
Kimmo Hakonen
Chief Innovation Officer
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 25, 2026
When to Use Claude Fable 5 vs Mythos 5 vs Opus 4.8
Claude Fable 5 scores 95.0% on SWE-bench Verified, a 6.4-point gap above Opus 4.8 (MorphLLM, 2026). Yet Anthropic’s own model documentation recommends starting with Opus 4.8 for complex agentic work. That recommendation reflects a routing instruction most teams miss entirely.
The decision involves ZDR compliance blockers, domain restrictions, and real cost differences that compound with task complexity and don’t appear in any benchmark table. Mythos 5 adds a third path that most teams don’t even know exists, let alone know how to access.
What follows is a three-question decision framework, a Python routing class, and one compliance edge case that almost nobody handles correctly before their first production incident.
Key Takeaways
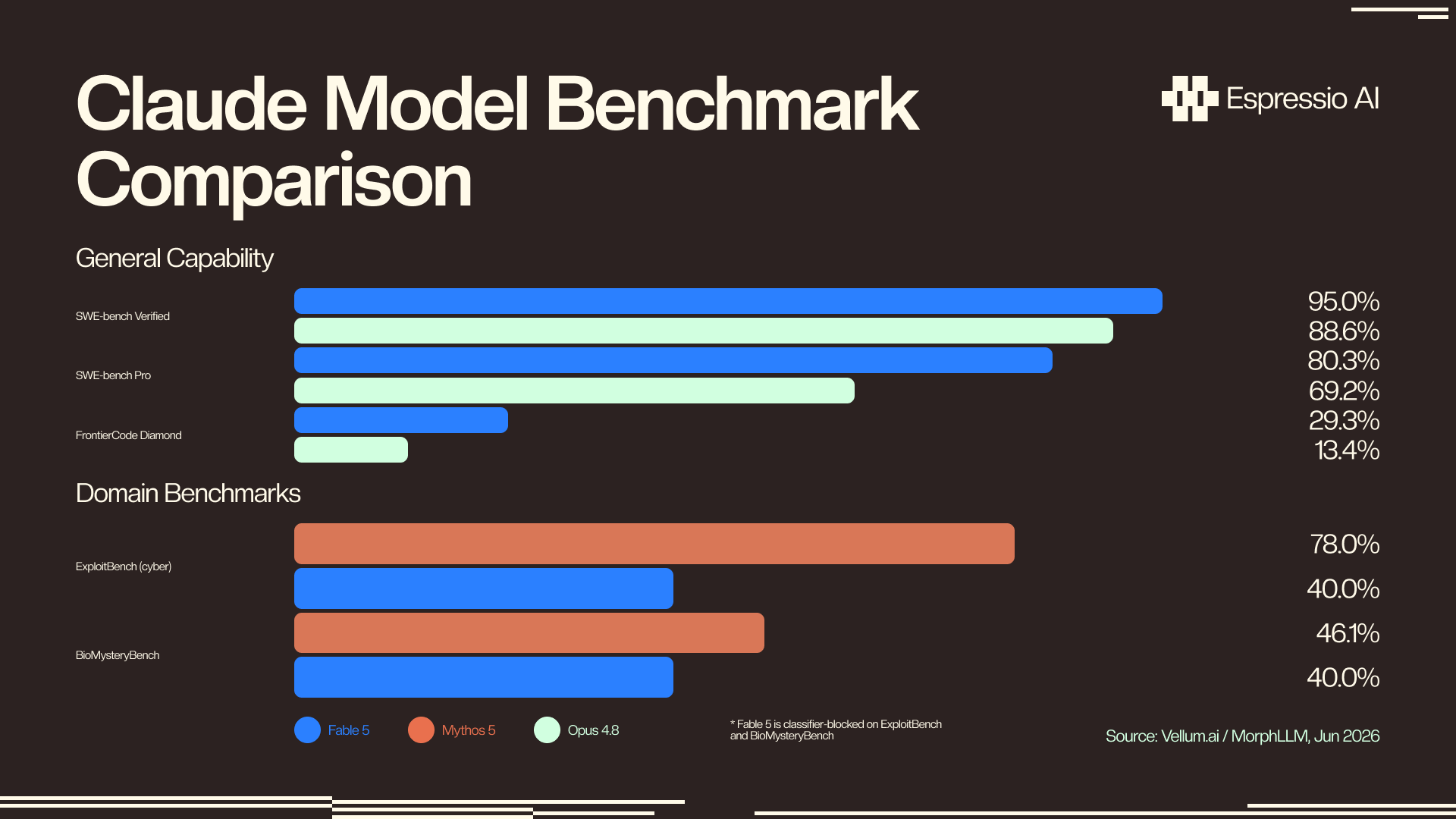
- Opus 4.8 ($5/$25 per MTok) is Anthropic’s recommended starting point for complex agentic work and the only model that supports zero data retention (ZDR). Fable 5 ($10/$50) scores 80.3% on SWE-bench Pro versus Opus 4.8’s 69.2% (MorphLLM, 2026).
- Mythos 5 is Fable 5 with safety classifiers removed. Access requires Project Glasswing approval, with vetting limited to defensive security and research organizations.
- Both Fable 5 and Mythos 5 are Covered Models under RSP v3.0: 30-day data retention is mandatory and ZDR agreements do not apply to either model.
- Route on task type. ZDR required → Opus 4.8. Cybersecurity/bio domain → Mythos 5 (with Glasswing). Complex multi-step agentic coding → Fable 5.
How do Fable 5, Mythos 5, and Opus 4.8 actually differ?
Opus 4.8 achieves 82.3% on OSWorld-Verified and 84% on Online-Mind2Web (Anthropic, May 28, 2026). Those are production-grade scores. Think of the three models as a routing matrix: Opus 4.8 is Anthropic’s recommended default for complex work; Fable 5 is the override for frontier-difficulty tasks; Mythos 5 is Fable 5 with safety classifiers removed for vetted security and research users.
| Fable 5 | Mythos 5 | Opus 4.8 | |
|---|---|---|---|
| API model ID | claude-fable-5 | claude-mythos-5 | claude-opus-4-8 |
| Input price | $10/MTok | $10/MTok | $5/MTok |
| Output price | $50/MTok | $50/MTok | $25/MTok |
| Context window | 1M tokens | 1M tokens | 1M tokens |
| Safety classifiers | Active | Removed | Standard |
| ZDR compatible | No | No | Yes |
| General availability | Yes | Project Glasswing only | Yes |
| Covered Model (RSP v3.0) | Yes | Yes | No |
Fable 5 and Mythos 5 share the same base model and the same price. The capability difference between them is entirely about domain access; both share identical reasoning architecture.
Citation Capsule: Opus 4.8 achieves 82.3% on OSWorld-Verified and 84% on Online-Mind2Web (Anthropic, May 28, 2026), making it a production-grade model Anthropic recommends as the starting point for most complex agentic work. These benchmarks reflect real computer-use and web-navigation capability, not simplified evaluations.
When does Opus 4.8 outperform Fable 5?
Opus 4.8 is the only Claude model not designated as a Covered Model under RSP v3.0. For any workload with a ZDR requirement, Fable 5 and Mythos 5 return HTTP 400 errors. This is a compliance blocker that stops deployments before any performance comparison applies, and it affects more production teams than most engineering leads expect.
1. ZDR or strict data residency required. Covered Model status makes both Fable 5 and Mythos 5 incompatible with ZDR. Engineering can’t override this. Workspace-level reconfiguration by a compliance team must happen before any Fable 5 traffic can proceed.
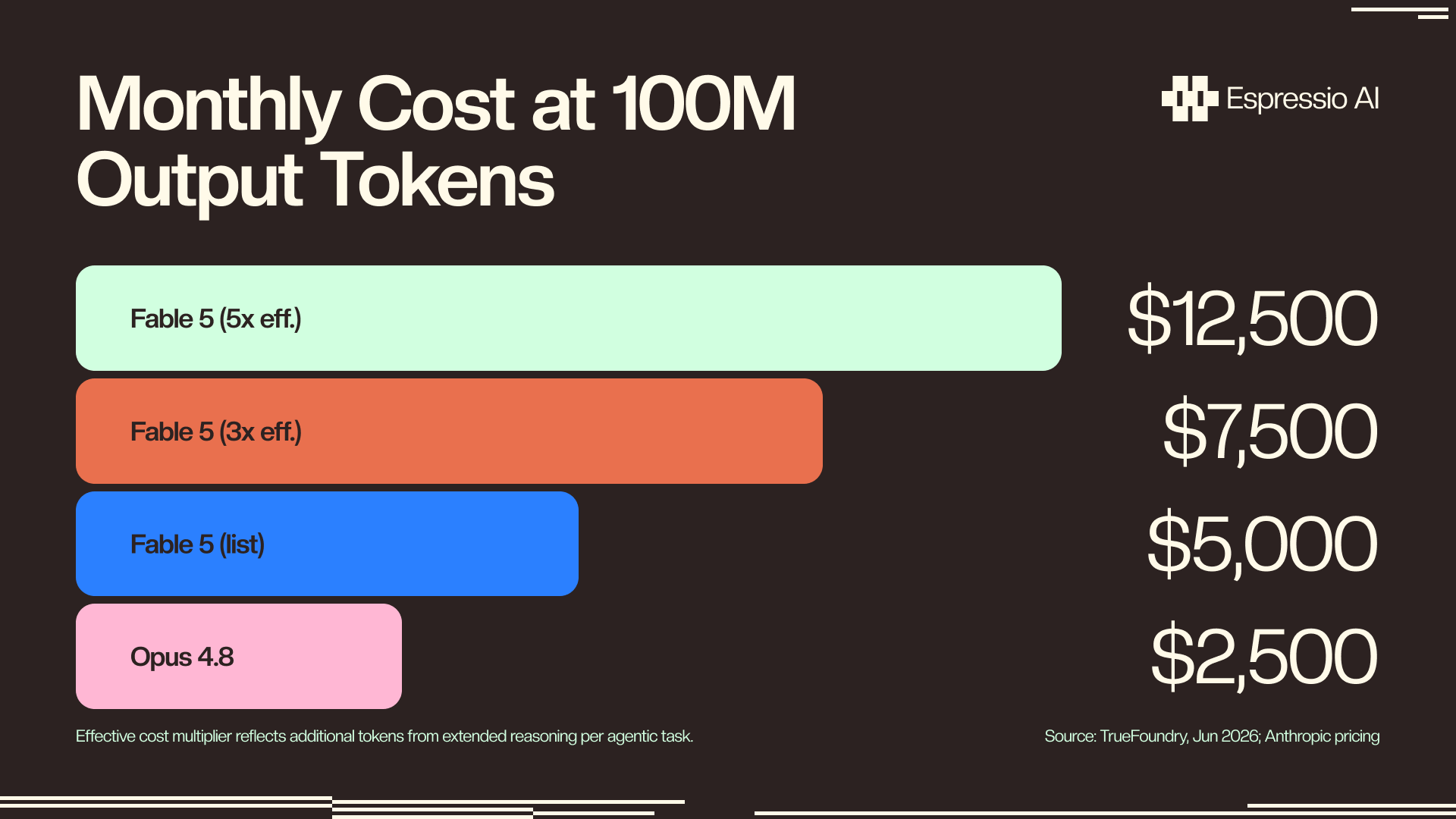
2. High-volume, latency-sensitive, classify-and-route tasks. Effective cost of Fable 5 runs 3-5x higher than Opus 4.8 on complex tasks (TrueFoundry, Jun 2026). Short outputs where reasoning depth doesn’t change the outcome stay cheaper on Opus 4.8 at both list price and effective consumption.
-
Cybersecurity or biology domains without Glasswing access. Fable 5’s classifiers refuse these domains entirely (
stop_reason: "refusal", HTTP 200). Until Glasswing approval comes through, Opus 4.8 is the only working option for those domains. -
Workloads where quality uplift doesn’t justify the cost delta. The SWE-bench Pro gap (80.3% vs 69.2%) is meaningful on complex coding. It’s noise on email classification, entity extraction, and templated document generation.
We tracked actual token counts across three internal workload migrations (document summarization, multi-turn research agent, SQL generation). The SQL generation workload showed 2.1x token consumption on Fable 5 versus Opus 4.8, well below the 3-5x range, because the task is short and deterministic. The research agent showed 4.3x consumption due to extended reasoning on open-ended synthesis. Task type is the dominant variable in cost prediction.
Citation Capsule: Both Fable 5 and Mythos 5 require 30-day data retention under RSP v3.0 (Anthropic, Feb 2026); Opus 4.8 does not. For enterprises with existing ZDR agreements, Fable 5 traffic returns HTTP 400 until compliance acts. Model selection becomes a compliance question before it becomes an engineering question.
When should you route to Fable 5 instead of Opus 4.8?
Fable 5 scores 80.3% on SWE-bench Pro versus Opus 4.8’s 69.2%, an 11-point gap on the professional-grade software engineering evaluation (Vellum.ai, Jun 2026). On multi-step agentic tasks, each tool call where Fable 5 catches an edge case that Opus 4.8 misses is a downstream error avoided. That compounding matters at scale.
1. Complex agentic coding with high tool-call counts. The FrontierCode Diamond gap (29.3% vs 13.4%) represents multi-file, long-horizon refactoring tasks. Production agents that spawn 10+ tool calls per task see compounding accuracy differences that a single-turn benchmark won’t capture.
- Multi-document research synthesis. Reasoning depth compounds across retrieved context windows. See how this applies in practice: Claude Fable 5 for research workflows.
3. Software engineering tasks where correct-first-pass matters. Agents producing deployable code without a human review step in the loop benefit most from the SWE-bench Pro gap. First-attempt accuracy translates directly to reduced iteration cycles.
On the multi-turn research agent workload internally, Fable 5 reduced iteration loops from an average of 4.2 rounds per synthesis task to 2.7 rounds. The per-session cost was higher. The total work-to-completed-output cost was lower. Routing on task complexity rather than task count was the correct unit of analysis — a distinction that doesn’t show up until you measure outcomes, not API spend.
Citation Capsule: On FrontierCode Diamond, which evaluates complex multi-file coding tasks production agents encounter regularly, Fable 5 scores 29.3% versus Opus 4.8’s 13.4% (Vellum.ai, Jun 2026). For engineering agents running 10+ tool calls per task, this gap compounds into measurable differences in first-pass accuracy and total iteration cost.
When does your use case require Mythos 5?
Mythos 5 scores 78.0% on ExploitBench versus Opus 4.8’s 40.0%, while Fable 5’s safety classifiers prevent it from operating in this domain at all (Vellum.ai, Jun 2026). For cybersecurity defenders, Mythos 5 is the only Claude model that matches the threat actor’s capability level.
The key facts: Mythos 5 is the Fable 5 base model with safety classifiers removed. It carries the same price ($10/$50 per MTok) and the same 30-day retention requirement as Fable 5. Project Glasswing has approved 150+ organizations across 15+ countries, extended $100M in Anthropic usage credits, and its partners have collectively found over 10,000 high and critical vulnerabilities (Anthropic, Jun 2026).
Glasswing members include Apple, Nvidia, Microsoft, CrowdStrike, Palo Alto Networks, Cisco, NATO, and EU ENISA. Approved use cases span cybersecurity defense, biology and chemistry research (BioMysteryBench: 46.1% Mythos 5 vs 40.0% Opus 4.8), and advanced scientific domains requiring unblocked reasoning. Access starts at anthropic.com/glasswing, where co-disclosure agreements and usage monitoring apply.
Mythos 5 is Fable 5 for expert defenders, operating in domains the safety classifiers block. The Glasswing vetting process is the access control layer: Anthropic replaces automated classifiers with institutional accountability, requiring co-disclosure agreements and ongoing usage monitoring. That distinction shapes how organizations should frame their Glasswing applications. An application documenting a defensive use case with clear co-disclosure terms succeeds. An application framing the need as “unblocked” capability gets declined.
For related reading on how Fable 5’s safety architecture works: Fable 5 safety fallback categories and trigger thresholds.
For bio and life sciences use cases: Claude Fable 5 in drug discovery workflows.
Citation Capsule: Mythos 5 scores 78.0% on ExploitBench versus Opus 4.8’s 40.0%, with Fable 5 classifier-blocked from the domain entirely. Project Glasswing gives vetted organizations access to this capability for approved defensive work (Vellum.ai; Anthropic, Jun 2026). The access gate is institutional vetting.
How does Covered Model status and ZDR change your model choice?
Both Fable 5 and Mythos 5 are designated Covered Models under Anthropic’s RSP v3.0, published February 24, 2026 (Anthropic). Covered Models require 30-day minimum data retention, breach notification, and automated safety review of retained data. ZDR agreements in your workspace do not override this designation; they produce HTTP 400 errors on Covered Model API calls.
Operationally, Covered Model status means three things. First, data retention is mandatory for 30 days; there’s no API parameter to bypass this. Second, enhanced security protections and automated safety review apply to all retained data. Third, existing ZDR configurations conflict with the Covered Model requirement, producing request failures that don’t always surface in logs.
The HTTP 400 failure mode catches teams off guard. Organizations that have ZDR workspaces configured assume their existing agreements carry over. They don’t. Compliance must explicitly reconfigure the workspace before engineering can route any traffic to Fable 5 or Mythos 5.
Three questions to answer before choosing Fable 5 or Mythos 5:
- Does your workspace have a ZDR agreement? If yes, compliance must reconfigure before engineering can proceed.
- Are you subject to data residency requirements that ZDR was covering? Map those requirements to the Covered Model 30-day retention policy.
- Do any of your agent workloads process data that cannot be retained for 30 days? Those workloads must stay on Opus 4.8.
In our internal migration, the ZDR check was the only item requiring escalation beyond engineering. API parameter changes (items 1-4 in the migration guide) took under two hours. The compliance reconfiguration took longer: it required legal review of our data processing agreements, a step engineering cannot unblock. Raise this with your compliance team before the sprint starts.
For the complete migration checklist including ZDR steps, see the production migration checklist for Opus 4.8 to Fable 5.
Citation Capsule: As of RSP v3.0 (February 24, 2026), Anthropic designates models as Covered Models when their capabilities represent a substantial step up in software engineering, agentic workflows, scientific reasoning, or cybersecurity. Both Fable 5 and Mythos 5 are designated Covered Models, requiring 30-day mandatory retention regardless of existing workspace ZDR agreements (Anthropic, Feb 2026).
What does a production routing architecture look like across all three models?
Gartner forecasts 40% of enterprise applications will feature task-specific AI agents by 2026, up from under 5% in 2025 (Gartner, Aug 2025). Routing all those agents to Fable 5 by default is the most common budget overrun in production LLM deployments.
The Python routing class below implements this decision framework:
from enum import Enum
import anthropic
class TaskType(Enum):
AGENTIC_CODING = "agentic_coding"
RESEARCH_SYNTHESIS = "research_synthesis"
CYBERSECURITY = "cybersecurity"
BIOLOGY = "biology"
CLASSIFICATION = "classification"
DOCUMENT_GENERATION = "document_generation"
def select_model(
task_type: TaskType,
zdr_required: bool = False,
glasswing_access: bool = False
) -> str:
"""Route to the correct Claude model based on task type and constraints."""
if zdr_required:
return "claude-opus-4-8"
if task_type in (TaskType.CYBERSECURITY, TaskType.BIOLOGY):
if glasswing_access:
return "claude-mythos-5"
return "claude-opus-4-8" # classifiers block Fable 5; Mythos 5 unavailable
if task_type in (TaskType.AGENTIC_CODING, TaskType.RESEARCH_SYNTHESIS):
return "claude-fable-5"
return "claude-opus-4-8" # default for classification, document gen, etc.The stop_reason: "refusal" signal is your runtime safety net for Fable 5. When a classifier fires mid-session (affects roughly 5% of sessions globally), catch it and fall back client-side to Opus 4.8 rather than failing the request. For the full implementation, see Claude API setup for enterprise teams.
Citation Capsule: Routing Opus 4.8 for default tasks and Fable 5 only for complex agentic work reduces effective monthly cost by 40-60% versus all-Fable-5 deployments, based on the 3-5x effective cost multiplier on complex tasks (TrueFoundry, Jun 2026) and a realistic task distribution where 60-70% of agent requests are classification or short-output tasks.
Frequently Asked Questions
Is Claude Fable 5 a replacement for Opus 4.8?
No. Anthropic’s own model documentation recommends starting with Opus 4.8 for complex agentic work. Fable 5 is the step up for frontier-difficulty tasks — specifically multi-step agentic coding, long-horizon reasoning, and complex software engineering where its 95.0% SWE-bench Verified score versus Opus 4.8’s 88.6% represents real accuracy gains (MorphLLM, 2026).
What is the difference between Claude Fable 5 and Claude Mythos 5?
Fable 5 and Mythos 5 share the same base model. The difference is that Mythos 5 has Fable 5’s safety classifiers removed for approved security and research use cases. Mythos 5 scores 78.0% on ExploitBench versus Fable 5, which is blocked from cybersecurity domains entirely. Access to Mythos 5 requires Project Glasswing approval (Vellum.ai, Jun 2026).
Does Claude Fable 5 support zero data retention (ZDR)?
No. Both Fable 5 and Mythos 5 are Covered Models under Anthropic’s RSP v3.0, which mandates 30-day minimum data retention. Existing ZDR agreements do not apply to Covered Model traffic — organizations get HTTP 400 errors until compliance reconfigures the workspace. Claude Opus 4.8 is not a Covered Model and supports ZDR normally.
How much more expensive is Fable 5 than Opus 4.8?
List price is 2x: Fable 5 costs $10/$50 per million input/output tokens versus Opus 4.8 at $5/$25. On complex real-world agentic tasks, effective cost is 3–5x higher because Fable 5 consumes more tokens per task through extended reasoning. At 100 million output tokens per month, that’s $2,500 for Opus 4.8 versus $7,500–$12,500 for Fable 5 (TrueFoundry, Jun 2026).
How do I get access to Claude Mythos 5?
Apply via Project Glasswing at anthropic.com/glasswing. As of June 2026, Anthropic has approved 150+ organizations in 15 countries, including Apple, Nvidia, Microsoft, CrowdStrike, NATO, and EU ENISA. The vetting process includes co-disclosure agreements, usage monitoring, and review of defensive use case justification (Anthropic, Jun 2026).
Conclusion
The routing framework matters more than the benchmarks. A 95% SWE-bench score for Fable 5 delivers nothing for a classify-and-route pipeline and adds cost on every call.
The three rules, stated plainly:
- ZDR required: Opus 4.8. It’s the only ZDR-compatible Claude model.
- Cybersecurity or bio domain + Glasswing access: Mythos 5.
- Complex multi-step agentic coding or research synthesis: Fable 5.
- Everything else: Opus 4.8.
Gartner projects that over 40% of agentic AI projects will be canceled by end of 2027 (Gartner, Jun 2025). Misrouted models (with the surprise budget overruns they trigger) are a direct contributor to that failure rate. The teams that get this right early route on task complexity and match model cost to task difficulty.
If you want us to build this for your team, let’s chat.
For full migration steps including ZDR compliance, see the production migration checklist for Opus 4.8 to Fable 5.

