
Kimmo Hakonen
Chief Innovation Officer
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 16, 2026
How to Design Claude Fable 5 Agents That Remember Across Sessions

Nearly 65% of enterprise AI agent failures in 2025 traced back to context drift and memory loss during multi-step reasoning, and those failures had nothing to do with model quality (Zylos Research, Feb 2026). The agent reasoned correctly in session one. Session two started from nothing.
That’s the memory problem every production team eventually hits: the session ends, the context window clears, and the next run re-interviews the same stakeholders, re-researches the same competitors, re-loads the same code context it already internalized, and re-derives the output preferences a team spent three sessions calibrating. The agent starts each run without any recollection of previous ones.
Claude Fable 5 changes the calculus, but only when you structure memory correctly. The four-layer architecture below handles most production workloads; the retrieval strategy section shows how to cut per-session token costs 73% without degrading output quality. For the broader deployment architecture, see the long-horizon agent reference architecture.
Key Takeaways
- Claude Fable 5 + persistent memory performs 3× better than Opus 4.8 with the same setup on long-horizon benchmarks, because Fable 5’s adaptive thinking scales with retrieved context quality (Anthropic, June 2026).
- Retrieval-based memory cuts per-query tokens 73%, from ~26,000 to ~6,900 tokens (Mem0, 2026).
- Nearly 65% of enterprise agent failures trace to context drift and memory loss, according to Zylos Research’s client analysis (Feb 2026).
- Four stores cover most production workloads: facts, episodic summaries, preferences, and task-context, each structured for independent cacheability.
Why do agents forget — and why does it cost you?
At 95% per-step reliability across a 20-step workflow, combined success rate falls to 36%; a 2% misalignment introduced early in the chain can compound to a 40% overall failure rate by completion (Zylos Research, Feb 2026). Without cross-session memory, this decay resets to zero at the start of every new run.
The failure mode is mechanical. Each session starts with a blank context window. The agent re-reads documents it processed yesterday, re-establishes client context it internalized last week, and re-infers output preferences a team spent multiple sessions teaching it. Those reconstruction tokens cost money before the agent produces a single new output.
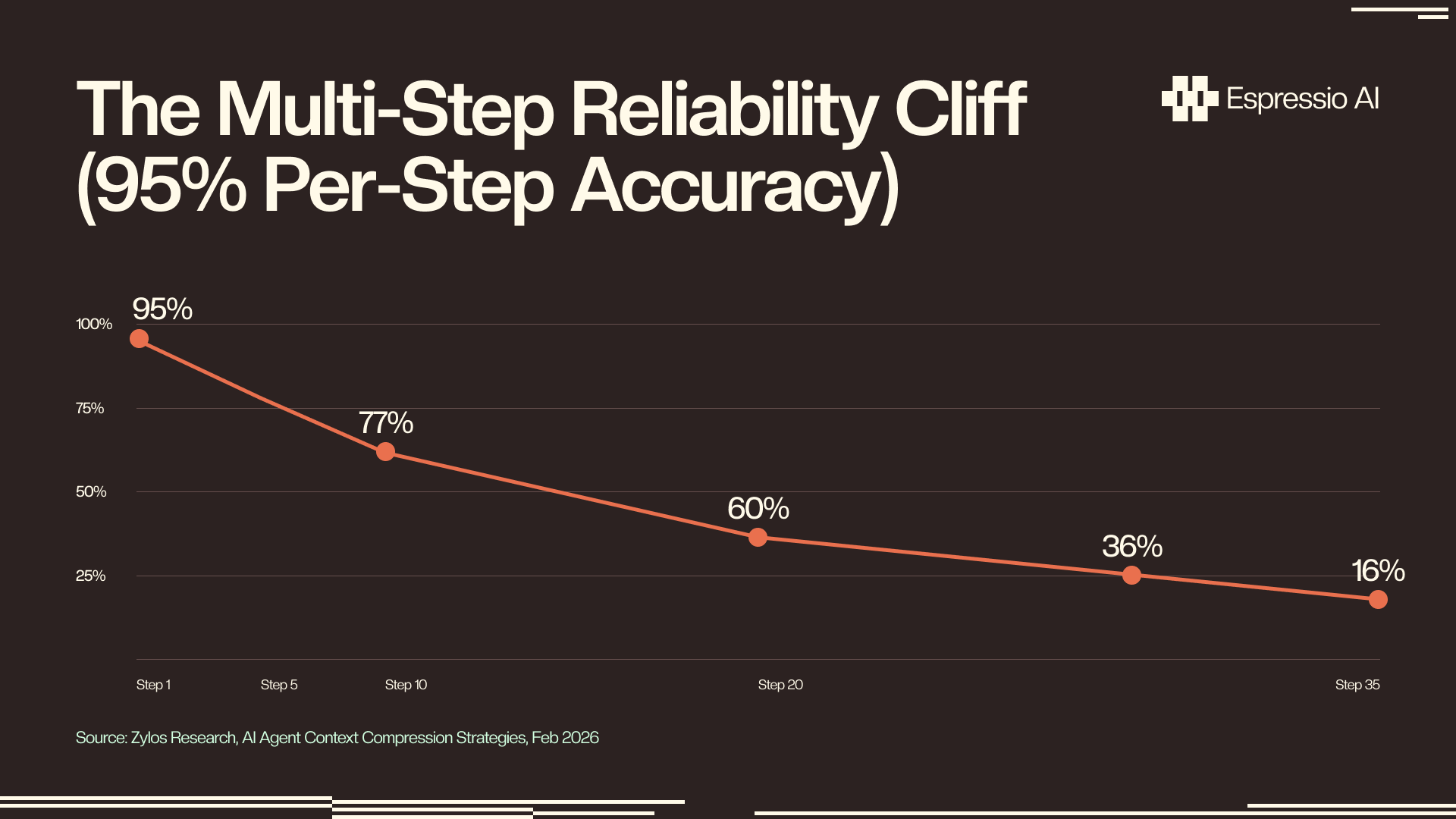
Four drift patterns recur across production deployments: goal drift, where the reconstructed context misses a key constraint and steers the agent toward subtasks it already completed; fact staleness, where entity data changes between sessions (a contact’s role, a pricing tier, a department restructure, or a new active project) but no persistent store holds the updated version; preference forgetting, where the agent re-defaults to generic output formats instead of the calibrated style a team spent sessions teaching it; and context corruption, where reconstruction introduces inaccuracies that compound through every downstream reasoning step.
The financial consequence compounds the quality cost. At Fable 5’s $10/M input rate, a 30K-token reconstruction overhead across 200 daily agent runs costs $60 per day in setup tokens before the first new reasoning step executes.
What makes Fable 5 different from every prior Claude model on memory?
Claude Fable 5 with persistent file-based memory reached the game’s final act 3× more often than Opus 4.8 with an identical setup on the Slay the Spire benchmark (Anthropic, June 2026). The same memory files, the same retrieval approach, dramatically different outcomes.
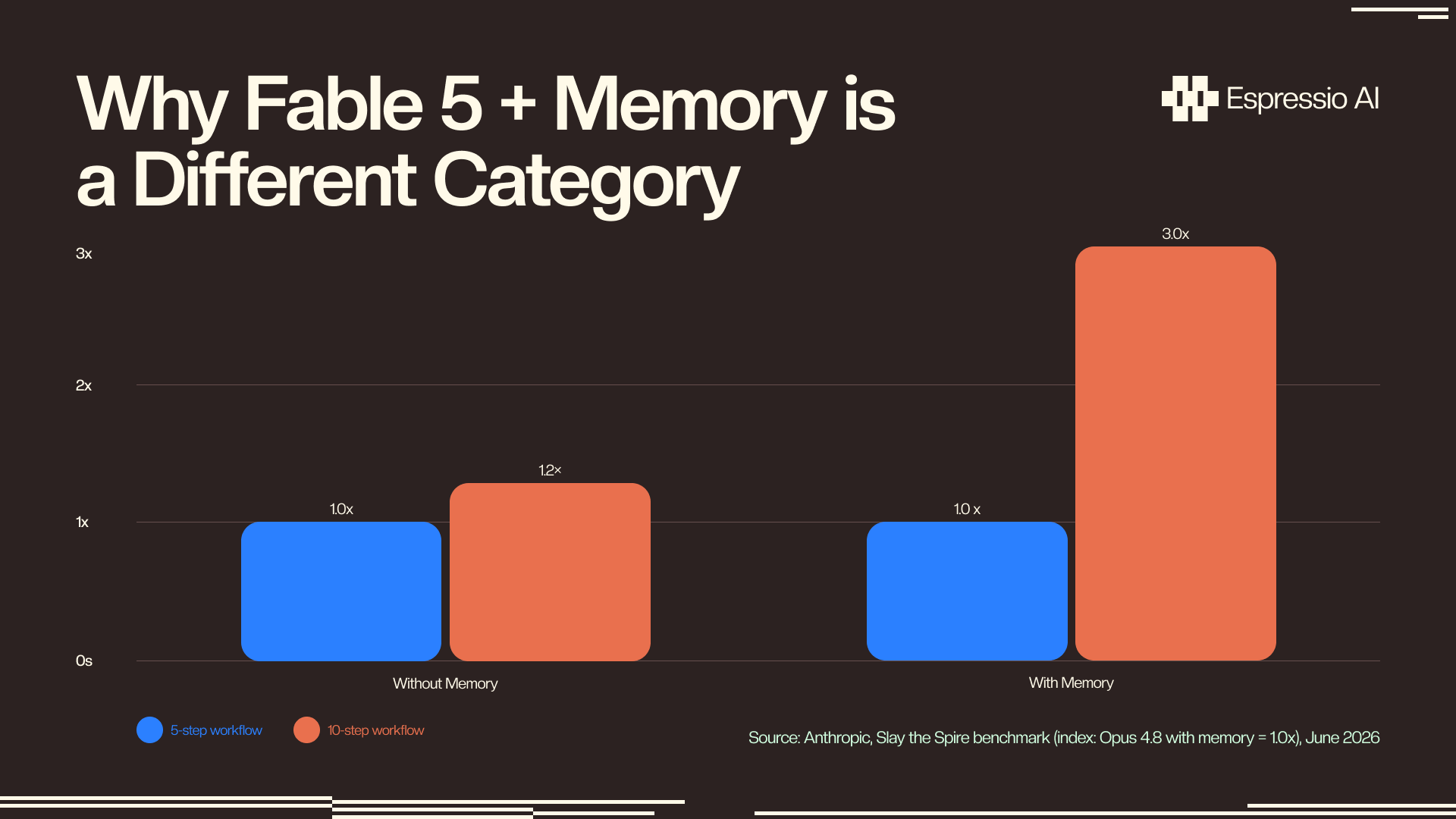
Fable 5’s adaptive thinking scales in quality proportional to the information density of what it retrieves. A well-structured facts store gives it precise, retrievable entities rather than verbose reconstructed summaries, and Fable 5 extracts more signal from that structure per token than Opus 4.8 does. Data structure is the lever. The same memory files organized as typed JSON rather than prose logs produce most of the 3× differential.
This also explains a counterintuitive risk: Fable 5 with a poorly structured memory store can cost more than no memory at all. The model attempts to reason over unstructured data, burns output tokens on clarification, and still misses context a structured episodic summary would have delivered directly. Budget for memory architecture design time before budgeting for the token savings.
The four layers every production agent memory needs
Agentic AI systems require 5–30× more tokens per task than standard conversational AI, with LLM API calls accounting for 70–85% of total agent operating costs (Mem0 State of AI Agent Memory 2026, 2026). Memory architecture determines how much of that cost goes toward productive reasoning vs. session reconstruction overhead.
Production agent memory splits into four distinct stores, each with a specific write schedule and cache role. The facts store holds persistent entities: client names, org structures, product details, and integration configs. Write it once, update it when data changes, load it at every session start. The episodic store holds compressed session summaries (what happened, what was decided, what comes next, and where the workflow stands), written at session end and retrieved before any new work begins. The preferences store holds behavioral calibration: output format, communication style, escalation rules, and model routing preferences; it changes infrequently once calibrated. The task-context store holds the session’s live working state: active subtask data, intermediate results, and in-flight tool outputs, cleared at session completion.
Anthropic’s memory tool, which entered public beta on April 23, 2026, caps individual files at approximately 100KB (~25K tokens) and allows a maximum of 8 stores per session (Anthropic, Apr 2026). For most production agents running 1–3 stores with structured JSON content, that ceiling is more than sufficient.
The first design constraint: structure every store for independent cacheability. A facts store that only changes when a client’s contact list updates sits in the stable context layer and qualifies for Anthropic’s 90% prompt cache discount on every turn that reads it without modifying it. For the interaction between cache layers and memory positioning, see how memory reduces the token multiplier in agentic loops.
Step 1: Enable the memory tool and structure your stores
Anthropic’s memory tool gives agents read and write access to persistent JSON files that survive context window clearing, available since the April 2026 public beta (Anthropic, Apr 2026). The file structure matters more than the file existence.
Structure every store as typed JSON, not prose. A facts store entry looks like:
{
"entity_type": "client",
"name": "Acme Corp",
"primary_contact": "Jane Smith, VP Sales",
"last_updated": "2026-06-10",
"active_project": "RevOps automation pilot"
}The structured version loads in roughly 40 tokens. An equivalent prose entry (“Acme Corp, we’ve been working with them since April, Jane in sales is the main contact”) loads in 80 tokens and requires the model to parse it before use. Across 50 client entities, that’s 2,000 tokens vs. 4,000 tokens on the facts store alone.
Espressio’s Competitive Intel agent ran into this directly. We built the initial episodic store as a plain-text run log: timestamps and narrative summaries of what each session had researched. Within two weeks the store held 18,000 tokens. Each session loaded the entire log, and the agent re-processed context from competitors it had fully analyzed three sessions ago. A session budgeted at $40 was averaging $190. The fix was structural: replacing the prose run log with a typed JSON episodic store holding only the current quarter’s summaries, with older entries archived rather than loaded. Session cost dropped to $32 on the first run after the change — an 83% reduction that came entirely from reformatting existing data, not from reducing scope.
For systems requiring more than 8 stores, or semantic retrieval across large episodic archives, external memory systems (Mem0, Letta, Zep) extend the built-in tool’s ceiling. For growth team workflows running 1–4 stores, the built-in tool covers the full use case without additional infrastructure.
Step 2: Build a retrieval strategy that cuts token costs 73%
Retrieval-based memory cuts per-query tokens approximately 73%, from around 26,000 tokens using naive full-context approaches to around 6,900 tokens on average (Mem0 State of AI Agent Memory 2026, 2026). The right strategy depends on store size and update frequency.
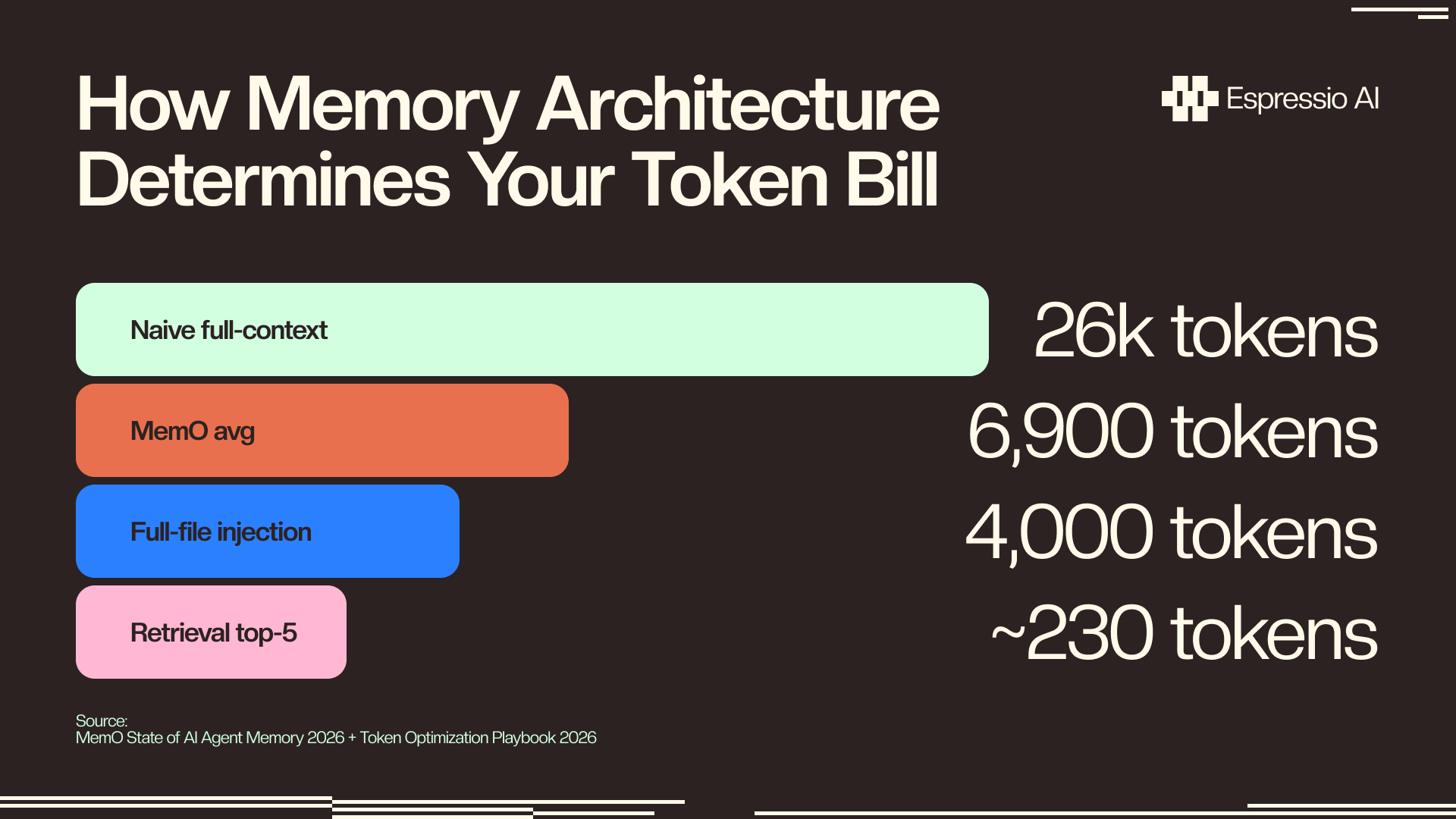
The right retrieval strategy depends on store size and update frequency. Full-file injection loads the entire memory store each turn; use it only for stores under 500 tokens, where the overhead of a retrieval call exceeds any savings. Keyword retrieval loads store entries matching keywords in the current-turn context, suitable for structured JSON stores under 5,000 tokens with predictable key names. Semantic retrieval (Mem0, Letta, Zep) embeds queries and retrieves the top-K most relevant memories; in Mem0’s benchmark, a 24-entry store dropped from 594 tokens with full-file injection to 166 tokens with retrieval, a 72% reduction (Mem0 Token Optimization Playbook 2026, 2026). Hybrid retrieval combines keyword lookup for structured facts with semantic retrieval for episodic archives, and works best when fact and episodic stores grow at different rates.
Two mistakes to avoid: loading all stores at session start rather than on-demand forfeits most of the retrieval savings. Mutating a cached memory value mid-session breaks the cache prefix on that store, triggering full re-computation on every subsequent turn in that session. Write memory at phase boundaries, not mid-task.
How do you prevent context drift in long-running workflows?
Standard LLMs and long-context approaches show a 30% accuracy drop on multi-session memory tasks in the LongMemEval benchmark; structured memory systems deliver 3.5–12.7% higher accuracy than long-context baselines alone on the BEAM benchmark (ICLR 2026), according to Mem0’s analysis (Mem0 AI Memory Benchmarks 2026, 2026). The gap reflects how context is structured across session boundaries, not the underlying model capability.
Three drift patterns have distinct architectural fixes. Goal drift: at each major phase boundary, write an episodic summary that explicitly restates the active objective, the decisions made in the completed phase, and the scope of the next phase. The next session reads this summary before doing anything else. Fact staleness: add a last_updated timestamp to every entity in the facts store and run a stale-check step at session start that flags entities older than your configured threshold before proceeding. Memory corruption: use append-only writes for episodic entries with explicit overwrite triggers. Partial overwrites from ambiguous “update this entry” instructions are the most common corruption source, and they’re almost always preventable with a strict write schema.
The compact-2026-01-12 beta header compacts the volatile context layer: the task-context store contents and in-session reasoning chains. Compaction should never touch the facts or preferences stores; keep those stores in separate positions in the system prompt so the compaction boundary is unambiguous.
For the full beta header reference and phase-boundary patterns step by step, see the long-horizon agent reference architecture.
What does persistent agent memory mean for marketing and RevOps teams?
Rakuten’s production deployment of Claude agents with persistent memory cut initial critical errors 97% and reduced costs more than 30% with no quality degradation (Anthropic / Rakuten, 2026). Wisedocs combined human review with Claude agents backed by memory to catch 30% more document mistakes than human reviewers alone and complete audits 50% faster (Wisedocs, May 2026). Both are business-process deployments running at production scale.
Most growth team workflows map to one of four agent patterns. A competitive intelligence agent runs weekly research cycles: the facts store holds one JSON object per competitor (positioning, pricing, recent news, and share-of-voice data); the episodic store holds weekly run summaries; a preferences store holds the output template the team uses for briefings. The agent never re-researches a competitor from scratch. A proposal synthesis agent pulls from a CRM-backed facts store (account history, deal stage, previous messaging) and an episodic store of past call summaries, contextualizing every new proposal against what’s already been said and committed to. A content production agent uses a facts store for brand voice and editorial standards, an episodic store for past performance data and topic coverage, and a preferences store for channel-specific format rules. A CRM enrichment agent uses a facts store of contact records and an episodic store of recent touchpoints to update field values without re-pulling account history on every run.
None of these patterns require a Python environment. Espressio runs the Anthropic API behind Make.com or n8n for session triggers and data routing, with Airtable or Notion as the structured layer that feeds the JSON stores. The Fable 5 memory advantage compounds further for these use cases because competitive analysis, proposal synthesis, and content production are precisely the ambiguous, high-reasoning tasks where Fable 5’s adaptive thinking scales with retrieved context quality.
If you want to map this memory architecture to your specific workflows, let’s chat. The Espressio team designs memory stores and retrieval strategies for your agent stack in 45 minutes.
For multi-agent architectures that share memory stores across agents, see multi-agent memory sharing in CrewAI pipelines. For the broader revenue team automation playbook, see revenue team automation workflows that benefit from persistent memory.
Frequently asked questions
Does Fable 5’s 1M-token context window make persistent memory unnecessary?
Even with 1M tokens available, re-sending 800K tokens of session history costs 8× more per turn than loading a 100K structured memory store and retrieving only what’s relevant. The context window sets the ceiling for what an agent can process in one turn; memory architecture determines how much of that ceiling gets consumed by historical overhead vs. active reasoning. Large contexts and structured memory solve different problems (Anthropic, June 2026).
What is the Slay the Spire benchmark and what does it prove about agent memory?
Slay the Spire is a roguelike strategy game used to test long-horizon planning with accumulated knowledge across sessions. Fable 5 with persistent file-based memory reached the final act 3× more often than Opus 4.8 with an identical memory setup. The benchmark demonstrates that Fable 5’s adaptive thinking scales with structured retrieved context in ways Opus 4.8 does not; the same memory files that marginally improve Opus 4.8 are transformative for Fable 5 (Anthropic, June 2026).
Should I use Claude’s built-in memory tool or an external system like Mem0 or Letta?
Use the built-in tool for 1–3 stores with total size under 100KB per store, where keyword or full-file retrieval is sufficient. Move to Mem0 or Letta when you need semantic retrieval across episodic archives over 10K tokens, need more than 8 stores, or are sharing memory across multiple agents in a fan-out pipeline (see persistent memory for coding agent sessions). Mem0’s selective retrieval averages 6,900 tokens per query vs. 26,000 tokens for naive full-context approaches (Mem0, 2026).
How does persistent memory interact with prompt caching?
Memory stores in the stable context layer (positions 1–2 in the four-layer cache structure: system prompt, project context/memory, episodic summary, current-turn volatile content) qualify for Anthropic’s 90% cache read discount. A 30K-token facts store loaded at every turn costs $0.30 per turn at Fable 5 rates without caching, and $0.03 with caching. Across 200 daily turns, that’s a $1,620/month difference at team scale.
What causes AI agent context drift and how does memory fix it?
Context drift is the gradual divergence between what an agent believes to be true about its task and what is actually true, caused by accumulated inaccuracies across multi-step or multi-session workflows. Three sources: goal drift (objectives shift when context is reconstructed imprecisely), fact staleness (entity data changes between sessions without store updates), and memory corruption (partial overwrites from ambiguous write instructions). Structured stores with typed schemas and append-only episodic writes prevent all three. Standard LLMs without memory show 30% accuracy drops on multi-session tasks in LongMemEval benchmarks (Mem0, 2026).
Next steps
Persistent memory turns a session-bounded agent into one that compounds knowledge over time. Fable 5 amplifies that compounding more than any prior Claude model, but only when the stores are typed, structured, and positioned for cacheability.
The three-step implementation path: build the four-layer store architecture (facts, episodic, preferences, task-context), match a retrieval strategy to each store’s size and update frequency, and write at phase boundaries rather than mid-task. Teams that complete all three steps typically recover 55–75% of per-session token overhead within the first week of production runs.
- For context editing, cache-prefix discipline, and phase-boundary patterns alongside memory, see the long-horizon agent reference architecture.
- For how memory stores interact with multi-model fan-out in coding pipelines, see persistent memory for coding agent sessions.
- For the revenue team automation context, see revenue team automation workflows that benefit from persistent memory.
If you want us to build this for your team, let’s chat.

