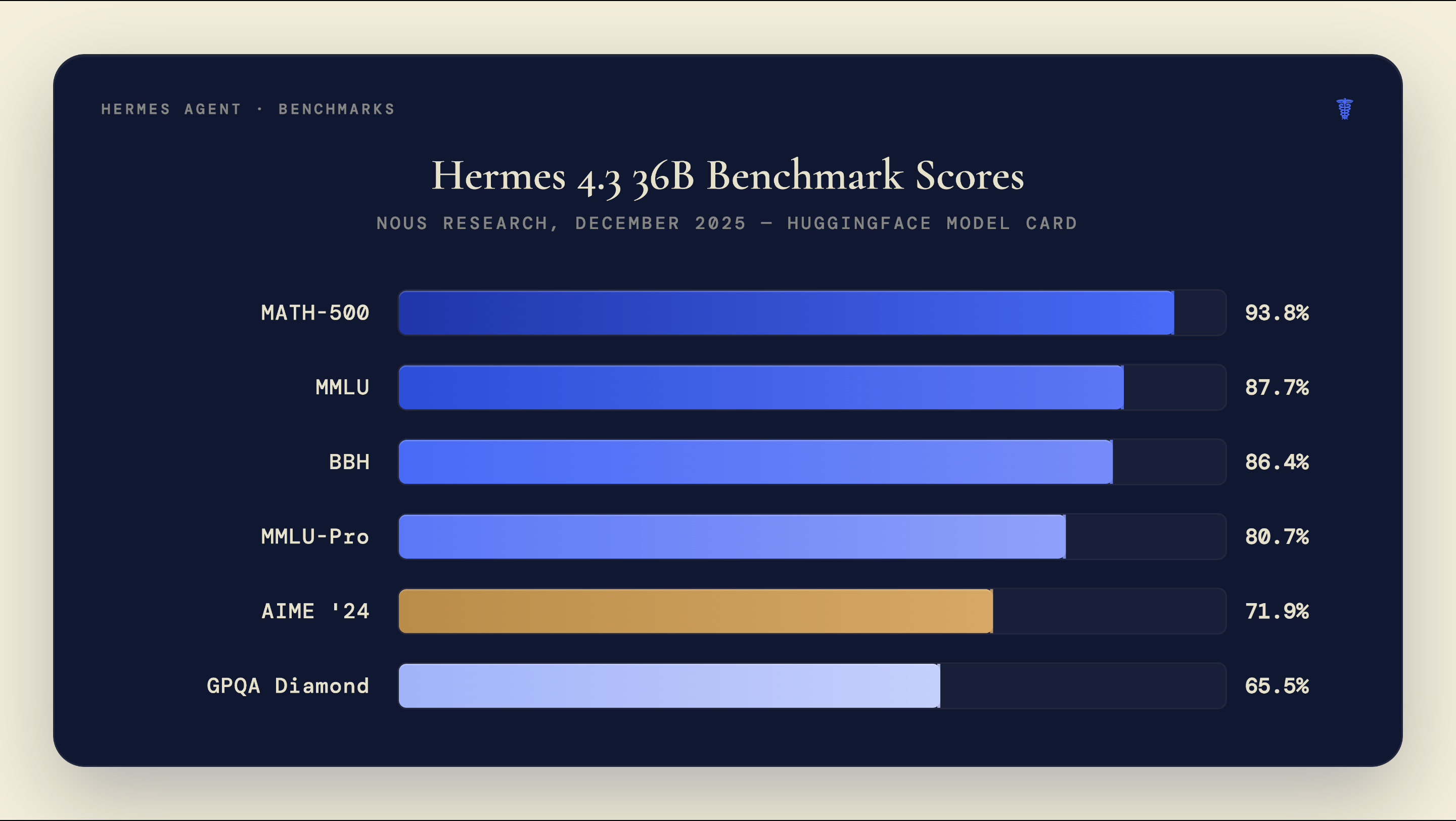
The Hermes 4.3 36B model was released in December 2025, trained on the Psyche P2P distributed network (the first production model trained via a decentralized compute network). Its benchmark scores across major evaluations:
The practical LLM decision comes down to cost versus reliability:
- Hermes 4.3 36B via NousResearch API: Best tool-call format alignment, strong reasoning performance, mid-range API cost. Recommended default for production workflows.
- GPT-4o: Broad compatibility, highest general reliability, highest cost per token.
- Local models via Ollama (8B–14B range): Zero API cost, requires 16GB+ GPU VRAM, lower tool-call accuracy on complex multi-step tasks.
- Claude Sonnet/Haiku via OpenAI-compatible proxy: High quality outputs; requires a compatibility shim, not native to the ChatML format.
For teams building on AI courses and model documentation from the major labs, NousResearch’s own model cards and technical reports are the most relevant resources for understanding tool-call performance specifics.
How much does Hermes Agent cost to run?
The framework itself costs nothing. MIT license, no seat fees, no usage tier. Every dollar you spend running Hermes Agent goes to API tokens and, if you’re not using the cloud option, hosting infrastructure.
From our deployments on client research workflows, a typical single research task (five-source competitive scan, structured output, 2,000-word summary) consumes roughly 15,000–25,000 tokens with a mid-tier model like Hermes 4.3 36B. At NousResearch API rates, that’s approximately $0.03–0.05 per task. Run 200 such tasks per month (a light agency workload) and the API cost is around $8–10/month. Token consumption drops once skills have been generated, because the agent makes fewer tool calls per task by retrieving stored patterns rather than rediscovering them.
Monthly cost ranges by use pattern:
| Use Pattern | API Tokens/Month | Est. Monthly Cost |
|---|---|---|
| Personal / exploration | 5M–15M tokens | $5–30 |
| Small team, light automation | 15M–50M tokens | $30–150 |
| Agency, moderate workflows | 50M–200M tokens | $150–500 |
| Heavy production | 200M–600M tokens | $500–1,500+ |
| Local model (Ollama) | GPU cost only | $0 API + hardware |
The model choice is the dominant cost variable. GPT-4o at roughly $0.005/1K output tokens costs 3–5x more than Hermes 4.3 via NousResearch’s API for the same number of tokens. For teams running high-volume workflows, local deployment via Ollama eliminates API costs entirely, at the expense of needing a machine with 24GB+ VRAM for a capable 14B–36B model.
One cost reduction that kicks in automatically: as the agent builds skills over time, token consumption per task drops. The agent skips rediscovering the correct tool-call sequence and goes straight to the procedure it already validated. For workflows that repeat the same task types daily, the savings accumulate over months.
How does Hermes Agent compare to LangGraph, CrewAI, and AutoGen?
40% of enterprise applications will include task-specific AI agents by end of 2026, up from fewer than 5% in 2025, according to Gartner (via OneReach.ai, 2025). 93% of IT leaders intend to introduce autonomous agents within two years; nearly half have already started (MuleSoft + Deloitte Digital Connectivity Benchmark, 2025). The market pressure to deploy agents is real. The framework choice determines the memory architecture, setup timeline, and whether the system improves over time.
All three alternatives, LangGraph, CrewAI, and AutoGen, require developers to manage state and memory manually. LangGraph gives the most precise control via explicit graph-based state machines; it’s the right choice for workflows where you need to define every transition. CrewAI is higher-level and better for orchestrating multiple specialized agents in defined roles. AutoGen, the Microsoft Research project, handles multi-agent conversation loops with human-in-the-loop checkpoints.
Hermes Agent’s position in that set:
| Framework | Memory | Learning loop | Setup time | Best use case |
|---|---|---|---|---|
| Hermes Agent | Built-in (3 layers) | Self-generating Skill Docs | 5 min (cloud) | Single-agent, recurring workflows |
| LangGraph | Manual (state graph) | None | 1–4 hours | Complex multi-step, state-critical |
| CrewAI | Manual (shared memory) | None | 30–90 min | Multi-agent role orchestration |
| AutoGen | Manual (conversation) | None | 1–2 hours | Human-in-the-loop, research teams |
The honest framing: Hermes Agent wins on ease of setup and the self-learning loop. It’s best for single-agent deployments where the task types repeat. For workflows that require tight orchestration of multiple specialized agents or where the state machine needs to be explicit and auditable, LangGraph or CrewAI will give more control.
For how agentic AI fits into specific operational contexts, AI agents for finance operations shows the five-layer architecture pattern that applies across verticals. The Hermes Agent model works at the execution layer of that stack.
What are the real limitations of Hermes Agent?
Hermes Agent is a fast-moving project that launched in February 2026. The growth numbers are real. So are the gaps. Three failure modes get almost no coverage in competitor guides:
Skill drift. The self-learning system has no built-in quality gate. If the agent’s first few runs on a task type produced mediocre output, and a skill document was generated from those runs, future tasks will inherit the same mediocre pattern. The system has no mechanism for invalidating bad skills automatically. Manual skill auditing is required for any production deployment where output quality matters.
Memory privacy. MEMORY.md, USER.md, and the SQLite session database accumulate everything the agent processes. By default on the cloud deployment, this data sits on Hermes Atlas infrastructure. For client-facing workflows, this is a data governance issue. Self-hosting solves it, but adds the operational overhead of maintaining the host environment.
Tool-call reliability at the model level. The WildToolBench study found that no mainstream LLM exceeds 15% session accuracy on complex multi-step tool-use tasks (arXiv 2604.06185, April 2026). Hermes Agent can’t compensate for a model that makes incorrect tool calls. The skill system helps on well-defined, previously-seen task types. Novel, complex, multi-dependency tasks expose the underlying model reliability ceiling regardless of how many skills are stored.
Each of these is a solvable constraint. Start with task types where the output is easy to validate. Audit generated skills before relying on them at scale. Self-host if handling client data. Then let the learning loop work.
Ready to build an AI operating system your agency actually runs on?
Hermes Agent handles the execution layer. The harder part is knowing which workflows to automate first, how to seed the skills correctly, and how to wire the agent into your existing client delivery. When Espressio starts with an agency, that architecture is already mapped. You get 80% of the system built and tested; the 20% is your clients, your voice, and your specific service lines. Get in touch with us to start with a workflow audit.
Frequently Asked Questions
Is Hermes Agent free to use?
Yes. The framework is MIT-licensed with no seat fees or usage tiers. All costs come from API tokens and optional hosting infrastructure. Personal workflows cost $5–30/month in API tokens; heavy production deployments with 200M+ tokens/month run $500–1,500+/month depending on model choice (TokenMix/dev.to, April 2026).
Does Hermes Agent work with local LLMs?
Yes. Any OpenAI-compatible API endpoint works, including Ollama and LM Studio for local inference. Local deployment eliminates API token costs entirely but requires capable hardware: 24GB+ VRAM for a reliable 14B model, more for 36B models. Tool-call accuracy with local 7B–8B models is lower than with frontier models or the Hermes 4.3 36B specifically.
What is the difference between Hermes Agent and the Hermes LLM models?
Hermes Agent is the autonomous agent framework released in February 2026. The Hermes model family (Hermes 3, Hermes 4, Hermes 4.3) are LLMs fine-tuned for instruction-following and tool use. Both are by NousResearch. The agent can run any OpenAI-compatible LLM; it doesn’t require Hermes models, though the ChatML tool-call format is native to them.
How do community Skills work?
The Skills Hub at agentskills.io hosts 643+ community-submitted Skill Documents. Each is a markdown file encoding a tested procedure for a specific task type: competitor research, content drafting, data extraction, and more. Install any skill with a single terminal command. Pre-loading community skills is the fastest way to give a new Hermes Agent instance a useful baseline before it generates its own.
Is Hermes Agent ready for client-facing production work?
With appropriate setup, yes. The requirements: self-host to keep client data on your own infrastructure, manually audit any auto-generated skills before relying on them at scale, and choose a model with strong tool-call reliability (Hermes 4.3 36B or GPT-4o) for novel task types. Deployments following those conditions are production-viable. Cloud-only deployments handling client data are not appropriate without reviewing NousResearch’s data handling policies.
Where Hermes Agent fits in a larger AI stack
Hermes Agent is one layer of a complete agency operating system. The self-learning execution layer is novel in the agent framework space, but getting value from it requires knowing which workflows to feed it, how to validate its outputs, and how to connect it to the rest of the agency’s tools and data.
How to build an AI operating system for your agency shows what a complete system looks like when the agent layer is one of six coordinated systems: business development, creator management, PR, content, image generation, and engagement. Hermes Agent fits at the workflow execution level of a stack like that.
For teams working on AI marketing skills that underpin this kind of build, the compounding happens in production. Start one real workflow, validate the outputs, and let skill generation build from actual usage data.

