Kimmo Hakonen
Chief Innovation Officer
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 25, 2026
How to Migrate Claude Opus 4.8 to Fable 5: Production Migration Checklist

Claude Fable 5 scores 95.0% on SWE-bench Verified versus Opus 4.8’s 88.6% — a 6.4 percentage point gap that compounds across long agentic task chains (MorphLLM, 2026). But the model-ID swap itself takes two minutes. The six API changes underneath it do not.
Two of those changes produce no error codes in production. Safety refusals come back as HTTP 200 responses. ZDR incompatibility blocks at the workspace level, not the call level. Standard CI pipelines and error-rate dashboards won’t catch either one. This checklist covers all six changes in order of deployment risk, with before/after code examples, a monitoring setup, and a rollback framework with concrete trigger thresholds.
Key Takeaways
- Fable 5 scores 95.0% on SWE-bench Verified vs. 88.6% for Opus 4.8. The performance gap is real, but the migration has six breaking API changes that require explicit fixes (MorphLLM, 2026).
- Safety refusals return as HTTP 200 with
stop_reason: "refusal", not 4xx. Any monitoring that only watches error codes misses them entirely.- Fable 5 requires 30-day data retention. Organizations under zero-data-retention agreements get HTTP 400 until compliance signs off.
- Canary at 5–10% of traffic for 48 hours before full cutover. Three trigger thresholds determine whether to complete the migration or roll back.
Why migrate from Opus 4.8 to Fable 5 now?
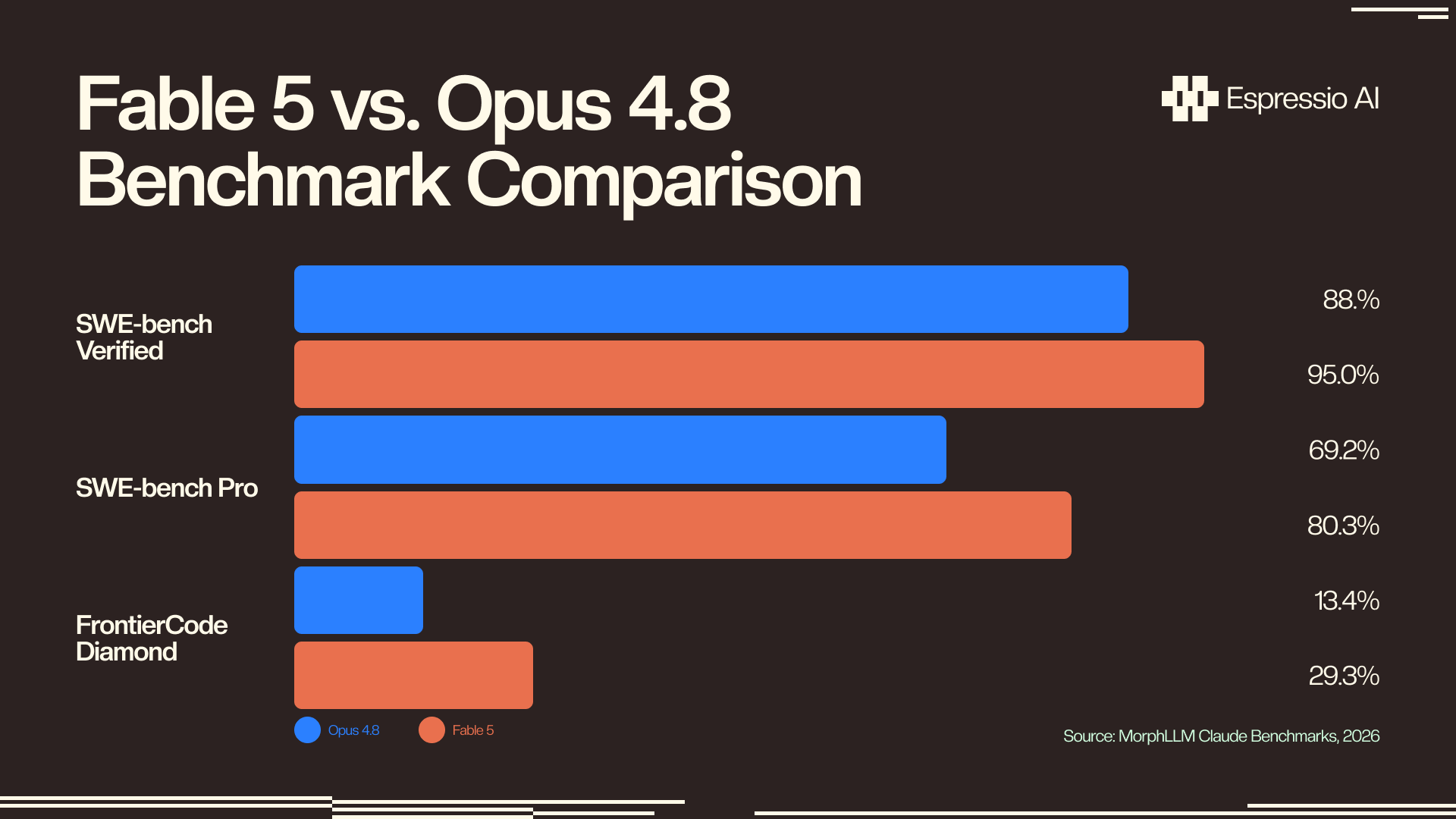
On SWE-bench Pro, Fable 5 scores 80.3% versus Opus 4.8’s 69.2%, an 11-point lead across the professional-grade software engineering evaluation that includes realistic multi-file refactoring (MorphLLM, 2026). FrontierCode Diamond shows the same pattern: 29.3% versus 13.4%. For agentic coding pipelines, those gaps compound: each tool call where Fable 5 catches an edge case that Opus 4.8 misses is a downstream error avoided.
The cost picture is more nuanced. Fable 5 is priced at $10/$50 per million input/output tokens versus Opus 4.8’s $5/$25, a 2x increase. Early production reports from pre-launch testers suggest approximately 50% fewer tokens per agentic task on Fable 5 because the model’s improved reasoning reduces tool-call loops. That ratio puts net cost roughly neutral on complex work. Short classify-and-route tasks with predictable outputs will cost more on Fable 5 and should stay on Opus 4.8 until token reduction data from your own workloads is available.
Gartner forecasts 40% of enterprise applications will embed AI agents by end of 2026, up from under 5% in 2025 (Gartner, Aug 2025). Teams migrating now rather than under deadline pressure have time to run a proper canary. Teams waiting until Q4 will be racing a crowded Anthropic support queue.
We migrated three internal workloads from Opus 4.8 to Fable 5 in staging: a batch document summarization pipeline, a multi-turn research agent, and a SQL generation tool. The ZDR check was the only blocker requiring escalation beyond engineering. Breaking changes 1 through 4 took under two hours combined. The refusal monitoring instrumentation (breaking change 5) took most of a day because it touched every success-path handler in the agent loop.
According to the MorphLLM benchmark tracker, Claude Fable 5 scores 80.3% on SWE-bench Pro versus Opus 4.8’s 69.2%. The FrontierCode Diamond gap (29.3% versus 13.4%) represents complex multi-file coding tasks that production agents encounter regularly in large-scale refactoring work.
For teams building on Claude Fable 5 for research workflows, the performance case for migration is especially strong on multi-document synthesis tasks where reasoning depth compounds across retrieved context.
What are the six breaking API changes in Fable 5?
The Anthropic migration guide documents six changes that produce HTTP 400 errors, silent behavior shifts, or compliance blocks in production (Anthropic, Jun 2026). None are automatic; each requires an explicit fix.
1. Adaptive thinking always-on. Fable 5 has no opt-out for thinking. Remove any thinking: {"type": "disabled"} parameters from your API calls; they return HTTP 400 on Fable 5.
# BEFORE (Opus 4.8)
response = client.messages.create(
model="claude-opus-4-8",
max_tokens=4096,
thinking={"type": "disabled"}, # remove this line
messages=[...]
)
# AFTER (Fable 5)
response = client.messages.create(
model="claude-fable-5",
max_tokens=4096,
messages=[...]
)2. Manual budget_tokens removed. Replace thinking: {"type": "enabled", "budget_tokens": N} with the effort parameter. Valid values: "low", "medium", "high", "auto" (default). The auto default works well for most workloads.
# BEFORE (Opus 4.8 extended thinking)
thinking={"type": "enabled", "budget_tokens": 10000}
# AFTER (Fable 5)
effort="high" # or "auto" if unsure3. max_tokens scope change. On Fable 5, max_tokens caps thinking tokens plus response tokens combined. On Opus 4.8, thinking tokens were additive. Add a 20–30% buffer to your existing max_tokens values on any task where Fable 5 will reason heavily. Existing ceilings that worked fine on Opus 4.8 will truncate mid-reasoning without raising an error.
4. Assistant prefill restricted. Confirm no pre-populated role: "assistant" messages appear in your multi-turn message history. If your conversation builder pre-fills an assistant turn, remove it.
5. stop_reason: "refusal" returns as HTTP 200. Safety classifier blocks return a successful response with stop_reason: "refusal" in the response body, not a 4xx error code. Any try/except logic that only handles status codes will silently drop these. Add an explicit check in every success path:
response = client.messages.create(
model="claude-fable-5",
max_tokens=4096,
messages=[...]
)
# Required on Fable 5 — refusals don't raise exceptions
if response.stop_reason == "refusal":
category = getattr(response.stop_details, "category", "unknown")
logger.warning("Fable 5 refusal", extra={"category": category})
# handle gracefully — do not treat as success
else:
process_response(response)6. ZDR incompatibility. Fable 5 requires 30-day minimum data retention as a Covered Model under Anthropic’s RSP v3.0. Organizations with zero-data-retention agreements receive HTTP 400 invalid_request_error until workspace-level retention is reconfigured. This is a compliance team decision, not an engineering change. Raise it before you touch a line of code.
Breaking change 5 is the most operationally dangerous. An error-rate dashboard monitoring only 4xx/5xx responses will report 100% success even when Fable 5 is refusing a meaningful percentage of requests. We’ve seen teams discover elevated refusal rates only when end users report incomplete outputs. The code was treating stop_reason: "refusal" as a normal successful completion.
On every Fable 5 deployment, the Anthropic migration guide requires handling stop_reason: "refusal" as a distinct response state rather than an error code, because Fable 5’s safety classifiers return HTTP 200 on blocked requests (Anthropic, 2026). Standard error monitoring is insufficient without this change.
How does the Fable 5 safety fallback work in the API?
Fewer than 5% of sessions trigger an automatic routing switch to Opus 4.8, according to Anthropic’s Help Center documentation (Anthropic Help Center, 2026). In the Claude platform, this happens transparently: the session routes to Opus 4.8, the request re-runs, and the response comes back normally. In the Messages API, it does not happen automatically.
The API returns stop_reason: "refusal" and stops. To get server-side retry on Opus 4.8, you need the opt-in fallbacks beta parameter. That parameter is NOT available on the Message Batches API, Amazon Bedrock, Vertex AI, or Microsoft Foundry. On those platforms, client-side fallback logic is required:
import anthropic
client = anthropic.Anthropic()
def call_with_fallback(messages: list, max_tokens: int = 4096) -> str:
response = client.messages.create(
model="claude-fable-5",
max_tokens=max_tokens,
messages=messages
)
if response.stop_reason == "refusal":
# Log the fallback event before retrying
category = getattr(response.stop_details, "category", "unknown")
logger.info("Fable 5 fallback to Opus 4.8", extra={
"category": category,
"fallback_reason": "safety_classifier"
})
# Client-side retry on Opus 4.8
response = client.messages.create(
model="claude-opus-4-8",
max_tokens=max_tokens,
messages=messages
)
return response.content[0].textThe four classifier categories that trigger a fallback: offensive cybersecurity operations (~40% of fallbacks), biology and chemistry synthesis methods (~30%), frontier LLM distillation attempts (~20%), and high-value agentic financial transactions (~10%). Classifiers scan everything the context window contains: conversation history, tool call outputs, web search results, and file attachments. Log the model field on every response to detect fallback sessions without relying on the stop_reason path.
The global <5% figure understates fallback rates for security-adjacent workloads. One practitioner reported the cyber classifier triggering twice on benign security writing (including while writing documentation about the classifier itself). If your agents process vulnerability reports, threat intelligence feeds, or code review outputs from security scanners, measure your actual fallback rate in staging before assuming the global average applies. For a detailed breakdown of each trigger category and its thresholds, see Fable 5 safety fallback categories and trigger thresholds.
Fewer than 5% of Claude Fable 5 API sessions trigger a routing switch to Opus 4.8, according to Anthropic’s Help Center. On the Messages API, that switch requires either the opt-in fallbacks beta parameter or client-side retry logic, and neither option is available on the Message Batches API, Amazon Bedrock, or Vertex AI.
How do you test and validate the migration before cutover?
Among organizations with production agents, 89% have implemented observability, but only 52.4% run offline evaluations on test sets before deploying model changes (LangChain State of Agent Engineering, Dec 2025, n=1,340). The half without offline evals are discovering breaking changes in production. Don’t be in that group for a migration with six known failure modes.
Run five checks in staging before cutover:
- Run your full existing test suite against
claude-fable-5in a staging environment. Record every failure, including test failures you weren’t expecting from breaking changes you thought you’d fixed. - Add
stop_reason: "refusal"assertions to all success-path tests. A test that only checksresponse.contentwill pass even when Fable 5 refused the request. - Re-baseline token counts:
client.messages.count_tokens(model="claude-fable-5"). Fable 5 tokenizes differently from pre-4.7 models (30–35% difference), and thinking tokens now count againstmax_tokens. Update your cost estimators before they start misfiring. - Test a ZDR-flagged request explicitly. Send a call that your workspace settings would have handled under ZDR and confirm the expected HTTP 400 behavior before production traffic hits it.
- Run 5–10 representative prompts with
effort="auto"and compare output depth against your Opus 4.8 baseline. If reasoning depth is lower than expected on tasks that need it, switch toeffort="high".
After validation, run a canary before full cutover: route 5–10% of traffic to Fable 5 and monitor fallback rate, refusal rate, and cost per task for 48 hours. Validate every inter-agent handoff explicitly if your architecture involves model-specific fields.
The LangChain State of Agent Engineering report (Dec 2025, n=1,340) found 89% of production agent teams have some observability in place, yet over half deploy model changes without offline evaluation (LangChain). For a migration with six known breaking changes, running the full test suite in staging with explicit stop_reason: "refusal" assertions turns potential production incidents into caught staging failures.
What monitoring do you need for Fable 5 in production?
The biggest gap in every competitor migration guide: stop_reason: "refusal" returns HTTP 200, so standard error-rate dashboards will never surface it. Add a dedicated refusal counter, separate from your 4xx/5xx error metrics, as the minimum viable monitoring addition for Fable 5.
Five observability additions for a production Fable 5 deployment:
Refusal counter. Track stop_reason == "refusal" events per workload type and per stop_details.category (cyber, bio, reasoning_extraction). Alert if refusal rate exceeds 10% in a 1-hour window on any non-security workload; that’s a signal that prompt drift is trending toward classifier territory.
Fallback rate tracker. Log the model field on every API response. When Fable 5 routes to Opus 4.8, the response returns model: "claude-opus-4-8". A rising fallback rate means classifier hit rates are increasing; investigate prompt content before assuming the model is misbehaving.
Token budget tracker. Re-baseline cost estimators using client.messages.count_tokens(model="claude-fable-5") after migration. The tokenizer change from pre-4.7 models is 30–35%, and thinking tokens now count against max_tokens (DEV.to / TokenMixAI, Jun 2026). If thinking consistently exceeds 80% of your max_tokens cap, increase the cap rather than letting it truncate mid-reasoning.
Thinking-to-output ratio. Monitor the split between thinking tokens and content tokens per call. If thinking is consuming most of the max_tokens cap, either raise the cap or switch from effort="auto" to effort="medium" on that workload.
Rate limit headers. Check x-ratelimit-remaining-tokens and x-ratelimit-limit-tokens on every response, especially after migration. Fable 5 and Opus 4.8 consume separate quota pools: a workload that was well within Opus 4.8 rate limits can unexpectedly hit Fable 5 limits without your existing quota monitoring catching the difference.
On Fable 5, stop_reason: "refusal" events return HTTP 200 and are invisible to standard error-rate monitoring. A dedicated refusal counter keyed to stop_details.category is the minimum instrumentation required; without it, classifier activity is unobservable and compliance reporting on safety events is impossible.
What is the rollback plan if Fable 5 underperforms?
Gartner predicts more than 40% of agentic AI projects will be canceled by end of 2027 due to escalating costs, unclear business value, or inadequate risk controls (Gartner, Jun 2025). A rollback plan converts a bad migration into a recoverable incident, and setup costs almost nothing since rolling back is just a model-ID change.
Three trigger thresholds to define before you go to production. If any is breached, roll back before investigating further:
- Refusal rate: Exceeds 15% of sessions on non-security workloads for 2+ consecutive hours
- Cost per task: Increases more than 50% above the Opus 4.8 baseline after 7 days, with no corresponding quality improvement
- Latency SLA: P99 end-to-end latency exceeds your SLA by more than 30%, sustained for 4+ hours. Fable 5 TTFT under high-context load at standard tier can reach 147 seconds; set SLA baselines in staging against Fable 5 rather than inheriting Opus 4.8 figures (kunalganglani.com, Jun 2026).
Rollback execution: change model="claude-fable-5" back to model="claude-opus-4-8". Re-add thinking={"type": "disabled"} if you had it. Remove the effort parameter. Re-enable ZDR if your workspace was reconfigured.
One distinction worth documenting: if you roll back because output quality changed on a specific task type, that’s a prompt engineering issue, not a model regression. Keep notes on which prompts produced unexpected outputs during canary. Those are tuning targets for the next migration attempt. The right response to output quality changes is prompt engineering.
For a deeper look at how the safety routing architecture works under Fable 5’s RSP v3.0 commitments (including what Mythos 5 does differently), see Fable 5 safety fallback categories and trigger thresholds.
Rolling back from Fable 5 to Opus 4.8 requires three code changes: swap the model ID, restore the thinking parameter structure, and re-enable ZDR if reconfigured. The Anthropic migration guide recommends defining trigger thresholds before cutover so rollback becomes a measured operational step rather than an emergency decision under pressure (Anthropic, 2026).
On our internal migration, the effort="auto" default produced shallower reasoning on SQL generation than the old budget_tokens=8000 setting we’d tuned on Opus 4.8. Switching to effort="high" on that workload brought reasoning depth back in line. If you had tuned budget_tokens carefully on Opus 4.8, test effort="high" explicitly rather than trusting auto to match it.
Frequently Asked Questions
Is Claude Fable 5 a drop-in replacement for Opus 4.8?
Mostly, but not entirely. The Anthropic migration guide documents six changes required before cutover: removing thinking: disabled, replacing budget_tokens with the effort parameter, re-baselining max_tokens, checking for assistant prefill patterns, handling stop_reason: "refusal" as an HTTP 200 response, and resolving ZDR compliance. Most Opus 4.8 workloads migrate successfully once those six items are addressed.
Does Fable 5 support zero data retention (ZDR)?
No. Fable 5 requires 30-day minimum data retention as a Covered Model under Anthropic’s RSP v3.0. Organizations with existing ZDR agreements receive HTTP 400 invalid_request_error responses from Fable 5 until workspace-level retention is reconfigured. This requires a compliance team decision before engineering can proceed with the migration.
How do I detect when Fable 5 routes a session to Opus 4.8?
Check the model field in the API response object. When Fable 5 routes a session to Opus 4.8, the response returns model: "claude-opus-4-8" instead of "claude-fable-5". Log this field on every response. Fewer than 5% of sessions trigger this routing on average, though security-adjacent workloads run higher (Anthropic Help Center, 2026).
Is Fable 5 more expensive than Opus 4.8?
Fable 5 is priced at $10/$50 per million input/output tokens versus Opus 4.8 at $5/$25 — a 2x increase on both dimensions. Early production reports from pre-launch testers suggest approximately 50% fewer tokens per agentic task on Fable 5, which would put net cost roughly neutral for complex workloads. Short classify-and-route tasks with predictable outputs will cost more. Measure your own token counts before projecting costs.
What is the effort parameter in Fable 5?
The effort parameter replaces Opus 4.8’s manual budget_tokens thinking control. It accepts four string values: "low", "medium", "high", and "auto" (the default). The auto default lets Fable 5 decide thinking depth based on request complexity. Attempting to pass thinking: {"type": "enabled", "budget_tokens": N} on Fable 5 returns an HTTP 400 error.
Migrating from Opus 4.8 to Fable 5 has six required steps before the model-ID change goes to production:
- Remove
thinking: {"type": "disabled"}from all API calls - Replace
budget_tokenswith theeffortparameter - Re-baseline
max_tokensvalues with a 20–30% buffer for reasoning tasks - Add
stop_reason: "refusal"handlers to every success path; refusals return HTTP 200 and won’t show up in error logs - Resolve ZDR compliance at the workspace level before engineering touches a line of code
- Define three rollback triggers and document them before cutover, not after
If your team works across multiple Claude deployments, Claude API setup for enterprise teams covers workspace configuration and API key management patterns that apply across the migration.
If you want us to build this for your team, let’s chat.