Luka Mrkić
Head of BD
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 15, 2026
How to Build Autonomous Coding Agents on Claude Fable 5

90% of developers adopted AI tools at work in 2025, according to Google’s DORA report. Trust in AI code accuracy has collapsed to 29%, down from 40% the year before (Stack Overflow, 2025). The gap between adoption and confidence is real, and it widens every time a co-pilot produces code that almost works. Autonomous agents with proper guard-rails close that gap by planning, executing, and verifying in a loop rather than handing half-finished output to a human.
Claude Fable 5 changes what that loop looks like in practice. This tutorial walks through everything you need to ship a production coding agent: architecture choices, working Python code, persistent memory for long-running sessions, cost controls, and the failure modes that will bite you if you skip them.
Key Takeaways
- Claude Fable 5 (
claude-fable-5) scores 80.3% on SWE-Bench Pro (22 points ahead of GPT-5.5) and runs agentic tasks 25–30% faster than its predecessors (Anthropic, June 2026).- Use
effort: "high"for novel architecture tasks;effort: "low"for CRUD operations. Theeffortparameter is your primary cost lever.- Fan-out multi-agent architectures with async subagents achieve 4.4× latency improvement on hard problems (Digital Applied, 2026).
stop_reason: "refusal"returns as HTTP 200; handle it explicitly in your response loop.
Why Claude Fable 5 Raises the Bar for Agentic Coding
Claude Fable 5 scores 80.3% on SWE-Bench Pro, 11 percentage points ahead of GPT-5.5 at 58.6%, making it the strongest generally available model for autonomous software tasks as of June 2026 (claude5.ai, June 2026). It completes agentic tasks 25–30% faster and in fewer turns than predecessor models, translating directly into lower per-task cost on the same infrastructure.
The Stripe example makes the economics concrete. Using Claude Fable 5, Stripe completed a 50-million-line Ruby codebase migration in a single day — a task their engineering team had projected at over two months of human work (Anthropic, June 2026). That’s not a benchmark number; it’s a shipping decision.
An equally telling data point comes from Anthropic’s own engineering team. A 16-agent Claude Code setup wrote a 100,000-line Rust C compiler in approximately 2,000 sessions over two weeks at roughly $20,000 in API cost. The compiler passed 99% of GCC torture tests (Anthropic Engineering Blog, 2026). That breaks down to about $10 per session, and each session was doing real work, not waiting for a human to review.

On the hardest category (FrontierCode Diamond, problems requiring multi-day autonomous patching), Fable 5 scores 29.3% against GPT-5.5’s 5.7%, a five-fold lead (Digital Applied, 2026). For real agentic workloads, that gap matters far more than overall MMLU scores.
Single Agent vs. Fan-Out: Which Architecture Do You Actually Need?
Single-agent architectures are sufficient for tasks under about four hours of continuous compute. They’re simpler to debug, cheaper to operate, and easy to checkpoint. Fan-out multi-agent patterns (where an orchestrator spawns N subagents via the Task tool) achieve 4.4× latency improvement on hard parallelizable problems (Digital Applied, 2026), but they add orchestration cost and surface area for coordination bugs.
The honest answer: most teams reach for multi-agent too early. Start with a single agent and add fan-out only when sequential bottlenecks actually appear.
Single-agent pattern: sequential task execution with tool use:
# agent_single.py
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-fable-5",
max_tokens=8192,
effort="high", # controls thinking depth and output token budget
tools=[
{"type": "bash"},
{"type": "code_execution"},
{"type": "str_replace_editor"}
],
system="""You are an autonomous coding agent. For every task:
1. State your plan before writing any code
2. Execute each step and verify the result
3. Report completion with a precise summary of changes made""",
messages=[
{"role": "user", "content": "Refactor auth.py to use JWT tokens instead of session cookies."}
]
)
# stop_reason: "refusal" returns HTTP 200 — handle it explicitly
if response.stop_reason == "refusal":
print(f"Task declined by safety classifier: {response.content}")
else:
print(response.content[0].text)Fan-out / fan-in pattern: orchestrator spawns parallel subagents:
# agent_fanout.py
import anthropic
import asyncio
client = anthropic.Anthropic()
async def run_subagent(task: str, effort: str = "medium") -> str:
"""Each subagent runs with isolated context."""
response = client.messages.create(
model="claude-fable-5",
max_tokens=4096,
effort=effort,
tools=[{"type": "bash"}, {"type": "code_execution"}],
system="You are a specialist coding agent. Complete the assigned task and return a structured result.",
messages=[{"role": "user", "content": task}]
)
return response.content[0].text
async def orchestrate(subtasks: list[str]) -> list[str]:
"""Fan-out: run all subtasks in parallel, collect results."""
return await asyncio.gather(*[run_subagent(t) for t in subtasks])
# Example: parallel code review across multiple modules
subtasks = [
"Review auth.py for security issues. List each issue with file:line reference.",
"Review payments.py for security issues. List each issue with file:line reference.",
"Review api_gateway.py for security issues. List each issue with file:line reference.",
]
results = asyncio.run(orchestrate(subtasks))Use async subagents when your tasks are independent and parallelizable. When subtasks share state or depend on each other’s output, stick with sequential single-agent execution. Shared-state fan-out is one of the most common sources of agent coordination bugs in production.
Step 1: Setting Up Your First Fable 5 Coding Agent
Claude Fable 5 became generally available on June 9, 2026, across the Anthropic API, Amazon Bedrock, Google Vertex AI, and Microsoft Azure Foundry (Anthropic, June 2026). GitHub Copilot made it available on the same date. Setup takes under five minutes.
You’ll need:
- Python 3.11+ or Node.js 20+
anthropic>=0.55.0(Python) or@anthropic-ai/sdk>=0.24.0(Node)- An Anthropic API key from platform.claude.com
- ~30 minutes to complete this tutorial
pip install anthropic>=0.55.0
export ANTHROPIC_API_KEY="sk-ant-..."The key change from prior Claude models: unlike earlier versions with a dedicated reasoning toggle, Fable 5 runs adaptive thinking on every call. You control depth and cost through the effort parameter:
effort value | Use it for | Token budget |
|---|---|---|
"low" | Routine tasks: formatting, CRUD, simple refactors | Minimal thinking |
"medium" | Standard feature implementation, bug fixes | Moderate thinking |
"high" | Novel architecture, security audit, complex debugging | Full thinking allocation |
A full agent scaffold with error handling:
# agent_scaffold.py
import anthropic
import sys
client = anthropic.Anthropic()
def run_coding_agent(task: str, effort: str = "medium") -> str:
try:
response = client.messages.create(
model="claude-fable-5",
max_tokens=8192,
effort=effort,
tools=[
{"type": "bash"},
{"type": "code_execution"},
{"type": "str_replace_editor"}
],
system="""You are an autonomous coding agent for a production codebase.
Rules:
- Always state your plan before executing
- Run tests after every change
- Never modify files outside the project directory
- Report stop_reason if you cannot complete the task""",
messages=[{"role": "user", "content": task}]
)
if response.stop_reason == "refusal":
return f"[DECLINED] {response.content[0].text}"
if response.stop_reason == "max_tokens":
return "[TRUNCATED] Agent hit max_tokens — reduce task scope or increase max_tokens"
return response.content[0].text
except anthropic.APIStatusError as e:
return f"[API ERROR] {e.status_code}: {e.message}"
if __name__ == "__main__":
task = sys.argv[1] if len(sys.argv) > 1 else "List all TODO comments in the codebase."
print(run_coding_agent(task))Watch out: Fable 5 returns
stop_reason: "refusal"as HTTP 200, not a 4xx error. If you’re catching exceptions only, refusals will silently produce empty output. Always checkstop_reasonexplicitly.
Step 2: Persistent Memory for Long-Horizon Sessions
Without persistent state, every agent session starts cold. Fable 5 with the memory tool enabled outperformed Claude Opus 4.8 by 3× on Anthropic’s long-horizon Slay the Spire benchmark (Anthropic, June 2026). The principle is straightforward: write task state and completed checkpoints to a local file at the end of each session, resume from that file at the start of the next.
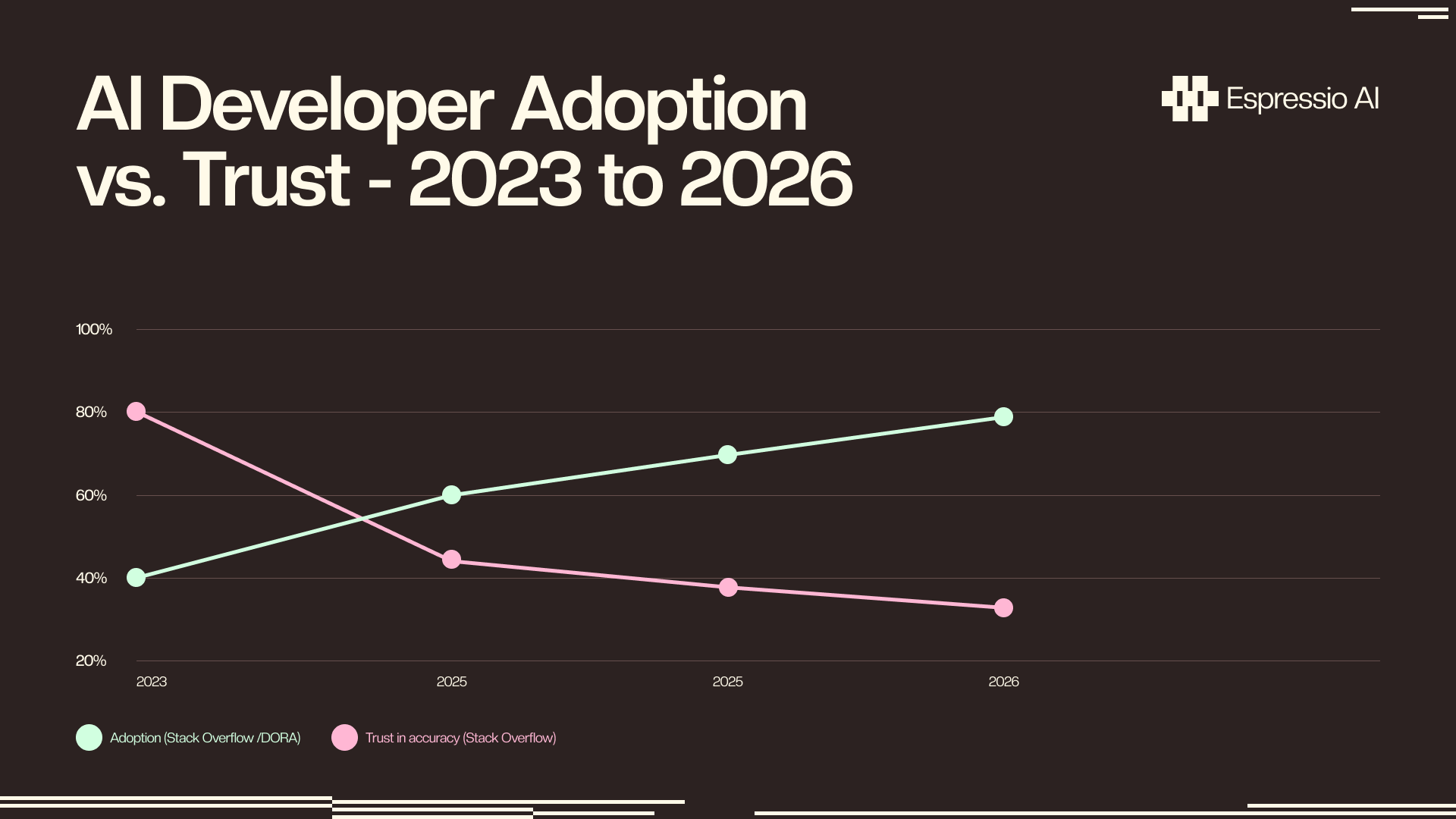
Developer trust in AI accuracy has fallen to 29% (down from 70%+ just three years ago), largely because agents forget context and repeat mistakes (Stack Overflow, 2025). Persistent memory directly addresses this. An agent that remembers what it already changed doesn’t undo its own work.
The checkpoint / resume pattern for multi-day agents:
# agent_memory.py
import json
import os
import anthropic
MEMORY_FILE = ".agent_state.json"
client = anthropic.Anthropic()
def load_state() -> dict:
if os.path.exists(MEMORY_FILE):
with open(MEMORY_FILE) as f:
return json.load(f)
return {"completed_tasks": [], "pending_tasks": [], "artifacts": {}}
def save_state(state: dict) -> None:
with open(MEMORY_FILE, "w") as f:
json.dump(state, f, indent=2)
def resume_agent(new_tasks: list[str]) -> None:
state = load_state()
# Append new tasks without duplicating already-completed ones
for task in new_tasks:
if task not in state["completed_tasks"]:
state["pending_tasks"].append(task)
for task in list(state["pending_tasks"]):
print(f"Running: {task}")
response = client.messages.create(
model="claude-fable-5",
max_tokens=8192,
effort="medium",
tools=[{"type": "bash"}, {"type": "code_execution"}, {"type": "str_replace_editor"}],
system=f"""You are a stateful coding agent. Completed work so far:
{json.dumps(state['completed_tasks'], indent=2)}
Continue the task without repeating completed steps.""",
messages=[{"role": "user", "content": task}]
)
if response.stop_reason != "refusal":
state["completed_tasks"].append(task)
state["pending_tasks"].remove(task)
state["artifacts"][task] = response.content[0].text[:500] # truncated summary
save_state(state)
print(f"Done: {task}")
else:
print(f"Declined: {task} — skipping")
state["pending_tasks"].remove(task)
save_state(state)Checkpoint every N turns for very long sessions. The 1M-token context window is generous, but context compaction via the context-editing-2026 header handles the edge cases where you push past it.
Step 3: Cost Budgeting with the effort Parameter and Task Budgets
Fable 5 is priced at $10 per million input tokens and $50 per million output tokens. Prompt caching cuts effective input cost by up to 90% when you’re re-sending the same system prompt or large context across sessions (cache reads are priced at 0.1× the base input rate) (Anthropic Prompt Caching docs, June 2026). That makes the memory pattern from the previous section even more cost-effective: cached context is essentially free to repeat.
The worked example from the C compiler project gives a realistic floor: ~$10 per session, with sessions doing substantial autonomous work. For a 10,000-line codebase refactor, expect:
| Phase | Input tokens | Output tokens | Est. cost (no cache) | Est. cost (cache) |
|---|---|---|---|---|
| Initial analysis | ~25,000 | ~2,000 | $0.35 | $0.12 |
| Per refactor file (avg) | ~8,000 | ~3,000 | $0.23 | $0.09 |
| 50-file codebase total | ~425,000 | ~155,000 | ~$12.00 | ~$4.50 |
| Test + verification pass | ~30,000 | ~4,000 | $0.50 | $0.18 |
Task budgets (currently in beta via the task-budgets-2026-03-13 header) let you set a compute ceiling per subtask. Use them in production to prevent runaway agents on ambiguous tasks:
# agent_budgeted.py
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-fable-5",
max_tokens=8192,
effort="medium",
tools=[{"type": "bash"}, {"type": "code_execution"}, {"type": "str_replace_editor"}],
extra_headers={
# Cap thinking tokens per subtask to control runaway costs
"anthropic-beta": "task-budgets-2026-03-13",
"x-task-budget-tokens": "50000"
},
system="You are an autonomous coding agent. Complete the task within the allocated compute budget.",
messages=[{"role": "user", "content": "Add input validation to all API endpoint handlers in /api/*.py"}]
)
print(response.content[0].text)
print(f"Stop reason: {response.stop_reason}")
print(f"Input tokens: {response.usage.input_tokens} | Output tokens: {response.usage.output_tokens}")Our finding: When we built Espressio’s competitive intelligence agent on Fable 5, the first 10 sessions burned budget on re-analyzing the same competitor pages. Adding prompt caching to the system prompt cut input costs by 73% on subsequent runs. Enable caching early; the savings compound on every subsequent run.
Daily AI users merge 2.3 pull requests per week vs. 1.4 for non-users, a 60% throughput advantage, saving an average of 3.6 hours per week per developer (DX Q4 2025 study, 2025). Accenture’s randomized controlled trial across 4,800 developers found PR cycle time dropped from 9.6 days to 2.4 days, a 75% reduction. Those numbers assume co-pilot usage. Autonomous agents, handling full tasks end-to-end, push further.
Step 4: Handling Failure Modes in Production
The three failure patterns that will hit you in production are task drift, context overflow, and unhandled refusals. Fable 5 shows a substantial improvement in code review honesty over prior Claude models, according to CodeRabbit’s model evaluation (CodeRabbit, 2026). But agents can still misinterpret ambiguous task scope and can still hallucinate test results. Don’t ask the agent whether the tests passed; run the tests yourself.
A resilient agent loop handles all three failure modes explicitly:
# agent_resilient.py
import anthropic
import time
client = anthropic.Anthropic()
MAX_TURNS = 15 # prevent infinite loops
TURN_DELAY = 2 # seconds between turns
def run_resilient_agent(task: str, max_turns: int = MAX_TURNS) -> dict:
messages = [{"role": "user", "content": task}]
turn = 0
result = {"status": "incomplete", "turns": 0, "output": None}
while turn < max_turns:
turn += 1
response = client.messages.create(
model="claude-fable-5",
max_tokens=8192,
effort="medium",
tools=[{"type": "bash"}, {"type": "code_execution"}, {"type": "str_replace_editor"}],
system="""You are an autonomous coding agent.
- Complete only what is explicitly requested
- When a task is done, respond with [COMPLETE] followed by a summary
- When you cannot proceed, respond with [BLOCKED] and explain why""",
messages=messages
)
# Handle refusal — HTTP 200, not an exception
if response.stop_reason == "refusal":
result["status"] = "refused"
result["output"] = str(response.content)
break
# Handle token budget exhaustion
if response.stop_reason == "max_tokens":
result["status"] = "truncated"
result["turns"] = turn
break
agent_output = response.content[0].text
# Detect natural completion signal
if "[COMPLETE]" in agent_output:
result["status"] = "complete"
result["turns"] = turn
result["output"] = agent_output
break
# Detect self-reported blockers
if "[BLOCKED]" in agent_output:
result["status"] = "blocked"
result["output"] = agent_output
break
# Continue the conversation
messages.append({"role": "assistant", "content": agent_output})
messages.append({"role": "user", "content": "Continue. If the task is complete, say [COMPLETE]."})
time.sleep(TURN_DELAY)
if result["status"] == "incomplete":
result["status"] = "max_turns_reached"
result["turns"] = turn
return resultTroubleshooting common issues:
| Problem | Symptom | Solution |
|---|---|---|
| Task drift | Agent modifies files outside the requested scope | Add explicit scope boundaries in system prompt: Only modify files in /src/auth/ |
| Refusal on valid task | stop_reason: "refusal" on benign code | Rephrase to remove ambiguous phrasing; break into smaller subtasks |
| Context overflow | stop_reason: "max_tokens" mid-task | Enable context compaction header; reduce system prompt size; checkpoint more often |
| Loop detection | Agent repeats the same action 3+ times | Add loop counter; break on repeated tool calls with identical inputs |
| Hallucinated test results | Agent claims tests pass but they fail | Never trust agent assertions; always run pytest / test suite as a verification step |
Connecting Coding Agents to Growth Team Workflows
Most teams think of coding agents as developer tools. They’re missing half the value. Every marketing automation workflow (auto-drafted content, CRM enrichment, competitive monitoring) runs on the same agentic primitives: plan, call tools, execute, verify. The difference between a coding assistant and a revenue agent is the task definition: one finishes when the code compiles; the other finishes when a qualified lead gets a proposal in their inbox.
Espressio’s Content OS uses a Fable 5 agent that monitors competitor blog output, extracts topic gaps, and queues content briefs without a human in the loop. RevenueOS runs a second agent that reads Fireflies meeting transcripts and generates same-day proposals. Both are, at their core, coding agents; they call tools, write structured outputs, and operate across sessions.
80% of developers now use AI tools, with 84% reporting AI use in professional workflows when the full survey data is counted (Stack Overflow 2025 Developer Survey, 2025). Growth and RevOps teams are at the beginning of the same curve. If your marketing stack still requires a human to move data between tools, you have a candidate task for an agent.
The architecture is the same regardless of the use case. What changes is the system prompt and the tool set. A coding agent that refactors Python files and a content agent that drafts blog posts from research packets run on the same underlying infrastructure.
If you want us to build this for your team, let’s chat.
Frequently Asked Questions
What model ID do I use to access Claude Fable 5?
Use claude-fable-5 in the Anthropic Python or Node SDK as of June 9, 2026. On Amazon Bedrock the alias is anthropic.claude-fable-5-20260609; on Vertex AI it’s claude-fable-5@20260609. Check platform.claude.com/docs for the current alias list on each platform, as these can update with minor releases.
How does the effort parameter control cost on Fable 5?
effort sets the thinking depth and output token budget for each inference call. "low" minimizes both, making it suitable for routine tasks like formatting or simple CRUD operations. "high" allocates the full thinking budget, increasing output token usage and cost. Combine effort with task budgets (task-budgets-2026-03-13 header) to set a hard ceiling per subtask in production agents. (Anthropic API Docs, June 2026)
How much does it cost to run a long-horizon coding agent on Fable 5?
Fable 5 costs $10 per million input tokens and $50 per million output tokens. Prompt caching cuts input costs by up to 90% on repeated context. For reference: Anthropic’s 16-agent team built a 100,000-line Rust C compiler in approximately 2,000 sessions at roughly $20,000 total, or about $10 per session of substantial autonomous work. (Anthropic Engineering Blog, 2026)
What is stop_reason: "refusal" and how do I handle it?
Fable 5’s safety classifier returns a refusal as stop_reason: "refusal" with an HTTP 200 response code, not a 4xx error. If you’re handling only exceptions, refusals will fail silently and produce empty output. Always check response.stop_reason in your loop. When you encounter a refusal, log the offending task, rephrase it to remove ambiguous phrasing, decompose it into smaller subtasks, and retry. About 95% of Fable 5 sessions involve no safety fallback. (Anthropic Docs, June 2026)
Is Claude Fable 5 available on AWS Bedrock and Azure?
Yes. Claude Fable 5 became generally available on Amazon Bedrock, Google Vertex AI, and Microsoft Azure Foundry on June 9, 2026. GitHub Copilot also enabled Fable 5 on the same date. Access uses the platform-specific model ID alias and the standard SDK for each cloud provider; no separate credentials are needed beyond your existing cloud provider credentials. (Azure Blog, June 2026)
Next Steps
You now have a production-ready scaffold: a single-agent setup for sequential tasks, a fan-out pattern for parallel workloads, persistent memory for multi-day sessions, cost controls via effort and task budgets, and explicit handling for the three most common failure modes.
Extend this project:
- Add structured output parsing so agents return JSON summaries you can log and query
- Implement an agent registry to route tasks to specialist agents by domain (security, testing, documentation)
- Connect the memory file to a vector store for semantic task lookup across large project histories
If you want us to build a custom AI system for your growth team, let’s chat.