
Kimmo Hakonen - Chief Innovation Officer
Espressio AI
Insights, strategies, and real-world playbooks on AI-powered marketing.
JUN 15, 2026
Long-Horizon AI Agents with Claude Fable 5: Reference Architecture
Stripe migrated 50 million lines of Ruby code in a single day using a team of Claude agents working in parallel, a task projected at two-plus months for a human team (Anthropic, June 2026). Behind that result was a production architecture that kept those agents coherent and cost-bounded across hours of continuous operation, with recovery built in at every phase boundary.
Zylos Research found that 65% of enterprise agent failures trace back to context drift and memory loss during multi-step reasoning, a cause that sits entirely in the architecture layer (Zylos Research, February 2026). Building an agent that completes a task once is straightforward. One that stays coherent on hour four of a 24-hour session is an architecture problem.
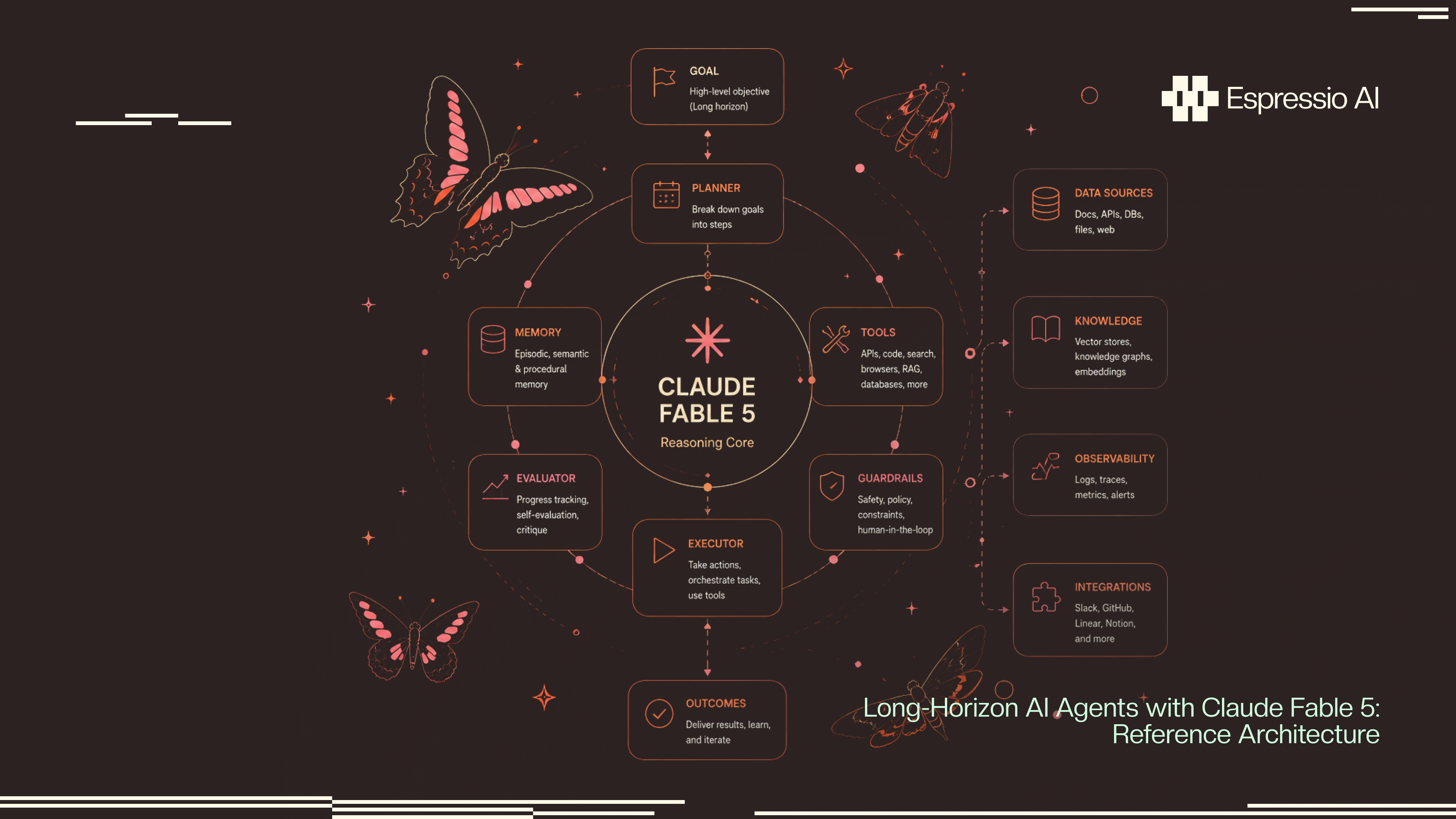
This reference architecture covers all six of Fable 5’s native building blocks for long-horizon operation, three production-proven orchestration patterns, a cost model for extended runs, and failure recovery code you can deploy today. Marketing and RevOps teams will find a dedicated section showing how the same patterns apply without writing a line of Python.
Key Takeaways
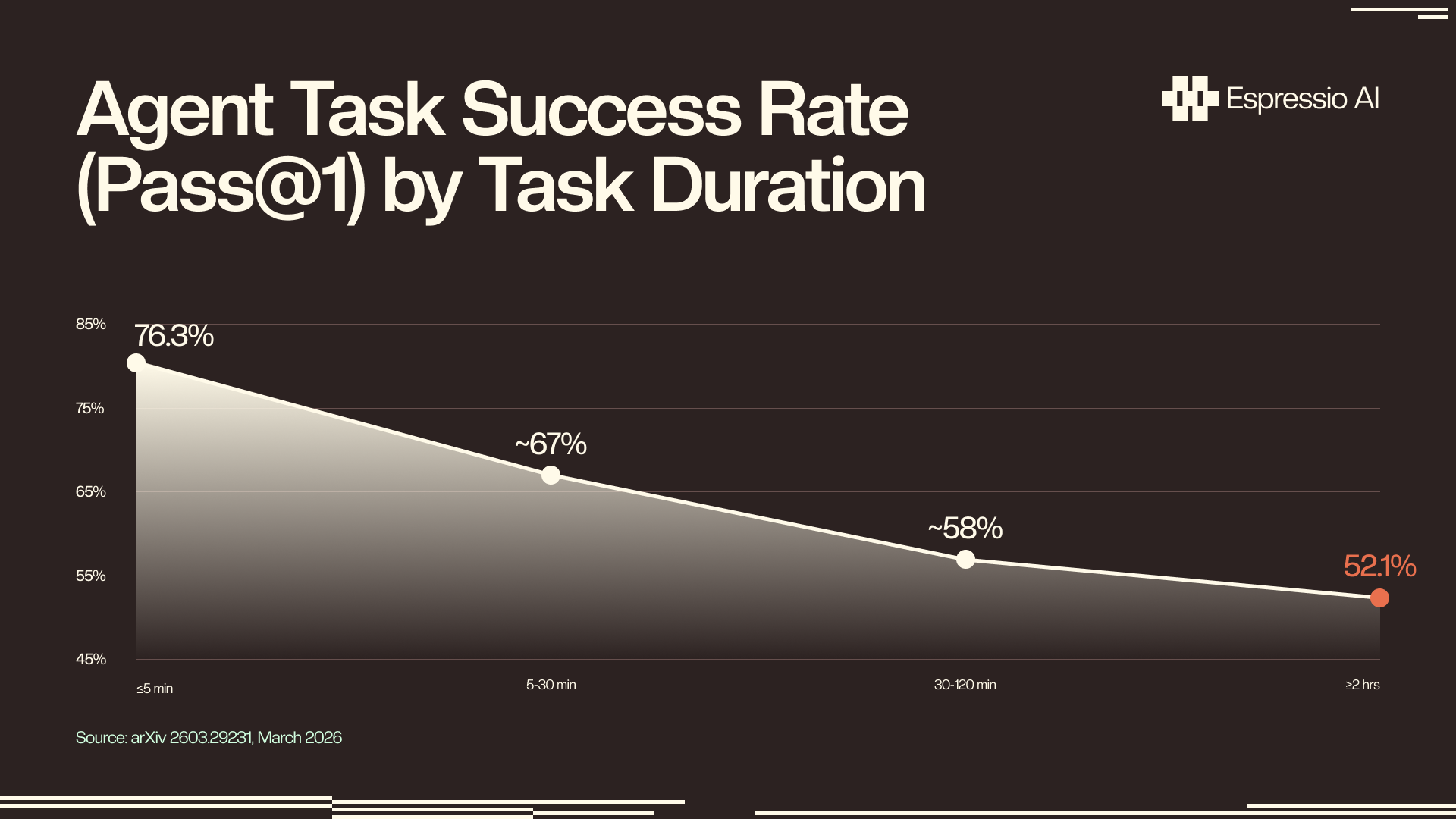
- Pass@1 success rates drop from 76.3% on tasks under 5 minutes to 52.1% on tasks over 2 hours (arXiv 2603.29231, 2026). Architecture closes that gap, not the model.
- Claude Fable 5 ships six native building blocks for long-horizon operation: memory tool, task budgets, context compaction, context editing, adaptive thinking, and subagent orchestration.
- Unoptimized agentic workflows cost 10-100× more than single-call interactions; re-sent context accounts for 62% of billing (LeanOps, 2026).
- A 12-step RevOps agent at 90% per-step accuracy has only 28% end-to-end success without checkpoints. Plan-Execute-Verify with four checkpoint-commits raises that to ~85%.
- 57% of organizations now deploy multi-step agent workflows and 80% report measurable economic impact (Anthropic State of AI Agents, 2026).
Why long-horizon agents fail before hour two
Frontier AI agents achieve pass@1 success rates of 76.3% on tasks under five minutes but just 52.1% on tasks that run longer than two hours, a 24.3-percentage-point drop as duration extends (arXiv 2603.29231, March 2026). Two root causes drive this collapse: context rot and per-step error compounding, and their effects are multiplicative.
Context rot happens when the agent’s working memory fills with completed steps, stale tool outputs, and intermediate reasoning that no longer belongs in the active context. The agent starts re-fetching data it already has, contradicting itself across phases, or treating completed work as still pending.
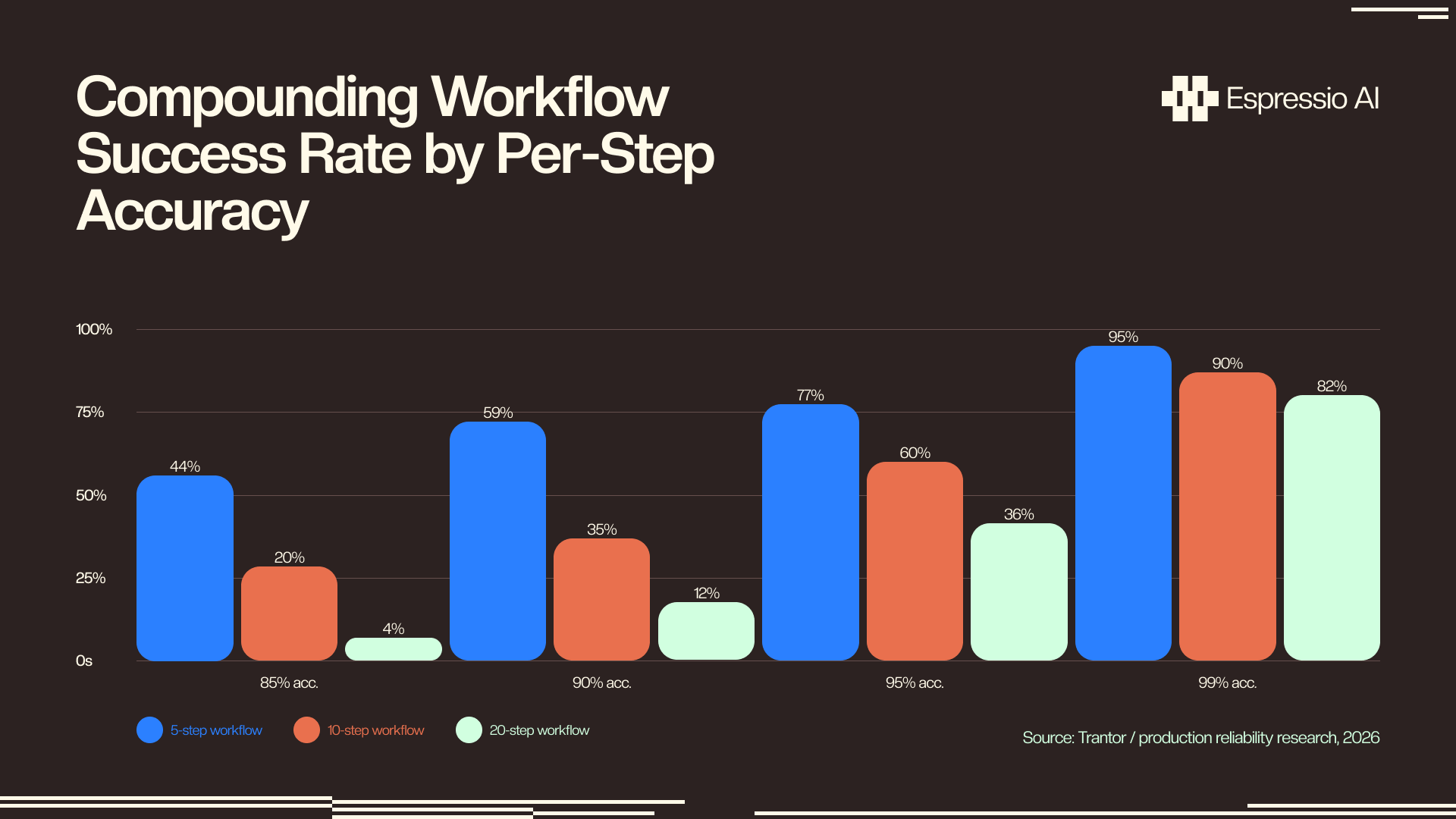
Per-step error compounding is the math problem. If each action in a workflow has 85% accuracy, a 10-step workflow succeeds only about 20% of the time, because you’re multiplying probabilities: 0.85^10 = 0.197. Raise per-step accuracy to 90% and you get 35%. At 95%, you reach 60%. Only at 99% per-step accuracy does a 10-step workflow cross the 90% reliability threshold (Trantor, 2026).
What does that math mean for a 12-step sales proposal agent running at 90% per-step accuracy? Without checkpoints, it produces a usable output only 28% of the time. Four checkpoint-commits at the Plan-Execute-Verify pattern’s natural boundaries raise that to roughly 85%. The architecture is doing the work the model can’t do alone.
The 85%/20% reliability math has existed in production systems research for years, but it’s almost never applied to revenue workflows. A proposal generator that fails three times out of four is working exactly as the laws of probability predict for a 12-step uncheckpointed workflow. Checkpoint architecture is what changes those numbers.
A March 2026 arXiv study (arXiv 2603.29231) measured pass@1 success rates across four task duration bands, finding a 24.3-percentage-point gap between short and long tasks. Separate research from Zylos Research (February 2026) identified the mechanism: 65% of enterprise agent failures stem from context drift and memory loss during multi-step reasoning, not model incapability. Together, these findings define the architectural problem this reference guide addresses.
For a hands-on implementation of the single-agent and fan-out patterns with working code, see the step-by-step implementation tutorial that accompanies this guide.
The six building blocks of Fable 5 long-horizon agents
Claude Fable 5 ships six native capabilities for long-horizon operation: memory tool, task budgets, context compaction, context editing, adaptive thinking, and subagent orchestration (Anthropic, June 2026). In testing on the Slay the Spire benchmark, Fable 5 paired with the memory tool achieved 3× the performance of a baseline run. Which building block matters most for a first deployment? For most teams, it’s the memory tool; everything else compounds on top of it. That gap exists because the model retains which strategies it already tried, not because it reasons faster.
Memory tool
The memory tool gives the agent a persistent file it can read from and write to across turns. Use it to store task state (what phase you’re in, what’s been completed), source URLs that later phases will need, and compact summaries of completed subtasks. Don’t store raw token context, credentials, or intermediate reasoning that isn’t needed downstream. The discipline of deciding what goes to memory and what stays ephemeral is where most teams go wrong initially.
Task budgets
Task budgets (currently in beta via the task-budgets-2026-03-13 beta header) let you set a token budget that the agent can see as it runs. It’s an advisory cap: the model sees the countdown and wraps up gracefully when it approaches the limit. Treat it as a soft ceiling and combine it with max_tokens if you need a firm limit. One common mistake: don’t mutate task_budget.remaining in a cached prompt loop, because you’ll break the cache prefix and pay full input pricing on every turn.
Context compaction and context editing
These are different tools for different problems, and choosing the wrong one is expensive.
Context compaction (the compact-2026-01-12 beta header) triggers server-side summarization when the context approaches a configurable threshold (the default is 150k tokens). Anthropic’s server summarizes the conversation, replaces the full history with the summary, and bills one additional iteration. Use compaction when you’re comfortable losing raw structure in exchange for keeping context small.
Context editing (the context-management-2025-06-27 beta header) gives you direct control over the message history. You can remove completed subtask outputs, stale tool results, and obsolete reasoning without touching the portions you need to keep. Use context editing when you need source URLs, structured data, or raw tool outputs to survive across phases. Compaction will lose those; context editing won’t.
Adaptive thinking (controlled by the effort parameter: low, medium, high, xhigh, max) runs on every Fable 5 call. Set effort: "max" for planning steps that define the entire session structure, then drop to "medium" for execution steps. The max level requires max_tokens ≥ 64000. Subagent orchestration pairs Fable 5 as the orchestrator with Opus 4.8 handling routine subtasks, which cuts per-turn cost without sacrificing reasoning quality on the decisions that matter.
According to Anthropic’s June 2026 announcement, Claude Fable 5 combined with its native memory tool achieves 3× the performance of a baseline run on the Slay the Spire long-horizon benchmark (a game that requires multi-session memory, strategic adaptation, and incremental learning across hours of play). The result demonstrates that the performance ceiling for long-horizon tasks depends on whether the architecture preserves what the model has already learned.
Reference architecture: three production patterns
Three orchestration patterns cover more than 90% of production long-horizon use cases: Plan-Execute-Verify (sequential, checkpoint-heavy), Fan-Out-and-Verify (parallel subagents with synthesis), and RALPH (a verification loop with explicit rollback) (Digital Applied, June 2026). Fan-out achieves 4.4× latency improvement over sequential execution on hard parallelizable problems. Which pattern fits your task depends on whether the work can be parallelized and what reliability floor you need to hit.
Plan-Execute-Verify
The orchestrator uses effort: "high" to plan the full task at session start, producing a structured plan with named phases that it writes to memory. Then it switches to effort: "medium" and executes one phase at a time. After each phase completes, it verifies the output against the plan’s acceptance criteria before writing results to memory and advancing. On failure, it resumes from the last successful checkpoint rather than restarting.
This pattern is right for sequential workflows where phases are interdependent: a research pipeline where analysis depends on data collection, a proposal generator where the executive summary depends on the technical assessment, or a migration that can’t begin cleanup until tests pass.
Fan-Out-and-Verify
The Fable 5 orchestrator decomposes the task and spawns N subagents concurrently, each running on Opus 4.8. Each subagent returns a compact JSON summary with its findings. The orchestrator synthesizes the summaries and runs a verification pass before committing results. The 4.4× latency advantage applies when subtasks are genuinely independent; forced independence on dependent tasks introduces synthesis errors that cost more to fix than the latency saved.
Use Fan-Out-and-Verify for market research (N competitors researched simultaneously), content localization (N languages in parallel), codebase audits (N modules analyzed simultaneously), or competitive intel sweeps where each source is independent.
RALPH pattern
RALPH (Reliability-Augmented LLM for Practical Horizons) adds a dedicated verification agent that reviews each orchestrator output against a structured rubric before any result is committed. The verification agent runs on Fable 5 with effort: "high", assessing completeness, accuracy, format compliance, and source attribution. Outputs that fail the rubric return to the orchestrator for revision rather than proceeding downstream.
RALPH slows throughput roughly 30% versus an unverified loop, but it raises the reliability of critical output fields to near single-step accuracy. When does that tradeoff pay for itself? Whenever a downstream team or system acts on the agent’s results without a human review step: customer-facing outputs, financial calculations, legal summaries, or any workflow where a wrong answer costs more to fix than a 30% slower one.
Fan-out async subagents achieve 4.4× latency improvement over sequential single-agent execution on hard problems with parallelizable components (Digital Applied, June 2026). The tradeoff is synthesis complexity: an orchestrator synthesizing five independent research summaries faces a harder reasoning task than one executing five sequential steps. Budget effort: "high" for the synthesis phase.
For a working multi-agent content pipeline using similar orchestration patterns, see the multi-agent content pipeline patterns that covers researcher, writer, and critic agent coordination.
Context management at scale
Selective memory retrieval cuts per-query token cost by roughly 73% compared to full-context approaches, bringing per-turn input from 26,000 tokens to 6,900 tokens (Mem0, State of AI Agent Memory 2026). For a 24-hour agent running 200 turns, that’s the difference between $480 and $1,920 in input token spend alone, before any caching is applied.
Fable 5 agents work with four distinct memory types, each mapped to a different building block:
The active context window is your working memory: the current turn’s tool calls, reasoning, and intermediate outputs live here. It’s fast and always available, but it’s also where context rot accumulates if you don’t clear completed work.
Episodic memory captures what happened in prior turns and sessions. The memory tool is your primary interface here: write structured summaries after each phase, not raw transcripts. Raw transcripts balloon token counts and confuse the model on re-read.
Semantic memory stores facts the agent will need throughout the session: the task goal, constraints, available tools, and source URLs. This should live in the system prompt and be cached via the prompt caching API. Change it only when the facts change, not on every turn.
Procedural memory stores how to do recurring tasks: the sequence for filing a report, the rubric for evaluating code quality, the template for a competitive summary. Encode this in the system prompt as numbered instructions, not prose guidelines.
How much of your agent’s token spend is going to context you’ve already processed? For most teams, the answer is most of it. Sliding window compression on episodic memory, combined with deduplicated indexing for semantic facts, is the standard approach. The exact savings vary by workload, but teams with context-heavy workflows consistently see their largest cost reduction from cutting re-sent tokens.
Cache-prefix discipline compounds the savings. Structure your context in this order: (1) stable system prompt, (2) project context and semantic memory, (3) episodic summary from memory tool, (4) current turn’s volatile content. Only the last layer changes each turn; the first three hit the cache and cost 10% of standard input pricing.
Selective memory retrieval, which fetches only relevant semantic facts and the most recent episodic summary rather than the full conversation, cuts per-query input tokens from roughly 26,000 to 6,900, a 73% reduction, according to Mem0’s 2026 State of AI Agent Memory report. For teams running agents at scale, this single architectural decision has more impact on monthly costs than any model pricing change.
For an implementation of memory-aware agents with LangGraph’s state management, see how LangGraph marketing agents with memory apply similar retrieval patterns.
Cost modeling for long-horizon runs
Agentic workflows cost 10-100× more than single-call chat interactions, with re-sent context alone accounting for 62% of billing in unoptimized agents — before a single new reasoning step executes (LeanOps, 2026). A 50-step loop running without caching or context pruning costs 30× more than an equivalent single-call approach. At 200 steps, you’re looking at a 100× multiplier.
Cost levers
Four levers control the majority of long-horizon agent costs:
Model-tier routing pairs Fable 5 (for orchestration, planning, and novel reasoning) with Opus 4.8 (for routine subtasks like data extraction, format conversion, templated drafts, and structured lookups). Opus 4.8 costs roughly 80% less per token than Fable 5. On a 200-turn session where 70% of turns are routine subtasks, routing drops the cost by more than half before any other optimization.
Prompt caching applies a 90% discount on stable context (0.1× standard input pricing). Structure your system prompt so the stable portions come first and the volatile per-turn content comes last. The cache prefix must be identical across turns for caching to activate; a single character change breaks it.
Task budgets set an advisory token ceiling the agent can see and respect. Combined with context compaction or editing at defined intervals, they prevent sessions from running unbounded when the agent encounters an unexpectedly large subtask.
A fourth mechanism is per-user budget caps: a hard monthly limit enforced at the application layer, separate from any API-level controls.
Worked example: how much does a 24-hour competitive intel agent actually cost?
Consider a competitive intel agent that monitors 8 market segments across 30 turns per session, running daily. At Fable 5’s standard pricing ($10 per million input tokens, $50 per million output tokens), an unoptimized baseline with no caching and a full context window sent on each turn costs roughly $87,000 per month at scale.
Apply three optimizations:
- Prompt caching on the system prompt and stable project context: saves 85% of re-sent context costs
- Model-tier routing: route data extraction subtasks to Opus 4.8 (70% of turns)
- Context editing every 10 turns: removes completed subtask outputs and stale search results
The result: a 73% cost reduction, bringing monthly spend from $87,000 to roughly $24,000 for the same workload. LeanOps documented this exact optimization pattern with a real SaaS client (LeanOps, 2026). The specific token math breaks down as: re-sent context (pre-optimization) accounts for ~54% of input billing; post-context-editing it drops to ~18%.
Failure recovery patterns and production guardrails
What happens when your agent hits a blocking error on turn 38 of a 50-turn session? Without a recovery architecture, the answer is: you pay for 38 turns and get nothing. With the right defensive layers, it resumes from turn 35’s checkpoint and finishes. Production long-horizon agents need four such layers working together: input validation (scope boundaries defined in the system prompt), checkpoint-resume (write structured state to memory every N turns), circuit breakers (max-turns cap with loop detection), and graceful degradation (explicit handling for each non-standard stop_reason) (Zylos Research, February 2026). Most enterprise agent failures trace back to missing or inadequate context management during multi-step reasoning, making these four layers essential at the infrastructure level.
When we first deployed Espressio’s Competitive Intel agent across a six-hour research session, context rot caused it to re-fetch the same 12 competitor pages in loops three and four. The agent had produced correct source data in phase one but the full outputs were still in context, making phase three’s retrieval logic unreliable. Our initial fix was to enable context compaction at the 120k-token threshold. That stopped the re-fetching, but compaction’s summary lost the raw source URLs that phase four’s citation logic depended on. The actual fix was context editing between phases: we stripped completed subtask outputs while preserving structured URL lists and verified data. Two lines of API code, no further incidents.
Handling stop_reason correctly matters more than most teams expect. The API returns five distinct values:
end_turn: normal completionmax_tokens: the turn was truncated; increasemax_tokensor split the stepstop_sequence: a custom signal your code emitted (e.g.,[TASK COMPLETE])tool_use: the model called a tool and is waiting for resultsrefusal: the request exceeded safety boundaries; surface to human review
Treating max_tokens as end_turn is a frequent source of silent failures. The agent returns a partial output that looks complete, downstream code accepts it, and the error propagates before anyone notices.
The Failure Mode Decision Matrix:
| Symptom | Root Cause | Recovery Action | Prevention Pattern |
|---|---|---|---|
| Agent repeats earlier steps | Context rot: stale outputs in active context | Context editing; resume from last checkpoint | Edit context every 5-10 turns; define phase boundaries |
| Costs exceed budget | Re-sent context compounding | Enable caching on system prompt; route to Opus 4.8 | Task budget header; model-tier routing |
| Agent stops mid-task | max_tokens hit on a long generation | Resume from memory checkpoint; raise max_tokens | Checkpoint every 5 turns; plan for long-output steps |
| Loop detected | Circular tool calls without exit condition | Max-turns circuit breaker | Track last 3 tool calls; exit on repeat pattern |
| Incomplete final output | max_tokens hit on synthesis step | Increase max_tokens; use effort: "high" on synthesis | Reserve token budget for final output generation |
| Task refused | stop_reason: refusal | Escalate to human review; narrow task scope | Input validation in system prompt; scope guardrails |
Here’s a production checkpoint-resume implementation that handles all of these:
import anthropic
import json
from datetime import datetime
client = anthropic.Anthropic()
def run_agent_with_checkpoints(
task: str,
checkpoint_interval: int = 5,
max_turns: int = 50,
) -> dict:
"""Run a long-horizon agent with checkpoint-resume capability."""
state = {
"task": task,
"turn": 0,
"completed_steps": [],
"last_checkpoint": None,
"status": "running",
}
messages = [{"role": "user", "content": task}]
while state["turn"] < max_turns:
state["turn"] += 1
response = client.messages.create(
model="claude-fable-5",
max_tokens=16384,
effort="medium",
system=f"""You are a long-horizon agent. Task: {task}
Completed steps so far:
{json.dumps(state['completed_steps'], indent=2)}
Output [STEP COMPLETE: <step_name>] after finishing each step.
Output [TASK COMPLETE] when the full task is done.
Output [BLOCKED: <reason>] if you cannot continue.""",
messages=messages,
)
output = response.content[0].text if response.content else ""
messages.append({"role": "assistant", "content": output})
# Parse step completion signals
if "[STEP COMPLETE:" in output:
step_name = output.split("[STEP COMPLETE:")[1].split("]")[0].strip()
state["completed_steps"].append({
"step": step_name,
"turn": state["turn"],
"timestamp": datetime.utcnow().isoformat(),
})
# Checkpoint every N turns
if state["turn"] % checkpoint_interval == 0:
state["last_checkpoint"] = state["turn"]
with open("agent_checkpoint.json", "w") as f:
json.dump(state, f)
# Terminal conditions
if response.stop_reason == "refusal":
state["status"] = "refused"
break
if response.stop_reason == "max_tokens":
state["status"] = "truncated"
break
if "[TASK COMPLETE]" in output:
state["status"] = "complete"
break
if "[BLOCKED:" in output:
state["status"] = "blocked"
break
messages.append({"role": "user", "content": "Continue with the next step."})
if state["turn"] >= max_turns:
state["status"] = "max_turns_reached"
return stateFor the full resilient agent loop with tool-use integration and exponential backoff, see the step-by-step implementation tutorial, which covers the complete production pattern including stop_reason handling across all failure modes.
Long-horizon agents for marketing and RevOps teams
Fifty-seven percent of organizations now deploy multi-step agent workflows, and 80% report measurable economic impact (Anthropic State of AI Agents via Arcade, 2026). Marketing and RevOps teams are among the fastest-growing adopters. The architecture described above applies directly, running different tools and system prompts without any custom Python required.
Does your growth team need to write Python to use this architecture? No. Espressio’s implementations use the Anthropic API behind workflow automation tools: Make.com or n8n for session triggers and data routing, Airtable or Notion as the memory store (the agent writes structured JSON rows between phases), and Claude’s native tools for web search and document generation. The Python patterns in this guide describe what’s happening under the hood; the no-code layer is just a wrapper around the same building blocks.
Three Espressio use cases that use this architecture directly:
Content OS runs a six-hour competitive research and brief generation loop. Phase one (Plan): Fable 5 creates a structured research plan for 12 competitors across three dimensions. Phase two (Execute): Opus 4.8 subagents handle each competitor concurrently. Phase three (Verify): Fable 5 synthesizes findings, checks for gaps, and runs a second pass on incomplete data. Phase four (Deliver): Fable 5 drafts content briefs from the verified competitive matrix. Context editing happens between phases one and two (clearing the planning dialogue), and between phases two and three (clearing individual search results, preserving structured data).
RevenueOS handles the meeting transcript-to-proposal pipeline. It’s a 12-step sequential workflow using Plan-Execute-Verify, with checkpoint-commits after transcript parsing, requirements extraction, solution mapping, and draft generation. The checkpoint architecture is the difference between a proposal that sometimes completes and one that reliably delivers.
The Competitive Intel use case is a weekly 8-session monitoring agent, the case study described in the failure recovery section. It was the context rot incident that produced the context editing fix.
The compounding failure math makes a specific, quantified prediction about RevenueOS: a 12-step sales proposal workflow at 90% per-step accuracy produces a usable output only 28% of the time without checkpoints (0.90^12 = 0.282). With Plan-Execute-Verify and four checkpoint-commits at natural phase boundaries, each “segment” becomes a 3-step sub-workflow at 97%+ composite reliability. The end-to-end success rate climbs to roughly 85%. This is the architecture doing the work, not the model getting better.
The METR benchmark tracks the task duration at which frontier AI agents achieve 50% success. In mid-2026 that sits at roughly two hours, doubling every seven months (METR, May 2026). By 2027, a full eight-hour workday is the projected 50%-success horizon. By 2028, a full work week. The architecture in this guide is designed for where that threshold sits today; the building blocks don’t change as the horizon extends, only the session parameters do.
If you’re mapping one of these patterns to your stack, that’s exactly what the Espressio team scopes in a discovery session. We’ve built Content OS, RevenueOS, and Competitive Intel on this architecture across client deployments. let’s chat to walk through your specific workflow.
For the broader AI workflow automation playbook for revenue teams, including integrations with CRM, project management, and data platforms, see AI workflow automation for revenue teams.
Frequently asked questions
What is the current 50%-success time horizon for frontier AI agents?
As of May 2026, frontier AI agents achieve 50% task success on tasks up to roughly two hours long, according to METR’s time-horizons benchmark (METR, May 2026). That horizon doubles approximately every seven months, putting a full eight-hour workday on track for 2027. The architecture you build today is designed for this range and remains valid as the horizon extends.
How do task budgets differ from max_tokens in Claude Fable 5?
max_tokens is a hard limit: the API cuts off the response at that token count and returns stop_reason: max_tokens. Task budgets (via the task-budgets-2026-03-13 beta header) are advisory: the model sees its remaining budget in context and wraps up gracefully before hitting the limit. Use task budgets to get clean completions and max_tokens as a hard safety ceiling. Both should be set; neither replaces the other.
When should I use context compaction instead of context editing?
Use context compaction when you’re comfortable with a server-generated summary replacing the full conversation history, and when you don’t need raw tool outputs or source URLs to survive the transition. Use context editing when your downstream phases depend on specific structured data from earlier phases. Compaction is simpler but lossy. Context editing is surgical but requires you to specify what to remove. For most marketing and RevOps workflows, context editing is the safer default.
How much does a 24-hour Claude Fable 5 agent cost to run?
An unoptimized 24-hour agent (200 turns, full context re-sent each turn, no caching) can cost $400-$800 per session at standard Fable 5 pricing. Apply prompt caching, context editing every 10 turns, and model-tier routing for routine subtasks, and that drops to $50-$120 per session, a 75-85% reduction. LeanOps documented a real client reducing monthly agentic spend from $87,000 to $24,000 using this exact three-optimization pattern (LeanOps, 2026).
What is the biggest single cause of production agent failures?
Context drift and memory loss during multi-step reasoning is the leading cause of enterprise agent failures, according to Zylos Research (February 2026). Agents that perform well on single tasks frequently fail on multi-step workflows because they lose track of what they’ve done, re-process completed work, or contradict earlier outputs. The cause sits in the architecture layer. The fix is architectural: context editing between phases, checkpoint-commits to persistent memory, and structured completion signals the agent emits before moving to the next step.
Next steps
Six building blocks, three patterns, and one math problem you can’t route around: per-step error compounding means that architecture does the reliability work the model can’t do alone. The path from a 28% to an 85% success rate on a 12-step workflow runs through checkpoint-commits, context editing between phases, and a verified synthesis step before any output ships.
The building blocks are already in Fable 5. The patterns are documented here. What’s left is the mapping from these abstractions to your specific workflow, your tools, and your team’s risk tolerance.
- For the code-level implementation of single-agent and fan-out patterns, start with the step-by-step implementation tutorial.
- For multi-agent orchestration patterns with researcher, writer, and critic coordination, see the multi-agent content pipeline guide.
- For AI content agents applied to marketing team workflows, see AI content agents for marketing teams.
- For a CrewAI alternative to the fan-out pattern without the Anthropic API directly, see the CrewAI content research agent tutorial.
If you want us to build this for your team, let’s chat.

